











Em arquiteturas de dados modernas, a velocidade com que as informações são recuperadas muitas vezes determina a usabilidade de uma aplicação. Embora atualizações de hardware e estratégias de cache tenham papéis significativos, a base do desempenho reside na própria estrutura dos dados. Especificamente, o design dos Modelos de Relacionamento de Entidades (ERMs) determina com que eficiência um motor de banco de dados pode percorrer, unir e agrupar dados. Um esquema otimizado não organiza apenas informações; orienta o otimizador de consultas para caminhos de execução mais rápidos. 📉
Este guia explora os mecanismos técnicos por trás do design de esquemas e sua correlação direta com o desempenho de consultas. Analisaremos como os níveis de normalização, a cardinalidade das relações e as estratégias de indexação interagem no plano de execução de consultas. Ao compreender essas dinâmicas, desenvolvedores e arquitetos de bancos de dados podem construir sistemas que escalonam sem comprometer a integridade ou a velocidade.
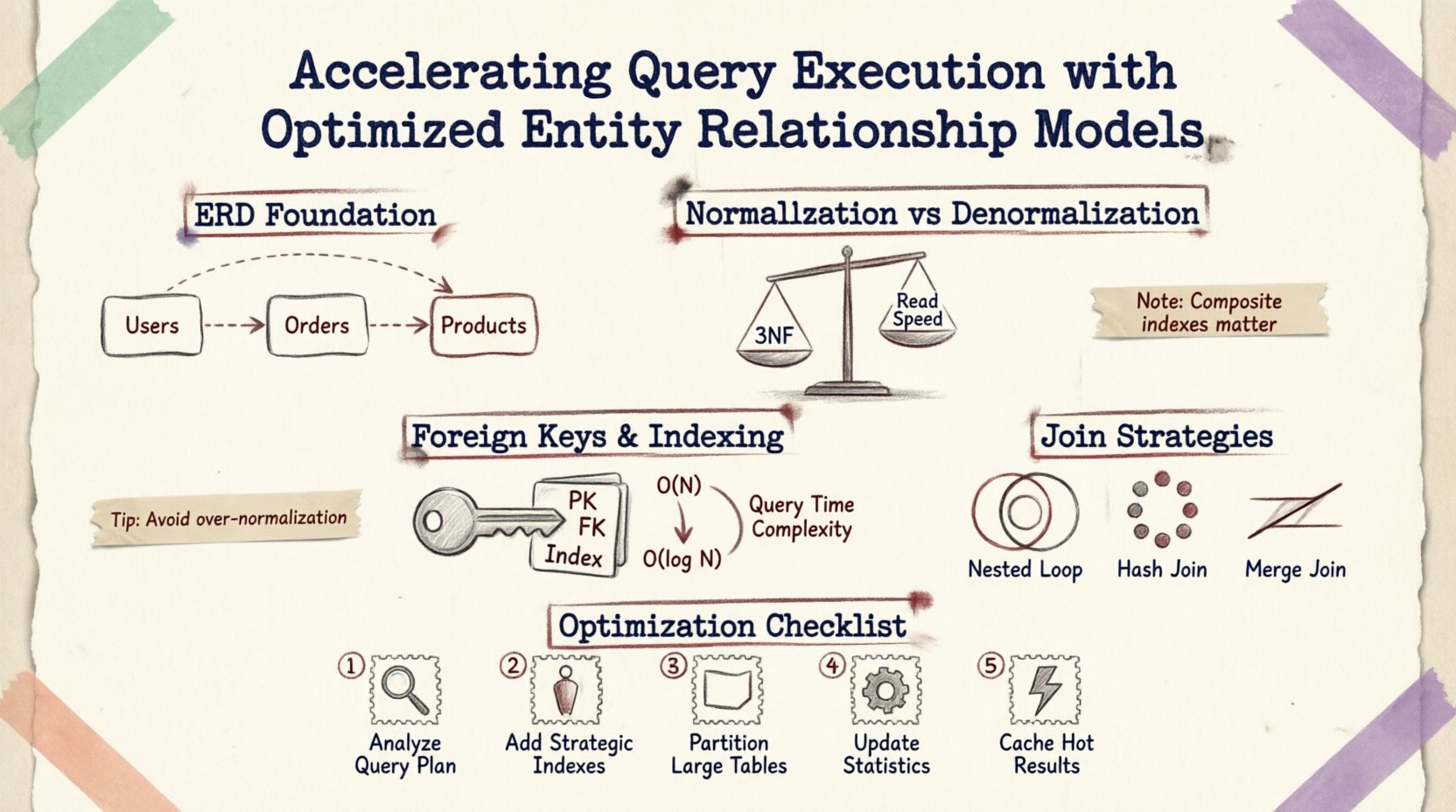
Compreendendo a Fundação: ERDs e Desempenho 🗃️
Um Diagrama de Relacionamento de Entidades é mais do que uma ajuda visual para documentação; é um projeto para a lógica de armazenamento físico e recuperação de dados. Cada linha traçada entre tabelas representa uma restrição de chave estrangeira, uma operação de junção ou uma regra de integridade de dados. Quando uma consulta é enviada, o motor de banco de dados interpreta essas relações para construir um plano de execução.
Considere uma consulta simples que solicita pedidos de usuários e detalhes dos produtos. O motor deve:
- Localizar a tabela
Userstabela. - Seguir a chave estrangeira até a tabela
Orderstabela. - Unir a tabela
OrderItemstabela. - Acessar a tabela
Productstabela por meio de outra relação.
Cada etapa envolve operações de E/S e ciclos de CPU. Se as relações forem mal definidas, o motor pode recorrer a varreduras completas de tabelas ou junções em laço aninhado que degradam o desempenho exponencialmente. Otimizar o ERD reduz a distância que os dados precisam percorrer desde o disco até a memória.
Normalização vs. Denormalização: Encontrando o Equilíbrio ⚖️
A normalização é o processo de organizar dados para reduzir redundâncias e melhorar a integridade. Embora essencial para a consistência, a normalização excessiva pode fragmentar dados em muitas tabelas pequenas, exigindo junções complexas que retardam operações intensivas de leitura.
O Custo da Normalização Profunda
Quando um esquema é normalizado até a Terceira Forma Normal (3FN), os dados são armazenados em seu estado mais atômico. Isso minimiza o espaço de armazenamento e anomalias de atualização. No entanto, recuperar dados relacionados frequentemente exige percorrer múltiplas chaves estrangeiras.
- Custo de Junção: Cada tabela adicional em uma cadeia de junções aumenta a complexidade do plano de consulta.
- Concorrência de Blocos: Acesso a múltiplas tabelas aumenta a probabilidade de conflitos de bloqueio em nível de linha.
- Uso da CPU: O motor de banco de dados deve mesclar conjuntos de resultados de tabelas distintas.
Quando denormalizar
A denormalização introduz redundância para otimizar o desempenho de leitura. Isso muitas vezes é necessário em ambientes de processamento analítico ou relatórios de alto tráfego.
- Cargas de trabalho com leituras intensivas:Se as gravações forem infrequentes em comparação com as leituras, adicionar uma coluna denormalizada economiza operações de junção.
- Agregados pré-calculados:Armazenar totais (por exemplo,
total_order_value) na tabela de usuários evita calcular somas em cada solicitação. - Particionamento horizontal:Manter os dados frequentemente acessados juntos melhora a localidade da cache.
No entanto, a denormalização exige gerenciamento cuidadoso para evitar inconsistência de dados. A lógica da aplicação deve garantir que os dados redundantes sejam atualizados sempre que os dados de origem forem alterados.
Chaves estrangeiras e estratégia de indexação 🔑
As restrições de chave estrangeira garantem a integridade referencial, mas têm um custo de desempenho. O banco de dados deve verificar se um valor em uma tabela existe em outra antes de permitir uma inserção ou atualização. Otimizar como essas chaves são indexadas é fundamental.
Indexação de chaves estrangeiras
Por padrão, as chaves primárias são automaticamente indexadas. As chaves estrangeiras, no entanto, muitas vezes exigem índices explícitos para acelerar operações de junção. Sem um índice na coluna de chave estrangeira:
- O banco de dados deve realizar uma varredura completa da tabela filha para encontrar linhas correspondentes.
- As operações de junção tornam-se significativamente mais lentas, especialmente à medida que os tamanhos das tabelas crescem para milhões de linhas.
- As verificações de integridade referencial durante a exclusão tornam-se caras.
Uma chave estrangeira adequadamente indexada permite que o banco de dados use uma busca de índice em vez de uma varredura, reduzindo a complexidade de O(N) para O(log N).
Índices compostos para relacionamentos
Quando múltiplas colunas definem um relacionamento, um índice composto pode ser mais eficaz do que índices individuais. Por exemplo, se uma consulta filtra por user_id e created_at dentro de uma tabela de pedidos, um índice composto em ambas as colunas garante que o motor possa localizar os dados sem varrer registros irrelevantes.
Estratégias de junção e planos de execução 🔍
A estrutura do ERD influencia quais algoritmos de junção o otimizador de consultas seleciona. Compreender esses mecanismos ajuda a projetar esquemas que favoreçam tipos de junção eficientes.
| Tipo de junção | Melhor utilizado quando | Impacto no desempenho |
|---|---|---|
| Junção em loop aninhado | Pequenos conjuntos de resultados ou predicados altamente seletivos | Rápido para pequenos dados; lento para varreduras grandes |
| Junção por Hash | Tabelas grandes sem índices | Intensivo em memória; bom para dados não ordenados |
| Junção por Mesclagem | Entradas ordenadas nas chaves de junção | Muito rápido se os dados já estiverem ordenados |
Projetar o ERD para suportar entradas ordenadas ou pesquisas indexadas pode incentivar o otimizador a escolher métodos de junção mais rápidos. Por exemplo, garantir que as chaves de junção sejam definidas como parte de um índice agrupado pode facilitar as junções por mesclagem.
Armadilhas Comuns no Projeto de Esquemas 🚫
Mesmo arquitetos experientes cometem erros que afetam a velocidade das consultas. Identificar esses padrões cedo evita reestruturações custosas no futuro.
- Chaves estrangeiras encadeadas:Criar uma cadeia de relacionamentos onde a Tabela A se liga à B, a B se liga à C e a C se liga à D. Consultas que unem as quatro tabelas tornam-se profundamente aninhadas e lentas.
- Strings de comprimento variável:Usando
VARCHARpara chaves que sempre têm comprimento fixo pode desperdiçar espaço e tornar mais lenta a comparação de linhas. - Muitos para muitos sem tabelas de junção:Tentar armazenar múltiplos IDs em uma única coluna (por exemplo, valores separados por vírgula) impede o indexamento adequado e a normalização.
- Conversões Implícitas:Definir tipos de dados que não combinam entre tabelas pai e filha força o motor a converter valores em tempo de execução, impedindo o uso de índices.
Passos Práticos para Otimização 🛠️
Para melhorar a execução de consultas sem reescrever todo o sistema, siga estas etapas estruturadas:
- Analise os Padrões de Consulta:Revise as operações de leitura mais frequentes. Identifique quais tabelas são unidas com mais frequência.
- Revise o Uso de Índices:Verifique a ausência de índices em chaves estrangeiras ou colunas frequentemente filtradas.
- Afinar a Cardinalidade:Garanta que os relacionamentos sejam corretamente modelados (um para um vs. um para muitos). Cardinalidade incorreta pode levar a junções desnecessárias.
- Particione Tabelas Grandes:Se uma tabela ultrapassar milhões de linhas, considere particionar por data ou região para limitar os dados escaneados por consulta.
- Monitoramento de Bloqueios:Use ferramentas de monitoramento para identificar consultas de longa duração que detêm bloqueios, frequentemente causadas por percurso de esquema ineficiente.
Considerações sobre Armazenamento e Memória 💾
A disposição física dos dados também desempenha um papel. Os motores de banco de dados armazenam dados em páginas. Se linhas relacionadas forem armazenadas fisicamente próximas, serão necessárias menos leituras de disco para carregar um conjunto de dados.
- Agrupamento:Organizar os dados por uma chave comum pode melhorar as varreduras de intervalo.
- Armazenamento em Colunas vs. Armazenamento em Linhas:Para consultas analíticas, o armazenamento em colunas pode oferecer melhor compressão e agregação mais rápida do que modelos tradicionais baseados em linhas.
- Cache:Projete esquemas que permitam um cache eficaz de conjuntos de resultados inteiros, em vez de linhas individuais.
Pensamentos Finais sobre a Evolução do Esquema 🔄
O projeto de esquema não é uma tarefa única. À medida que os requisitos da aplicação mudam, o modelo de dados deve evoluir. Auditorias regulares da estrutura do banco de dados garantem que o desempenho permaneça consistente. A documentação do Modelo de Relacionamento de Entidades deve ser mantida junto com o código-fonte para rastrear como as mudanças afetam o sistema.
Ao focar na integridade estrutural e nas relações lógicas dentro dos dados, você cria uma base que suporta a execução de consultas de alta velocidade. O objetivo não é construir um sistema estático, mas uma arquitetura flexível que se adapte à carga sem sacrificar a velocidade esperada pelos usuários. 📊
Otimizar o Modelo de Relacionamento de Entidades é uma disciplina técnica que combina teoria de banco de dados com engenharia prática. Exige paciência, análise e uma compreensão clara de como o motor subjacente processa solicitações. Com a abordagem correta, os problemas de desempenho tornam-se gerenciáveis e a recuperação de dados torna-se contínua.