











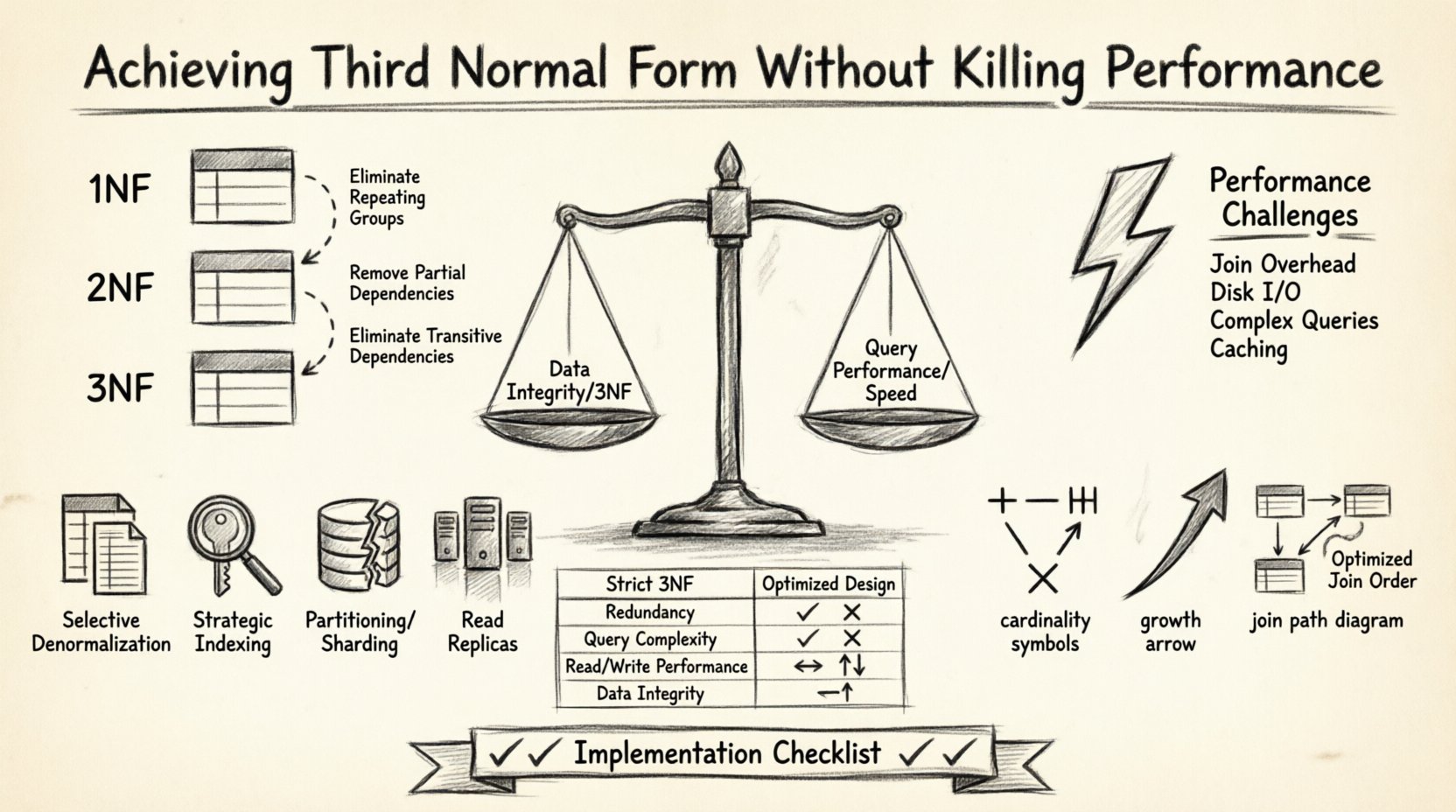
Projetar uma estrutura de banco de dados robusta é um equilíbrio. De um lado, temos a integridade dos dados e a eliminação de redundâncias por meio da normalização. Do outro, temos a velocidade das consultas e a responsividade do sistema. Muitos arquitetos de bancos de dados enfrentam uma escolha difícil: seguir rigorosamente as regras de normalização e correr o risco de consultas lentas, ou denormalizar de forma agressiva e correr o risco de inconsistências nos dados. O objetivo é encontrar um ponto intermediário em que o banco de dados siga a Terceira Forma Normal (3FN) mantendo um alto desempenho. Este artigo explora como estruturar Diagramas de Relacionamento de Entidades (ERD) para alcançar esse equilíbrio sem comprometer nem a integridade nem a velocidade.
Compreendendo a Terceira Forma Normal 🧩
A Terceira Forma Normal é um nível específico de normalização de bancos de dados. Antes de atingir a 3FN, uma tabela deve primeiro atender à Primeira Forma Normal (1FN) e à Segunda Forma Normal (2FN). O princípio central da 3FN é que todos os atributos devem depender apenas da chave primária. Não deve haver dependências transitivas.
- Primeira Forma Normal: Elimina grupos repetidos e garante valores atômicos.
- Segunda Forma Normal: Remove dependências parciais em que atributos não-chave dependem apenas de parte de uma chave composta.
- Terceira Forma Normal: Remove dependências transitivas. Se A determina B, e B determina C, então C não deve depender diretamente de A na mesma tabela.
Quando você atinge a 3FN, minimiza anomalias de atualização. São erros que ocorrem quando os dados são alterados em um local, mas não em outros, levando a inconsistências. Por exemplo, se o endereço de um cliente for armazenado tanto na tabela Pedidos quanto na tabela Clientes quanto na tabela, alterar o endereço em uma tabela, mas não na outra, cria uma discrepância. A 3FN obriga você a armazenar esse endereço em um único local apenas.
A Compromisso de Desempenho ⚡
Embora a 3FN seja excelente para a integridade dos dados, frequentemente vem com um custo para o desempenho. Bancos de dados normalizados geralmente exigem mais tabelas. Para recuperar um conjunto de dados completo, o motor do banco de dados deve realizar múltiplos joins. Cada operação de join exige que o sistema leia dados do disco ou da memória, corresponda chaves e combine os resultados.
Considere uma consulta de relatório que precise de nomes de clientes, detalhes de pedidos, descrições de produtos e endereços de entrega. Em um design 3FN totalmente normalizado, isso pode envolver a junção de cinco ou mais tabelas. Se o volume de dados for grande, esses joins podem se tornar um gargalo.
Abaixo estão os desafios específicos de desempenho associados à 3FN:
- Aumento da sobrecarga de junções: Cada relacionamento exige uma operação de junção durante consultas de leitura.
- E/S de disco: Espalhar os dados em muitas tabelas aumenta o número de páginas que o motor do banco de dados deve acessar.
- Lógica de consulta complexa: As aplicações devem construir instruções SQL mais complexas para buscar dados relacionados.
- Complexidade de cache: Armazenar em cache uma única linha denormalizada é mais simples do que armazenar em cache múltiplas linhas relacionadas.
Estratégias para Equilibrar Integridade e Velocidade 🚀
Você não precisa abandonar a normalização para melhorar o desempenho. Existem técnicas específicas para otimizar um banco de dados 3FN mantendo a estrutura intacta. As seguintes estratégias ajudam a manter a qualidade dos dados sem sacrificar a velocidade.
1. Denormalização Seletiva
Nem toda tabela precisa ser estritamente 3FN. Identifique as tabelas com alta carga de leitura e os caminhos críticos de dados. Você pode introduzir redundância controlada nessas áreas específicas. Por exemplo, armazene o nome de um cliente diretamente na Pedidostabela. Embora isso duplique dados, o ganho de desempenho para pesquisas de pedidos é significativo. Você então deve implementar um gatilho ou lógica de aplicação para manter esta cópia atualizada quando o registro do cliente for alterado.
2. Indexação Estratégica
Índices são a ferramenta principal para acelerar junções. Sem índices, um banco de dados realiza uma varredura completa da tabela para cada condição de junção. Com indexação adequada, as pesquisas tornam-se quase instantâneas.
- Índices de Chave Estrangeira: Sempre indexe as colunas usadas em relacionamentos de chave estrangeira. Isso garante que a junção de tabelas seja rápida.
- Índices Compostos: Crie índices em múltiplas colunas se suas consultas filtrarem frequentemente por essa combinação.
- Índices Cobertores: Projete índices que incluam todas as colunas necessárias para uma consulta específica. Isso permite que o banco de dados atenda à consulta usando apenas o índice, evitando uma pesquisa nos dados principais da tabela.
3. Particionamento e Sharding
Se o conjunto de dados crescer demais, dividir as tabelas pode melhorar o desempenho. O particionamento divide uma tabela grande em pedaços físicos menores e mais gerenciáveis com base em uma chave, como data ou região. O sharding distribui os dados entre várias instâncias de banco de dados. Ambos os métodos reduzem a quantidade de dados que o motor precisa varrer para responder a uma consulta específica.
4. Réplicas de Leitura
Separe suas operações de escrita das operações de leitura. Use uma instância primária de banco de dados para transações e atualizações. Repita esses dados em uma ou mais réplicas somente leitura. Consultas complexas de relatórios que sobrecarregam o sistema podem ser executadas nas réplicas, mantendo o sistema principal rápido para interações com os usuários.
Considerações de Projeto de ERD 📐
Ao desenhar um Diagrama de Relacionamento de Entidades, a representação visual influencia como os desenvolvedores escrevem consultas. Um ERD claro ajuda a identificar relacionamentos cedo. No entanto, um diagrama que parece perfeito no papel pode se desempenhar mal em produção. Aqui está como abordar o projeto de ERD para desempenho.
- Identifique a Cardinalidade Claramente: Certifique-se de que cada relacionamento tenha uma cardinalidade definida (um-para-um, um-para-muitos, muitos-para-muitos). Relacionamentos ambíguos levam a junções ineficientes.
- Planeje para o Crescimento: Antecipe o volume futuro de dados. Um projeto que funciona com 10.000 linhas pode falhar com 10 milhões de linhas.
- Revise os Caminhos de Junção: Trace os caminhos que uma consulta comum percorrerá pelo diagrama. Se um caminho for muito longo, considere adicionar uma coluna desnormalizada.
- Documente Restrições: Documente explicitamente quais restrições são impostas pelo banco de dados e quais são tratadas pela camada de aplicação.
Comparação: Projeto Normalizado vs. Projeto Otimizado 📊
A tabela abaixo ilustra as diferenças entre uma abordagem estrita de 3FN e uma abordagem otimizada para um cenário específico.
| Funcionalidade | Projeto Estrito de 3FN | Projeto Otimizado |
|---|---|---|
| Redundância | Mínima | Controlada e limitada |
| Complexidade da Consulta | Alta (Múltiplos Joins) | Moderada (Menos Joins) |
| Desempenho de Escrita | Rápido (Menos Dados) | Variável (Gatilhos de Atualização) |
| Desempenho de Leitura | Mais lento (I/O do Disco) | Mais rápido (Dados em Cache) |
| Integridade dos Dados | Alta | Alta (com Validação) |
Quando quebrar as regras 🛑
Existem cenários válidos em que a 3FN rígida deve ser postergada. Compreender quando desviar é crucial para arquitetos de banco de dados.
- Relatórios e Análise:Armazéns de dados frequentemente usam um esquema estrela em vez da 3NF. O objetivo aqui é a velocidade de leitura para análise, e não a integridade transacional.
- Sistemas Transacionais de Alta Taxa de Transferência: Se o sistema manipula milhões de escritas por segundo, joins complexos podem causar contenção de bloqueios. Simplificar o esquema pode reduzir a sobrecarga de bloqueios.
- Sistemas Legados: Se estiver migrando de um sistema antigo, pode ser mais rápido desnormalizar temporariamente enquanto reconstrói a camada de aplicação.
- Aplicações com Leitura Intensa: Se o seu aplicativo lê dados 100 vezes para cada escrita, o custo de manter a consistência da 3NF supera os benefícios.
Checklist de Implementação ✅
Antes de implantar seu esquema de banco de dados, percorra esta checklist para garantir que você tenha um equilíbrio entre desempenho e normalização.
- Analise os Padrões de Consulta: Identifique as consultas de leitura mais frequentes. Elas exigem muitos joins?
- Meça o Desempenho Atual: Estabeleça uma base para o seu sistema. Conheça a latência atual das consultas críticas.
- Revise o uso de índices: Verifique se os índices estão sendo utilizados ou se estão causando sobrecarga durante gravações.
- Teste a carga de gravação: Certifique-se de que qualquer estratégia de desnormalização não desacelere muito as operações de gravação.
- Planeje a sincronização de dados: Se você duplicar dados, como manterá a sincronização? Defina o mecanismo.
- Monitore anomalias: Configure alertas para inconsistências de dados se você estiver usando desnormalização parcial.
Pensamentos finais sobre a arquitetura de banco de dados 🏗️
Alcançar a Terceira Forma Normal sem comprometer o desempenho exige uma abordagem sutil. Não é uma escolha binária entre velocidade e integridade. Ao compreender o custo das junções, utilizar índices de forma eficaz e aplicar desnormalização seletiva quando apropriado, é possível construir sistemas que sejam confiáveis e rápidos. O melhor design de banco de dados é aquele que se alinha com a carga de trabalho específica da aplicação. Revise regularmente seu ERD e o desempenho das consultas conforme o sistema cresce. A adaptação é essencial para o sucesso a longo prazo na gestão de dados.