











Projetar esquemas de banco de dados robustos exige um profundo entendimento de como as entidades de dados interagem. Entre as estruturas mais complexas de gerenciar estão os relacionamentos muitos para muitos. Esses cenários ocorrem quando uma única instância de uma entidade está associada a múltiplas instâncias de outra, e vice-versa. Sem um planejamento adequado, essas conexões podem levar a redundância de dados, problemas de integridade e gargalos de desempenho significativos. Este guia explora a mecânica da otimização desses relacionamentos dentro de Modelos de Relacionamento de Entidades (ERMs) para garantir sistemas escalonáveis e mantíveis.
Compreendendo o Desafio Central 🔍
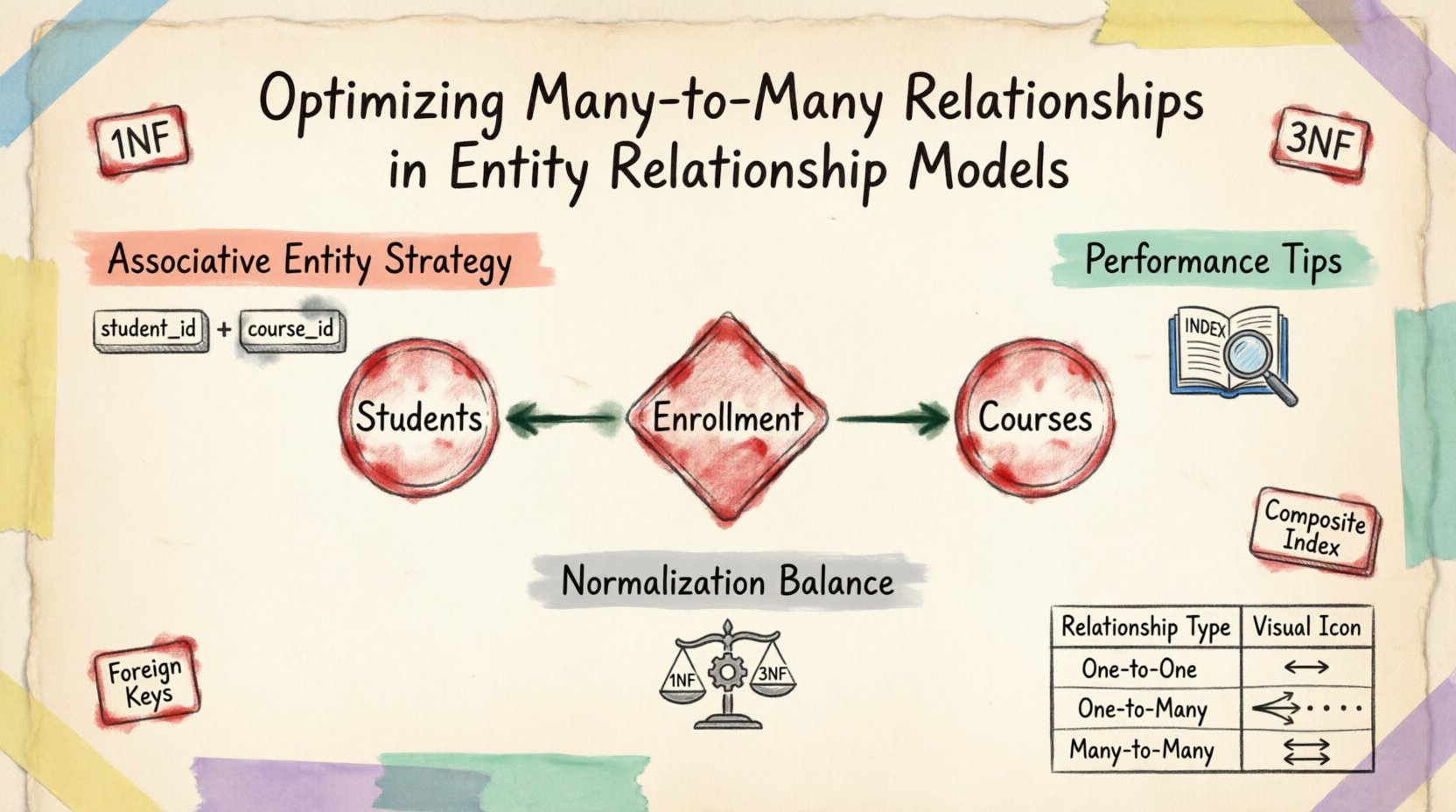
Em um modelo conceitual, um relacionamento muitos para muitos é intuitivo. Pense em alunos e cursos. Um aluno se inscreve em múltiplos cursos, e cada curso tem múltiplos alunos. Representar isso diretamente em uma estrutura física de banco de dados é problemático. Tabelas relacionais padrão suportam relacionamentos um para muitos e um para um nativamente por meio de chaves estrangeiras. Um relacionamento muitos para muitos exige uma estrutura intermediária para funcionar corretamente.
Tentar armazenar múltiplos IDs em uma única coluna (por exemplo, uma lista separada por vírgulas) viola a Primeira Forma Normal (1FN). Essa abordagem torna a consulta, indexação e manutenção da integridade dos dados quase impossíveis. A solução reside em dividir o relacionamento em dois relacionamentos um para muitos por meio de uma entidade associativa, frequentemente chamada de tabela de junção ou tabela de ponte.
A Estratégia da Entidade Associativa 🧩
A técnica fundamental para resolver relacionamentos muitos para muitos é a introdução de uma entidade associativa. Essa entidade atua como uma ponte entre as duas tabelas pais. Ela contém chaves primárias de ambas as entidades pais como chaves estrangeiras, criando uma chave primária composta que garante a unicidade para cada instância de relacionamento.
- Estrutura: A tabela inclui chaves estrangeiras que referenciam as chaves primárias das entidades relacionadas.
- Unicidade: Uma chave composta evita relacionamentos duplicados entre os mesmos dois registros.
- Atributos: Essa tabela pode armazenar dados específicos sobre o próprio relacionamento, e não apenas sobre as entidades.
Considere um cenário que liga Funcionários e Projetos. Um funcionário trabalha em muitos projetos, e um projeto tem muitos funcionários. A tabela de relacionamento pode armazenar a data da atribuição, o cargo do funcionário nesse projeto ou as horas alocadas. Esses atributos pertencem ao relacionamento, e não ao funcionário ou ao projeto individualmente.
Etapas de Implementação
- Identifique as Entidades: Defina as duas entidades distintas envolvidas no relacionamento.
- Crie a Tabela de Junção: Gere uma nova tabela com um nome descritivo, como
Atribuições_Empregado_Projeto. - Adicione Chaves Estrangeiras: Insira colunas para as chaves primárias de ambas as entidades pais.
- Defina Restrições: Configure restrições de chave estrangeira para garantir a integridade referencial.
- Indexação: Aplique índices às colunas de chave estrangeira para acelerar operações de junção.
Normalização e Integridade de Dados 🛡️
A otimização frequentemente envolve um compromisso entre normalização e desempenho. Embora a normalização reduza a redundância, estruturas excessivamente normalizadas podem exigir junções complexas que atrasam as consultas. Ao otimizar relacionamentos muitos para muitos, é crucial equilibrar esses fatores.
A Terceira Forma Normal (3FN) é geralmente o objetivo para bancos de dados operacionais. Nesse estado, a tabela de junção não deve conter dependências transitivas. Todo atributo não-chave deve depender da chave primária. Se uma tabela de junção contiver dados que dependem apenas de uma das chaves estrangeiras, ela deve ser movida para a tabela pai correspondente.
Armadilhas Comuns na Normalização
- Chaves Estrangeiras Redundantes:Incluindo a mesma chave estrangeira em várias tabelas de junção sem uma hierarquia clara.
- Restrições Ausentes:Falha em impor restrições únicas na combinação de chaves estrangeiras.
- Exclusão Suave:Não levar em conta os registros excluídos na tabela de relacionamento, resultando em dados órfãos.
Estratégias de Otimização de Desempenho ⚡
À medida que o volume de dados cresce, o número de linhas em uma tabela de junção pode aumentar exponencialmente. Isso afeta diretamente os tempos de execução de consultas. Várias estratégias podem mitigar a degradação do desempenho.
1. Indexação Estratégica
Índices são críticos para o desempenho de junções. Um índice composto nas colunas de chaves estrangeiras é frequentemente mais eficaz do que índices individuais. Isso permite que o motor de banco de dados localize linhas relacionadas mais rapidamente sem escanear toda a tabela.
- Índices Agrupados:Em alguns sistemas, agrupar a tabela pela chave composta pode melhorar as consultas de intervalo.
- Índices Cobertores:Incluir colunas frequentemente consultadas no índice pode eliminar a necessidade de acessar o heap da tabela.
2. Particionamento
Quando uma tabela de junção se torna muito grande para ser gerenciada de forma eficiente, o particionamento por data ou região pode distribuir a carga. Isso é particularmente útil para dados históricos, onde relacionamentos recentes são acessados com mais frequência do que os antigos.
3. Otimização de Consultas
Consultas complexas que envolvem múltiplas junções podem sobrecarregar os recursos. Usar dicas de consulta ou reestruturar o SQL para minimizar subconsultas pode ajudar. Também é importante analisar o plano de execução para identificar gargalos.
| Estratégia | Benefício | Compromisso |
|---|---|---|
| Indexação Composta | Recuperação de junção mais rápida | Aumento do armazenamento e sobrecarga de gravação |
| Particionamento de Tabela | Melhoria na manutenção e na velocidade de varredura | Complexidade na lógica de consulta |
| Cache | Carga reduzida no banco de dados | Riscos de consistência de dados |
Manipulação de Atributos de Relacionamento 📝
Uma das maiores vantagens da entidade associativa é a capacidade de armazenar atributos específicos para a relação. Por exemplo, em um sistema de gestão de contratos, um Fornecedor e um Produto têm uma relação muitos para muitos. Os atributos podem incluir o preço unitário, a data de início do contrato e a quantidade acordada.
Se você tentar armazenar esses atributos na tabela de Fornecedor ou Produto, você cria redundância. Se o preço mudar, você teria que atualizar várias linhas na tabela de produtos. Ao colocá-los na tabela de junção, você mantém uma única fonte de verdade para essa instância específica de relação.
Cenários Avançados e Casos Especiais 🌐
O modelagem de dados do mundo real frequentemente apresenta desafios únicos que os padrões padrão não cobrem imediatamente.
- Relacionamentos Auto-Referenciados: Uma entidade relacionada a si mesma (por exemplo, um Funcionário gerenciando outros Funcionários). Isso exige uma chave estrangeira que aponte para a chave primária da mesma tabela.
- Exclusão em Cascata: Decidir se a exclusão de uma entidade pai deve remover automaticamente seus registros de relacionamento. Isso evita chaves estrangeiras órfãs, mas pode perder dados históricos de associação.
- Relacionamentos Recursivos: Hierarquias complexas em que a tabela de junção aponta de volta para si mesma.
Consulta do Esquema Otimizado 🔎
Uma vez que o esquema é otimizado, consultá-lo exige precisão. Os desenvolvedores devem entender como o motor do banco de dados percorre os caminhos de junção.
Ao recuperar dados, como todos os projetos para um funcionário específico, a consulta deve unir a tabela de Funcionário com a tabela de Junção e, em seguida, com a tabela de Projetos. A escrita eficiente de SQL garante que o banco de dados utilize corretamente os índices disponíveis. Evitar funções em colunas indexadas na cláusulaWHEREé uma prática padrão para manter a utilização de índices.
Melhores Práticas para a Lógica de Junção
- Use Junções Explícitas: Prefira
INNER JOINouLEFT JOINem vez de tabelas implícitas separadas por vírgulas. - Limite as Colunas: Selecione apenas as colunas necessárias para reduzir a transferência de rede e o tempo de processamento.
- Filtre cedo: Aplicar filtros na cláusula
WHEREantes da junção ocorrer, se possível.
Comparando Tipos de Relacionamento 📊
Compreender onde o relacionamento muitos para muitos se encaixa no contexto mais amplo da modelagem de dados ajuda a tomar decisões de design melhores.
| Tipo de Relacionamento | Estrutura | Exemplo de Caso de Uso |
|---|---|---|
| Um para Um | Chave Estrangeira Única | Perfil do Usuário e Configurações do Usuário |
| Um para Muitos | Chave Estrangeira Única | Pedido e Itens do Pedido |
| Muitos para Muitos | Tabela de Junção | Alunos e Cursos |
Mantendo a Consistência dos Dados 🔄
Garantir que os dados permaneçam consistentes entre as tabelas relacionadas é fundamental. Isso frequentemente envolve o gerenciamento de transações. Uma transação deve envolver a inserção de dados na tabela principal e na tabela de junção. Se qualquer etapa falhar, toda a operação deve ser revertida para evitar estados parciais de dados.
Gatilhos também podem ser utilizados para impor lógica de negócios, embora devam ser usados com parcimônia para evitar custos ocultos de desempenho. Por exemplo, um gatilho poderia impedir que um funcionário fosse atribuído a um projeto se seu departamento não corresponder ao departamento do projeto.
Monitoramento e Manutenção 📈
Uma vez implantado, o sistema exige monitoramento contínuo. O crescimento na tabela de junção é frequentemente o primeiro sinal de problemas de escalabilidade. Auditorias regulares do tamanho das tabelas, fragmentação de índices e métricas de desempenho de consultas são necessárias.
- Arquivamento: Mover dados históricos de relacionamento para armazenamento frio se eles já não forem consultados ativamente.
- Reindexação: Reconstituir ou reorganizar periodicamente os índices para manter um desempenho ótimo.
- Revisão de Junções: Garantir que alterações na aplicação não introduzam padrões de consulta ineficientes.
Pensamentos Finais sobre o Design de Esquema 🎯
Otimizar relacionamentos muitos para muitos não é uma tarefa pontual, mas um processo contínuo de aprimoramento. Exige um equilíbrio entre correção teórica e desempenho prático. Ao seguir os princípios de normalização, utilizar entidades associativas e aplicar indexação estratégica, arquitetos de bancos de dados podem construir sistemas que sejam tanto robustos quanto eficientes. O objetivo é criar uma estrutura que suporte a lógica de negócios sem impor restrições desnecessárias à recuperação ou modificação de dados.