











Diagramas de Relacionamento de Entidades (ERDs) servem como o projeto arquitetônico para a arquitetura de banco de dados. Eles definem como os dados são estruturados, armazenados e recuperados dentro de um sistema. Quando esses diagramas apresentam falhas, as consequências vão muito além da fase de desenvolvimento. Erros em ambientes de produção podem levar à corrupção de dados, gargalos de desempenho e perdas financeiras significativas. Compreender os erros comuns é essencial para manter a integridade do sistema.
Muitas equipes correm pela fase de modelagem, priorizando velocidade em vez de precisão. Esse apressamento frequentemente resulta em problemas de esquema que são difíceis de resolver assim que os dados começam a fluir. Um design robusto exige consideração cuidadosa sobre relacionamentos, tipos de dados e restrições. A seguir, exploramos as falhas de design mais comuns e suas implicações técnicas.
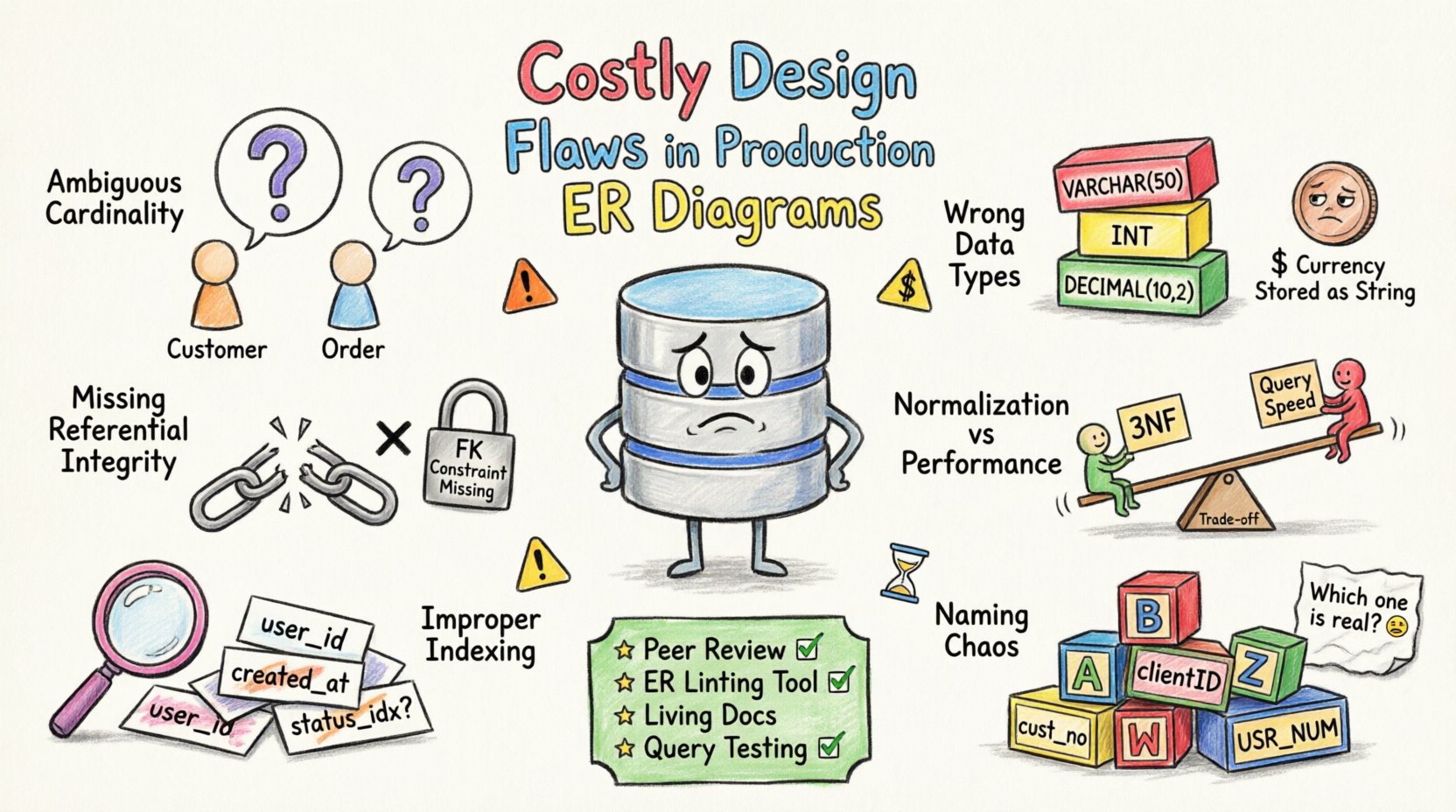
1. Cardinalidade e Relacionamentos Ambíguos 🔗
A cardinalidade define a relação numérica entre entidades. A cardinalidade incorreta leva a erros lógicos na recuperação e armazenamento de dados. Um erro comum é assumir uma relação um para um quando na verdade existe uma relação um para muitos.
- Omissão de Relacionamento Muitos para Muitos:Não criar uma tabela de junção para relacionamentos muitos para muitos força a duplicação de dados ou consultas de junção complexas.
- Chaves Estrangeiras Não Definidas:Sem chaves estrangeiras explícitas, o banco de dados não consegue garantir a integridade referencial, permitindo registros órfãos.
- Opcional vs. Obrigatório:Classificar incorretamente uma relação obrigatória como opcional introduz valores nulos onde se espera dados.
Por exemplo, considere um cliente e um pedido. Se o diagrama implica que um cliente pode existir sem um pedido, mas a lógica da aplicação o exige, o banco de dados armazenará perfis incompletos. Essa discrepância causa travamentos da aplicação ou relatórios inconsistentes.
2. Seleção Inconsistente de Tipos de Dados 📊
Os tipos de dados determinam como as informações são armazenadas e processadas. Selecionar o tipo errado consome armazenamento desnecessário ou limita a faixa de valores. Problemas de precisão surgem frequentemente quando números de ponto flutuante são usados para valores monetários.
- Estouro de Inteiro:Usar inteiros pequenos para identificadores pode levar a erros de estouro à medida que o conjunto de dados cresce.
- Comprimento de Texto:Usar campos de caracteres de comprimento fixo desperdiça espaço para dados de comprimento variável.
- Precisão de Data:Armazenar datas sem fuso horário cria problemas de sincronização em sistemas distribuídos.
Escolher um campo de texto genérico para números de telefone é outro erro frequente. Isso permite que caracteres inválidos entrem no sistema, complicando a lógica de validação posteriormente. Campos numéricos devem ser usados para cálculos, e campos de texto apenas para dados alfanuméricos.
3. Falta de Restrições de Integridade Referencial 🔒
A integridade referencial garante que as relações entre tabelas permaneçam consistentes. Sem essas restrições, o banco de dados depende do código da aplicação para manter a precisão dos dados, o que é propenso a erros humanos.
- Sem Regras de Cascata:Excluir um registro pai sem regras de cascata deixa registros filhos pendurados no banco de dados.
- Restrições Ausentes:Contar com a validação em nível de aplicação em vez de restrições do banco de dados é insuficiente.
- Exclusão Suave:O tratamento inadequado de registros excluídos cria bagunça e reduz o desempenho das consultas.
Quando as restrições estão ausentes, a integridade dos dados depende inteiramente dos desenvolvedores da aplicação. Se um erro permitir uma gravação direta no banco de dados, as inconsistências tornam-se permanentes. Esse é um dos principais motivos da corrupção de dados em sistemas de produção de longa duração.
4. Normalização vs. Compromissos de Desempenho ⚖️
A normalização reduz a redundância, mas pode aumentar a complexidade das consultas. A sobre-normalização leva a junções excessivas, enquanto a sub-normalização cria anomalias de atualização. Encontrar o equilíbrio é crítico para o desempenho.
- Terceira Forma Normal (3FN):Freqüentemente ideal para sistemas transacionais, mas pode exigir desnormalização para cargas de trabalho com leitura intensiva.
- Desnormalização:Introduzir redundância para melhorar o desempenho deve ser documentado para evitar conflitos de atualização.
- Complexidade de Consulta:Esquemas profundamente normalizados exigem junções complexas que sobrecarregam o motor do banco de dados.
Equipes frequentemente normalizam ao extremo para garantir a pureza dos dados, ignorando o custo de unir múltiplas tabelas. Em ambientes com alta carga, isso resulta em tempos de resposta lentos. A desnormalização estratégica pode melhorar o desempenho de leitura, desde que as operações de escrita sejam gerenciadas corretamente.
5. Estratégia de Indexação Improprada 🏷️
Índices aceleram a recuperação de dados, mas retardam as operações de escrita. Um ERD defeituoso frequentemente não leva em conta como os dados serão consultados. Isso leva a varreduras completas de tabelas e alta latência.
- Índices de Chave Estrangeira Ausentes:Junções em colunas não indexadas são computacionalmente custosas.
- Sobre-Indexação:Demasiados índices aumentam a latência de escrita e os requisitos de armazenamento.
- Ordem de Índices Compostos:A ordem incorreta de colunas em índices compostos os torna ineficazes.
Um índice em uma coluna frequentemente consultada é uma prática padrão. No entanto, ignorar os padrões de consulta durante a fase de design leva a caminhos de acesso ineficientes. É necessário revisar regularmente os planos de execução de consultas para ajustar as estratégias de indexação.
6. Caos nas Convenções de Nomeação 🏷️
Convenções de nomeação consistentes são vitais para a manutenibilidade. Nomes de tabelas e colunas inconsistentes tornam o esquema difícil de entender e modificar.
- Case Misto:Usar camelCase em alguns lugares e snake_case em outros gera confusão.
- Abreviações Ambíguas:Nomes curtos como “cust” ou “ord” carecem de clareza para membros novos da equipe.
- Palavras Reservadas:Usar palavras reservadas como nomes de tabelas causa erros de sintaxe em consultas.
Nomes claros reduzem a carga cognitiva sobre desenvolvedores e administradores de banco de dados. Também facilita a geração automatizada de documentação e reduz a probabilidade de erros de digitação em instruções SQL.
Análise de Impacto dos Erros Comuns
| Falha no Design | Impacto Técnico | Custo Empresarial |
|---|---|---|
| Chaves Estrangeiras Ausentes | Registros órfãos, inconsistência de dados | Perda de dados, violações de conformidade |
| Tipos de Dados Incorretos | Perda de armazenamento, erros de cálculo | Discrepâncias financeiras, erros de relatórios |
| Sobrenormalização | Desempenho lento de consultas, alta latência | Experiência lenta do usuário, perda de receita |
| Índices Ausentes | Escaneamentos completos de tabela, contenção de bloqueio no banco de dados | Tempo de inatividade do sistema, escala pobre |
| Nomenclatura Ruim | Alto custo de manutenção, taxas de erro | Tempo de desenvolvimento aumentado, bugs |
Estratégias de Prevenção 🛡️
Prevenir essas falhas exige uma abordagem disciplinada no design de banco de dados. Os seguintes passos ajudam a mitigar riscos antes da implantação.
- Revisões por Pares: Realize revisões obrigatórias do esquema antes de qualquer alteração ser mesclada.
- Linting Automatizado: Use ferramentas para verificar convenções de nomeação e padrões estruturais.
- Documentação: Mantenha diagramas ERD atualizados que reflitam o esquema real.
- Testes: Execute testes de validação de esquema no ambiente de homologação antes da produção.
Adotar um processo de controle de versão para esquemas de banco de dados garante que as alterações sejam rastreadas e reversíveis. Isso permite que as equipes identifiquem quando uma falha foi introduzida e revertam, se necessário. A colaboração entre desenvolvedores e arquitetos é essencial para detectar problemas cedo.
Considerações de Manutenção de Longo Prazo 🔄
Os esquemas de banco de dados evoluem ao longo do tempo. Um design que funciona hoje pode não atender a requisitos futuros. Auditorias regulares ajudam a identificar dívida técnica e padrões desatualizados.
- Desvio de Esquema: Monitore as diferenças entre o ERD e o banco de dados em produção.
- Obsolescência: Planeje a remoção de tabelas e colunas não utilizadas.
- Escalabilidade: Projete levando em conta particionamento e sharding para grandes conjuntos de dados.
Ignorar a manutenção leva a um sistema frágil que resiste às mudanças. A gestão proativa garante que o banco de dados permaneça uma base confiável para o aplicativo. Investir tempo no projeto inicial traz benefícios ao longo de toda a vida útil do software.
Pensamentos Finais sobre a Integridade do Esquema 📝
Erros no banco de dados de produção muitas vezes são resultado de detalhes negligenciados na fase de projeto. Ao abordar cardinalidade, tipos de dados, restrições e indexação, as equipes podem construir sistemas mais resilientes. O custo de corrigir uma falha em produção é significativamente maior do que preveni-la durante o modelo.
Concentre-se em clareza, consistência e validação. Um ERD bem estruturado é a base da confiabilidade dos dados. Priorize qualidade em vez de velocidade para garantir estabilidade de longo prazo. Essa abordagem minimiza riscos e maximiza o valor dos dados armazenados no sistema.