











दृढ़ डेटाबेस स्कीमा डिज़ाइन करने के लिए डेटा एंटिटीज़ के बीच बातचीत के गहन ज्ञान की आवश्यकता होती है। प्रबंधन के लिए सबसे जटिल संरचनाओं में से एक बहु-से-बहु संबंध हैं। ये परिस्थितियाँ तब होती हैं जब एक एंटिटी का एक उदाहरण दूसरी एंटिटी के कई उदाहरणों से जुड़ता है, और विपरीत भी। उचित योजना के बिना, इन जुड़ावों के कारण डेटा अतिरेक, अखंडता की समस्याएं और महत्वपूर्ण प्रदर्शन की अवरोधक बन सकती हैं। यह मार्गदर्शिका एंटिटी रिलेशनशिप मॉडल्स (ERMs) के भीतर इन संबंधों को अनुकूलित करने के तकनीकों का अध्ययन करती है, ताकि स्केलेबल और बनाए रखने योग्य प्रणालियाँ सुनिश्चित की जा सकें।
मूल चुनौती को समझना 🔍
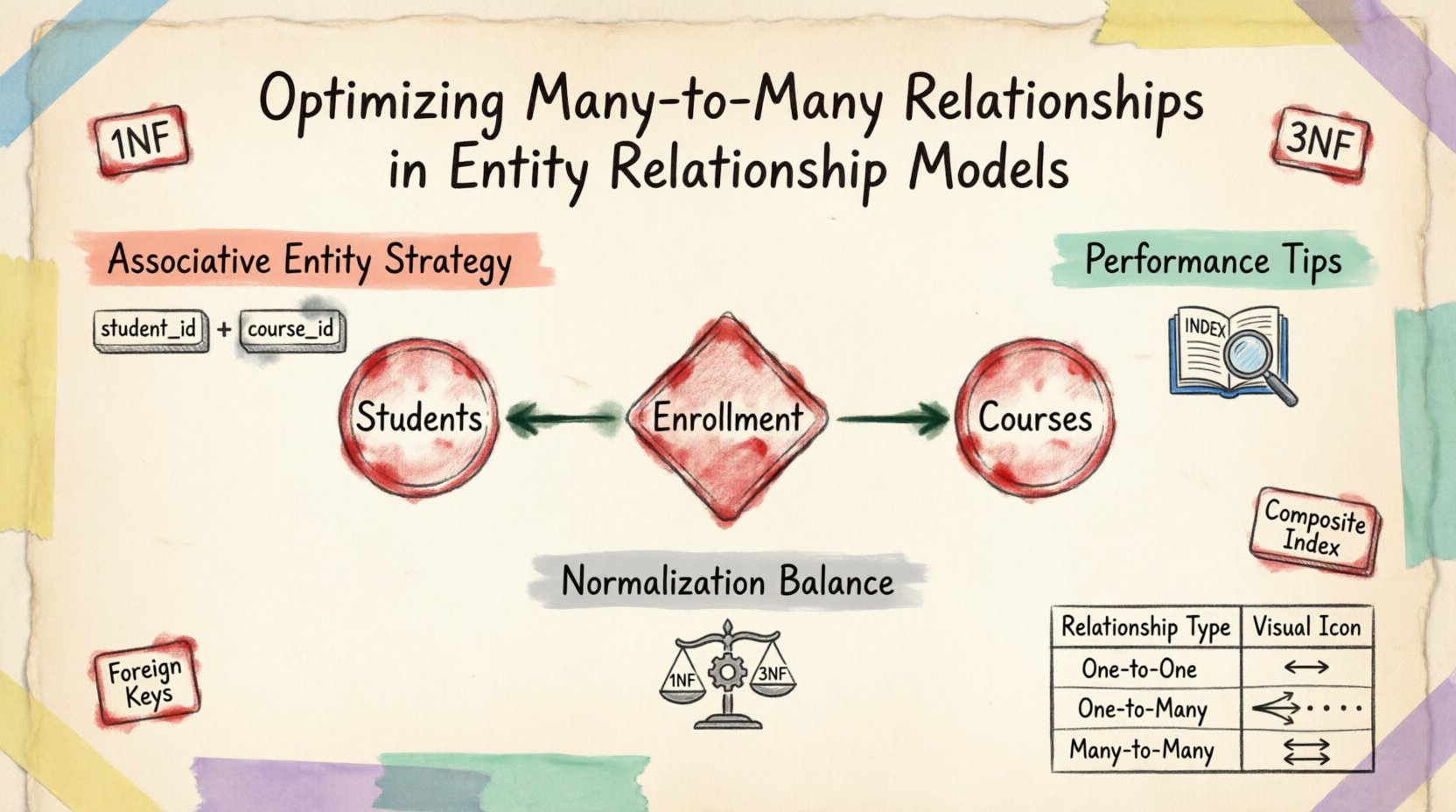
एक संकल्पनात्मक मॉडल में, बहु-से-बहु संबंध स्पष्ट है। छात्रों और कोर्सेज़ के बारे में सोचें। एक छात्र बहुत से कोर्सेज़ में दाखिला लेता है, और प्रत्येक कोर्स में बहुत से छात्र होते हैं। इसे एक भौतिक डेटाबेस संरचना में सीधे प्रस्तुत करना समस्यापूर्ण है। मानक संबंधात्मक तालिकाएं विदेशी कुंजियों के माध्यम से एक-से-बहु और एक-से-एक संबंधों का समर्थन निष्पक्ष रूप से करती हैं। बहु-से-बहु संबंध के सही कार्यान्वयन के लिए एक मध्यस्थ संरचना की आवश्यकता होती है।
एक ही कॉलम में कई पहचान संख्याओं को संग्रहीत करने की कोशिश (उदाहरण के लिए, कोमा से अलग किए गए सूची) प्रथम सामान्य रूप (1NF) के उल्लंघन करती है। इस दृष्टिकोण के कारण प्रश्न पूछना, सूचीकरण और डेटा अखंडता बनाए रखना लगभग असंभव हो जाता है। समाधान एक सहयोगी एंटिटी के माध्यम से संबंध को दो एक-से-बहु संबंधों में तोड़ने में निहित है, जिसे अक्सर जंक्शन टेबल या ब्रिज टेबल कहा जाता है।
सहयोगी एंटिटी रणनीति 🧩
बहु-से-बहु संबंधों को हल करने की मूल तकनीक सहयोगी एंटिटी के परिचय है। यह एंटिटी दो मुख्य तालिकाओं के बीच एक पुल के रूप में कार्य करती है। इसमें दोनों मुख्य एंटिटीज़ की प्राथमिक कुंजियाँ विदेशी कुंजियों के रूप में शामिल होती हैं, जिससे एक संयुक्त प्राथमिक कुंजी बनती है, जो प्रत्येक संबंध के उदाहरण के लिए अद्वितीयता सुनिश्चित करती है।
- संरचना: तालिका में संबंधित एंटिटीज़ की प्राथमिक कुंजियों के संदर्भ में विदेशी कुंजियाँ शामिल होती हैं।
- अद्वितीयता: एक संयुक्त कुंजी समान दो रिकॉर्ड्स के बीच दोहराए गए संबंधों को रोकती है।
- गुण: यह तालिका संबंध के बारे में विशिष्ट डेटा संग्रहीत कर सकती है, केवल एंटिटीज़ के बारे में नहीं।
कर्मचारियों और प्रोजेक्ट्स को जोड़ने वाले एक परिदृश्य को ध्यान में रखें। एक कर्मचारी बहुत से प्रोजेक्ट्स पर काम करता है, और एक प्रोजेक्ट में बहुत से कर्मचारी होते हैं। संबंध तालिका में नियुक्ति तिथि, कर्मचारी की उस प्रोजेक्ट में भूमिका या आवंटित घंटे संग्रहीत कर सकती है। इन गुणों का संबंध संबंध से है, न कि कर्मचारी या प्रोजेक्ट के व्यक्तिगत रूप से।
कार्यान्वयन चरण
- एंटिटीज़ पहचानें: संबंध में शामिल दो अलग-अलग एंटिटीज़ को परिभाषित करें।
- जंक्शन टेबल बनाएँ: एक वर्णनात्मक नाम वाली नई तालिका बनाएँ, उदाहरण के लिए
कर्मचारी_प्रोजेक्ट_नियुक्तियाँ. - विदेशी कुंजियाँ जोड़ें: दोनों मुख्य एंटिटीज़ की प्राथमिक कुंजियों के लिए कॉलम जोड़ें।
- प्रतिबंध परिभाषित करें: संदर्भात्मक अखंडता सुनिश्चित करने के लिए विदेशी कुंजी प्रतिबंध सेट करें।
- सूचीकरण: जॉइन ऑपरेशन को तेज करने के लिए विदेशी कुंजी कॉलम पर सूचीकरण लागू करें।
नॉर्मलाइजेशन और डेटा अखंडता 🛡️
अनुकूलन में नॉर्मलाइजेशन और प्रदर्शन के बीच एक व्यापार करना आम है। जबकि नॉर्मलाइजेशन अतिरेक को कम करता है, अत्यधिक नॉर्मलाइज्ड संरचनाएं जटिल जॉइन की आवश्यकता बना सकती हैं, जो प्रश्नों को धीमा कर देती हैं। बहु-से-बहु संबंधों को अनुकूलित करते समय इन कारकों के बीच संतुलन बनाए रखना महत्वपूर्ण है।
तृतीय सामान्य रूप (3NF) सामान्यतः संचालनात्मक डेटाबेस का लक्ष्य होता है। इस स्थिति में, जंक्शन टेबल में स्थानांतरण निर्भरता नहीं होनी चाहिए। प्रत्येक गैर-कुंजी विशेषता को प्राथमिक कुंजी पर निर्भर होना चाहिए। यदि एक जंक्शन टेबल में विशेषता है जो केवल एक विदेशी कुंजी पर निर्भर है, तो उसे संबंधित मुख्य तालिका में स्थानांतरित करना चाहिए।
सामान्य नॉर्मलाइजेशन के बाधाएं
- आवश्यकता से अधिक विदेशी कुंजियां:एक ही विदेशी कुंजी को स्पष्ट विरासत के बिना कई जंक्शन तालिकाओं में शामिल करना।
- अनुपस्थित सीमाएं:विदेशी कुंजियों के संयोजन पर अद्वितीय सीमाओं को लागू करने में विफलता।
- मृदु डिलीट्स:संबंध तालिका में हटाए गए रिकॉर्ड्स को ध्यान में न रखना, जिससे अनाथ डेटा बनता है।
प्रदर्शन अनुकूलन रणनीतियां ⚡
जैसे-जैसे डेटा का आयतन बढ़ता है, जंक्शन तालिका में पंक्तियों की संख्या घातीय रूप से बढ़ सकती है। इसका सीधा प्रभाव प्रश्न निष्पादन समय पर पड़ता है। कई रणनीतियां प्रदर्शन में गिरावट को कम कर सकती हैं।
1. रणनीतिक सूचीकरण
सूचियां जॉइन प्रदर्शन के लिए महत्वपूर्ण हैं। विदेशी कुंजी के कॉलम पर एक संयुक्त सूची अक्सर अलग-अलग सूचियों की तुलना में अधिक प्रभावी होती है। इससे डेटाबेस इंजन को पूरी तालिका को स्कैन किए बिना संबंधित पंक्तियों को तेजी से ढूंढने में सक्षम होता है।
- क्लस्टर्ड सूचियां:कुछ प्रणालियों में, संयुक्त कुंजी द्वारा तालिका को क्लस्टर करने से रेंज प्रश्नों में सुधार होता है।
- कवरिंग सूचियां:अक्सर प्रश्न किए जाने वाले कॉलम को सूची में शामिल करने से तालिका हीप तक पहुंचने की आवश्यकता समाप्त हो जाती है।
2. विभाजन
जब एक जंक्शन तालिका प्रबंधन के लिए बहुत बड़ी हो जाती है, तो तारीख या क्षेत्र के आधार पर विभाजन करने से लोड वितरित होता है। यह ऐतिहासिक डेटा के लिए विशेष रूप से उपयोगी है, जहां हाल के संबंध अधिक बार उपयोग किए जाते हैं बजाय पुराने संबंधों के।
3. प्रश्न अनुकूलन
एक से अधिक जॉइन वाले जटिल प्रश्न संसाधनों पर दबाव डाल सकते हैं। प्रश्न हिंट्स का उपयोग करना या SQL को उपप्रश्नों को कम करने के लिए पुनर्गठित करना मदद कर सकता है। बॉटलनेक को पहचानने के लिए निष्पादन योजना का विश्लेषण करना भी महत्वपूर्ण है।
| रणनीति | लाभ | व्यापार लाभ |
|---|---|---|
| संयुक्त सूचीकरण | तेजी से जॉइन प्राप्त करना | बढ़ी हुई स्टोरेज और लेखन ओवरहेड |
| तालिका विभाजन | सुधारा गया रखरखाव और स्कैन गति | प्रश्न तर्क में जटिलता |
| कैशिंग | कम डेटाबेस लोड | डेटा सुसंगतता के जोखिम |
संबंध विशेषताओं का प्रबंधन 📝
सहयोगी एकता के सबसे बड़े लाभों में से एक यह है कि संबंध के लिए विशिष्ट विशेषताओं को संग्रहीत करने की क्षमता। उदाहरण के लिए, एक अनुबंध प्रबंधन प्रणाली में, एक विक्रेता और एक उत्पाद के बीच बहुत-से-बहुत संबंध होता है। विशेषताओं में इकाई मूल्य, अनुबंध की शुरुआत की तारीख और सहमत मात्रा शामिल हो सकती है।
यदि आप इन विशेषताओं को विक्रेता या उत्पाद तालिका में संग्रहीत करने की कोशिश करते हैं, तो आप अतिरेक बना देते हैं। यदि मूल्य बदलता है, तो आपको उत्पाद तालिका में बहुत सारी पंक्तियों को अपडेट करना होगा। इन्हें संयोजन तालिका में रखकर, आप उस विशिष्ट संबंध के लिए एकमात्र सत्य स्रोत को बनाए रखते हैं।
उन्नत परिदृश्य और किनारे के मामले 🌐
वास्तविक दुनिया के डेटा मॉडलिंग में अक्सर ऐसी विशिष्ट चुनौतियाँ आती हैं जिन्हें मानक पैटर्न तुरंत कवर नहीं करते।
- स्वयं-संदर्भित संबंध: एक ऐसी एकता जो स्वयं से संबंधित होती है (उदाहरण के लिए, एक कर्मचारी जो अन्य कर्मचारियों को प्रबंधित करता है)। इसके लिए एक विदेशी कुंजी की आवश्यकता होती है जो उसी तालिका की प्राथमिक कुंजी की ओर इशारा करती है।
- कैस्केडिंग हटाना: यह तय करना कि क्या एक माता-पिता एकता को हटाने के बाद उसके संबंध रिकॉर्ड को स्वचालित रूप से हटाना चाहिए। इससे अनाथ विदेशी कुंजियों से बचा जा सकता है, लेकिन ऐतिहासिक संबंध डेटा को खोने का खतरा हो सकता है।
- पुनरावृत्त संबंध: जटिल विरासत जहां संयोजन तालिका स्वयं की ओर इशारा करती है।
अनुकूलित स्कीमा का प्रश्न करना 🔎
जब स्कीमा अनुकूलित हो जाता है, तो इसके प्रश्न करने के लिए सटीकता की आवश्यकता होती है। डेवलपर्स को समझना चाहिए कि डेटाबेस इंजन जॉइन पथ को कैसे तय करता है।
जब डेटा प्राप्त करने के लिए, जैसे कि एक विशिष्ट कर्मचारी के सभी प्रोजेक्ट, प्रश्न को कर्मचारी तालिका को संयोजन तालिका से जोड़ना चाहिए, और फिर प्रोजेक्ट तालिका से। कुशल SQL लेखन सुनिश्चित करता है कि डेटाबेस उपलब्ध इंडेक्स का सही तरीके से उपयोग करता है। इंडेक्स किए गए कॉलम पर फ़ंक्शन का उपयोग बचाना एक मानक व्यवहार है ताकि इंडेक्स का उपयोग बना रहे।जहांक्लॉज एक मानक व्यवहार है ताकि इंडेक्स का उपयोग बना रहे।
जॉइन तर्क के लिए सर्वोत्तम प्रथाएं
- स्पष्ट जॉइन का उपयोग करें: प्राथमिकता दें
आंतरिक जॉइनयाबाएं जॉइनअप्रत्यक्ष अल्पविराम से अलग तालिकाओं के बजाय। - कॉलम सीमित करें: केवल आवश्यक कॉलम का चयन करें ताकि नेटवर्क स्थानांतरण और प्रसंस्करण समय कम किया जा सके।
- जल्दी फ़िल्टर करें: जहां क्लॉज में फ़िल्टर लगाएं यदि संभव हो तो जॉइन से पहले।
जहांक्लॉज में जॉइन होने से पहले यदि संभव हो तो फ़िल्टर लगाएं।
संबंध प्रकारों की तुलना 📊
डेटा मॉडलिंग के व्यापक संदर्भ में बहु-से-बहु संबंध कहाँ फिट होता है, इसकी समझ बेहतर डिज़ाइन निर्णय लेने में मदद करती है।
| संबंध प्रकार | संरचना | उपयोग केस उदाहरण |
|---|---|---|
| एक-से-एक | एकल विदेशी कुंजी | उपयोगकर्ता प्रोफ़ाइल और उपयोगकर्ता सेटिंग्स |
| एक-से-बहु | एकल विदेशी कुंजी | आदेश और आदेश आइटम |
| बहु-से-बहु | संयोजन तालिका | छात्र और कोर्स |
डेटा सुसंगतता बनाए रखना 🔄
संबंधित तालिकाओं में डेटा की सुसंगतता बनाए रखना अत्यंत महत्वपूर्ण है। इसमें अक्सर लेनदेन प्रबंधन शामिल होता है। एक लेनदेन को मुख्य तालिका और संयोजन तालिका में डेटा के इन्सर्ट को घेरना चाहिए। यदि कोई भी चरण विफल होता है, तो पूरी ऑपरेशन को वापस ले जाना चाहिए ताकि आ частично डेटा स्थिति न बने।
ट्रिगर्स का उपयोग व्यावसायिक तर्क को लागू करने के लिए भी किया जा सकता है, हालांकि छिपी प्रदर्शन लागत से बचने के लिए इनका संतुलित उपयोग करना चाहिए। उदाहरण के लिए, एक ट्रिगर एक कर्मचारी को किसी प्रोजेक्ट में नियुक्त करने से रोक सकता है यदि उनका विभाग प्रोजेक्ट के विभाग से मेल नहीं खाता है।
निगरानी और रखरखाव 📈
जब तक डेप्लॉय कर दिया जाता है, तो प्रणाली को निरंतर निगरानी की आवश्यकता होती है। संयोजन तालिका में वृद्धि अक्सर स्केलिंग समस्याओं का पहला संकेत होती है। तालिका आकारों, इंडेक्स टूटने और प्रश्न प्रदर्शन मापदंडों की नियमित समीक्षा की आवश्यकता होती है।
- आर्काइविंग:यदि ऐतिहासिक संबंध डेटा को अब सक्रिय रूप से प्रश्न नहीं किया जा रहा है, तो इसे कोल्ड स्टोरेज में स्थानांतरित करें।
- पुनः इंडेक्सिंग:नियमित रूप से इंडेक्स को पुनर्निर्माण या पुनर्व्यवस्थित करें ताकि अनुकूल प्रदर्शन बना रहे।
- जॉइन्स की समीक्षा:यह सुनिश्चित करें कि एप्लिकेशन बदलाव अक्षम प्रश्न पैटर्न को न लाए।
स्कीमा डिज़ाइन पर अंतिम विचार 🎯
बहु-से-बहु संबंधों को अनुकूलित करना एक बार का कार्य नहीं है, बल्कि सुधार की निरंतर प्रक्रिया है। इसमें सैद्धांतिक सहीता और व्यावहारिक प्रदर्शन के बीच संतुलन बनाए रखने की आवश्यकता होती है। नॉर्मलाइजेशन सिद्धांतों का पालन करने, सहयोगी एंटिटीज का उपयोग करने और रणनीतिक इंडेक्सिंग लागू करने से डेटाबेस वार्ड ऐसी प्रणालियाँ बना सकते हैं जो दोनों बलवान और कुशल हों। लक्ष्य यह है कि एक संरचना बनाई जाए जो व्यावसायिक तर्क का समर्थन करे बिना डेटा प्राप्त करने या संशोधित करने में अनावश्यक बाधाएँ डाले।