











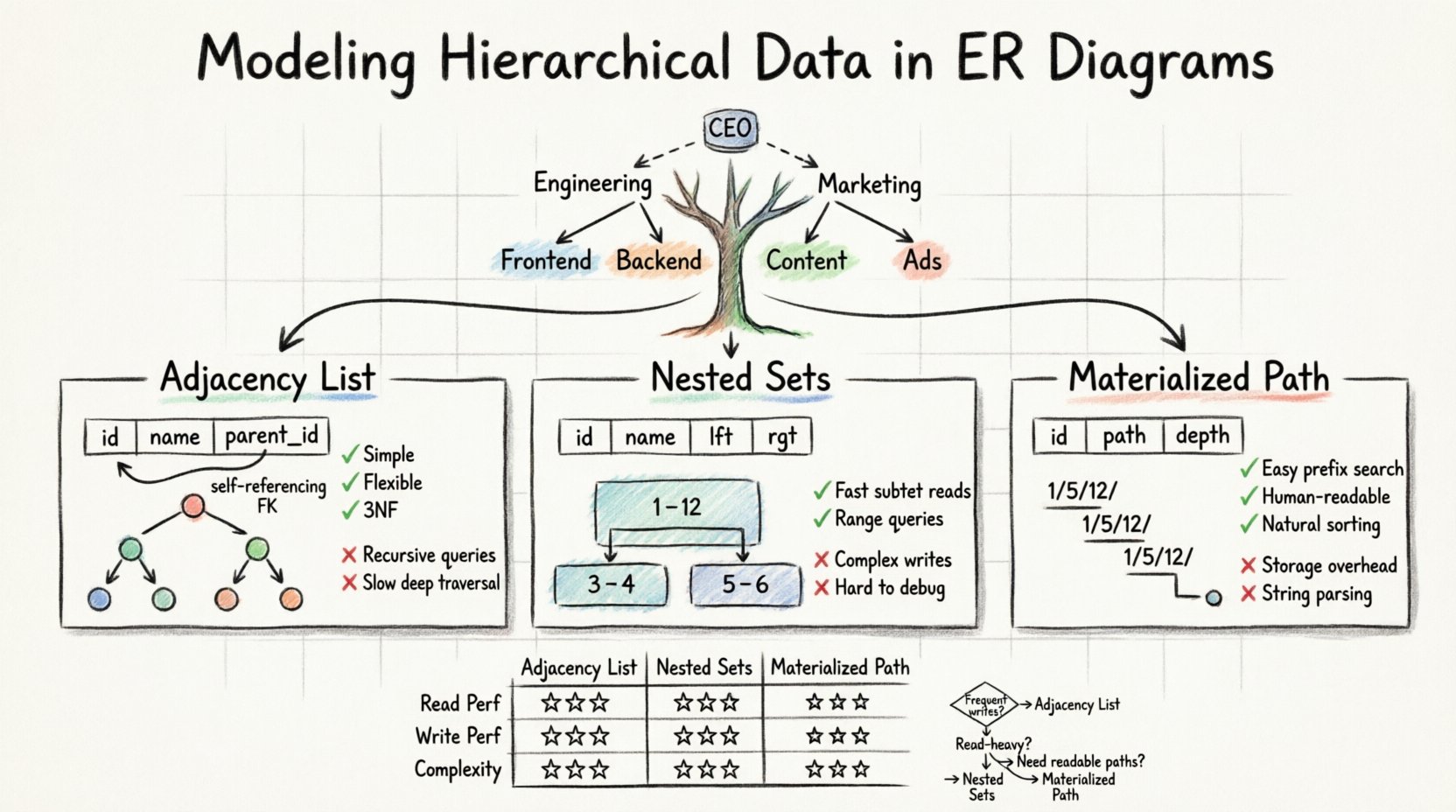
Bancos de dados relacionais são construídos sobre a base de tabelas e linhas, uma estrutura projetada para dados planos. No entanto, o mundo real raramente segue essa simplicidade. Organizações, sistemas de arquivos, fóruns de comentários e árvores de categorias todas existem em estruturas hierárquicas. Representar essas relações pai-filho em um Diagrama Padrão de Entidade-Relacionamento (ERD) exige padrões de design específicos que preservam a integridade dos dados ao mesmo tempo em que permitem recuperação eficiente.
Quando você tenta mapear uma estrutura de árvore em um esquema plano, enfrenta a tensão clássica entre normalização e desempenho. Este guia explora as técnicas principais para modelar dados hierárquicos, avaliando os custos de cada abordagem para ajudá-lo a projetar sistemas robustos.
🧩 O Desafio dos Esquemas Planos
Um Diagrama de Entidade-Relacionamento geralmente visualiza entidades como caixas e relacionamentos como linhas. Em um relacionamento padrão, uma tabela se liga a outra por meio de uma Chave Estrangeira. Isso funciona perfeitamente em cenários muitos-para-muitos ou um-para-muitos, onde a direção é fixa. Mas o que acontece quando uma categoria pode ter subcategorias, que por sua vez podem ter sub-subcategorias, potencialmente infinitamente?
Modelos relacionais padrão têm dificuldade com profundidade variável. Uma tabela plana não consegue armazenar facilmente um caminho de comprimento arbitrário. Para resolver isso, devemos adaptar o esquema para armazenar a hierarquia explicitamente. Existem três padrões principais utilizados por arquitetos de dados para alcançar isso:
- Lista de Adjacência: Armazenando o ID do pai dentro do registro do filho.
- Conjuntos Aninhados: Atribuindo valores esquerda e direita para definir intervalos.
- Enumeração de Caminhos: Armazenando o caminho completo desde a raiz até o nó atual.
🔗 O Modelo de Lista de Adjacência
A Lista de Adjacência é o método mais comum e direto para representar hierarquias em um ERD padrão. Ela depende de uma relação auto-referenciada. Isso significa que uma única tabela contém uma coluna que faz referência à própria chave primária.
📐 Estrutura do Esquema
Neste modelo, você cria uma única tabela para armazenar os dados. Cada linha representa um nó na árvore. A adição fundamental é uma coluna, frequentemente nomeada parent_id ou ancestor_id, que armazena o identificador único do nó pai. Se um nó estiver no topo da hierarquia, essa coluna conterá um valor nulo.
Considere uma tabela para Departamento:
- id: A chave primária única para o departamento.
- nome: O nome exibido do departamento.
- parent_id: O ID do departamento superior (pode ser nulo para o nível superior).
✅ Vantagens
- Simplicidade: O esquema é intuitivo e fácil de entender para desenvolvedores e administradores de banco de dados.
- Flexibilidade: Mover uma subárvore é simples; você precisa apenas atualizar o
parent_iddo nó raiz dessa subárvore. - Normalização: Ele se adapta bem à Terceira Forma Normal (3NF), pois os dados não são repetidos.
❌ Desvantagens
- Complexidade de Consulta: Recuperar todos os descendentes exige consultas recursivas ou processamento do lado do aplicativo.
- Desempenho: Percursos profundos podem ser lentos sem estratégias específicas de indexação ou expressões comuns de tabela recursivas (CTEs).
- Integridade Referencial: Embora chaves estrangeiras ajudem, referências circulares ainda podem ocorrer se as restrições não forem estritamente aplicadas.
🌲 O Modelo de Conjunto Aninhado
O modelo de Conjunto Aninhado transforma a estrutura de árvore em um conjunto de intervalos. Em vez de rastrear ponteiros para o pai, cada nó é atribuído a dois números: esquerda e direita. Esses valores representam a posição do nó em uma travessia em pré-ordem da árvore.
📐 Estrutura do Esquema
Imagine uma árvore onde o nó raiz é o conjunto inteiro. À medida que você percorre a árvore, incrementa um contador. Quando você entra em um nó, registra o valor atual do contador como esquerda. Quando você terminar de processar esse nó e todos os seus filhos, registra o contador como direita. O direita o valor é sempre maior que o esquerda valor.
Uma Categoria tabela teria este aspecto:
- id: Identificador único.
- nome: Nome da categoria.
- esq: O valor da fronteira esquerda.
- dir: O valor da fronteira direita.
✅ Vantagens
- Recuperação Rápida: Buscar uma subárvore é uma consulta simples de intervalo usando
ENTRElógica. - Eficiência: O desempenho de leitura é superior para árvores grandes e profundas em comparação com listas de adjacência.
❌ Desvantagens
- Custo de Escrita: Inserir ou mover um nó é caro. Você deve atualizar os valores de
esqedirdos muitos outros nós para manter a integridade dos intervalos. - Complexidade: A lógica é difícil de implementar e depurar sem suporte de biblioteca dedicada.
🛣️ Enumeração de Caminhos e Caminhos Materializados
Os métodos de enumeração de caminhos armazenam a linhagem de um nó como uma string ou uma lista delimitada. Essa abordagem é frequentemente chamada de padrão de Caminho Materializado. Ela combina a simplicidade da lista de adjacência com a legibilidade do caminho.
📐 Estrutura do Esquema
Neste modelo, cada registro armazena o caminho completo desde a raiz. Por exemplo, em um modelo de sistema de arquivos, um arquivo pode ter uma string de caminho como/home/user/documents/report.txt. Em um banco de dados, isso geralmente é armazenado como uma string delimitada dentro da coluna, como1/5/12/.
A tabela inclui:
- id: Chave primária.
- caminho: Uma string que representa a linhagem.
- profundidade: Um inteiro que indica até quantos níveis profundo o nó está.
✅ Vantagens
- Navegação Fácil: Você pode encontrar todos os descendentes correspondendo ao prefixo do caminho.
- Legibilidade: Os dados são legíveis por humanos e fáceis de depurar.
- Ordenação: Ordenar pela string do caminho geralmente resulta na ordem correta da árvore de forma natural.
❌ Desvantagens
- Custo de Armazenamento: Caminhos longos podem consumir espaço de armazenamento significativo.
- Análise de String: As consultas frequentemente exigem funções de manipulação de string, que podem ser mais lentas que comparações inteiras.
📊 Análise Comparativa
Escolher o modelo certo depende muito da relação entre leitura e escrita e da profundidade da sua hierarquia. A tabela a seguir descreve as características de cada método.
| Funcionalidade | Lista de Adjacência | Conjuntos Aninhados | Caminho Materializado |
|---|---|---|---|
| Desempenho de Leitura | Baixo a Médio | Alta | Médio a Alto |
| Desempenho de Escrita | Alta | Baixa | Média |
| Complexidade de Implementação | Baixa | Alta | Média |
| Suporta Árvores Profundas | Sim | Sim | Sim (com limites) |
| Lógica de Consulta | Recursiva | Varredura de Faixa | Correspondência de Prefixo |
⚙️ Considerações de Desempenho
Ao modelar hierarquias, você deve considerar como o motor de banco de dados manipula os dados. As estratégias de indexação desempenham um papel fundamental, independentemente do modelo escolhido.
- Lista de Adjacência: Indexe a coluna
parent_idcoluna intensamente. Isso permite que o banco de dados localize rapidamente todos os filhos de um nó específico sem escanear toda a tabela. - Conjuntos Aninhados: Índice ambos
lftergt. Índices compostos podem otimizar significativamente consultas de intervalo. - Caminho Materializado: Índice a coluna
pathcoluna. Dependendo do banco de dados, um índice de prefixo pode ser benéfico para filtrar subárvores.
🛠️ Manutenção e Atualizações
Modelos de dados não são estáticos. À medida que sua organização cresce, sua hierarquia mudará. Mover um nó de uma ramificação para outra é uma operação comum que afeta cada modelo de forma diferente.
🔄 Movendo Nós
Em um Lista de Adjacência, mover um nó é uma única instrução de atualização. Você altera o parent_id da raiz da subárvore. No entanto, você deve garantir que não sejam criadas referências circulares.
Em um Conjunto Aninhado modelo, mover um nó é complexo. Isso envolve o recálculo dos valores de lft e rgt para todos os nós na subárvore de destino para abrir espaço para o nó movido. Isso geralmente é uma operação transacional que envolve várias atualizações de tabela.
Em um Caminho Materializado modelo, você atualiza a string do caminho do nó movido e de todos os seus descendentes. Isso exige a atualização do caminho para cada filho, o que pode ser uma operação pesada de escrita em árvores grandes.
🎯 Melhores Práticas para Modelagem de Dados
Para garantir que seu ERD permaneça manutenível e performático, siga estas diretrizes ao implementar estruturas hierárquicas.
- Use convenções de nomeação claras: Evite nomes genéricos como
col1. Useparent_id,ancestor_id,lft, ourgtexplicitamente. - Impor restrições: Use restrições do banco de dados para evitar referências circulares. Um nó não pode ser seu próprio ancestral.
- Limite a profundidade: Embora tecnicamente possível, hierarquias extremamente profundas (por exemplo, mais de 10 níveis) frequentemente indicam um problema de design. Considere aplanar a estrutura, se possível.
- Documente a escolha: Como esses padrões não são recursos padrão do SQL, documente qual padrão está sendo usado na documentação do esquema.
- Considere abordagens híbridas: Alguns sistemas combinam listas de adjacência com caminhos materializados para equilibrar o desempenho de leitura e escrita.
🧠 Escolhendo a Estratégia Correta
Não há uma única resposta ‘correta’ para cada cenário. A decisão depende dos requisitos específicos da sua aplicação.
- Escolha a Lista de Adjacência se: Se seus dados mudam frequentemente e a profundidade da hierarquia é moderada. Este é o padrão mais seguro para a maioria das aplicações gerais.
- Escolha os Conjuntos Aninhados se: Se você tem uma aplicação com alta carga de leitura, em que os dados raramente são movidos, e precisa recuperar grandes subárvores rapidamente.
- Escolha o Caminho Materializado se: Se você precisa de caminhos legíveis por humanos (como URLs) e a profundidade da hierarquia é relativamente pequena.
Compreender essas nuances estruturais permite que você projete bancos de dados escalonáveis. Ao selecionar o padrão apropriado para o seu Diagrama de Relacionamento de Entidades, você garante que seus dados permaneçam consistentes, acessíveis e eficientes ao longo de todo o ciclo de vida do sistema.