











Na arquitetura de sistemas relacionais, a tensão entre integridade de dados e desempenho é constante. Diagramas de Relacionamento de Entidades (ERDs) servem como o projeto para essa estrutura, definindo como as tabelas se conectam. Embora as chaves estrangeiras garantam que as relações permaneçam válidas, elas introduzem sobrecarga que pode tornar o throughput um gargalo. Compreender como ajustar essas restrições é essencial para sistemas que lidam com transações de alto volume. Este guia explora a mecânica de otimizar chaves estrangeiras para manter a consistência sem sacrificar velocidade. ⚡
Compreendendo o Custo da Aplicação da Integridade 🛡️
Chaves estrangeiras não são meros rótulos; são regras ativas impostas pelo motor do banco de dados. Cada operação de inserção, atualização ou exclusão que envolva uma chave estrangeira dispara lógica de validação. Essa lógica verifica a tabela pai para garantir que o valor referenciado exista. Em ambientes de alto throughput, essa verificação torna-se um custo significativo.
O processo de validação geralmente envolve:
- Operações de Busca: O sistema deve pesquisar a tabela pai pelo ID referenciado.
- Mecanismos de Bloqueio: A linha pai frequentemente exige um bloqueio para evitar modificações concorrentes durante a verificação.
- Percurso de Índice: Sem indexação adequada, o motor varre grandes partes da tabela pai.
Quando milhões de transações ocorrem por segundo, esses pequenos atrasos se acumulam. O objetivo não é remover a integridade, mas simplificar o processo de verificação. Considere os seguintes cenários em que essa sobrecarga afeta o desempenho:
- Importações em Lote: Carregar dados históricos frequentemente exige desativar temporariamente as restrições.
- Escritas de Alta Frequência: Sistemas que registram eventos ou dados de sensores podem priorizar velocidade sobre consistência imediata.
- Operações em Cascata: A exclusão de um registro pai pode acionar atualizações em múltiplas tabelas filhas.
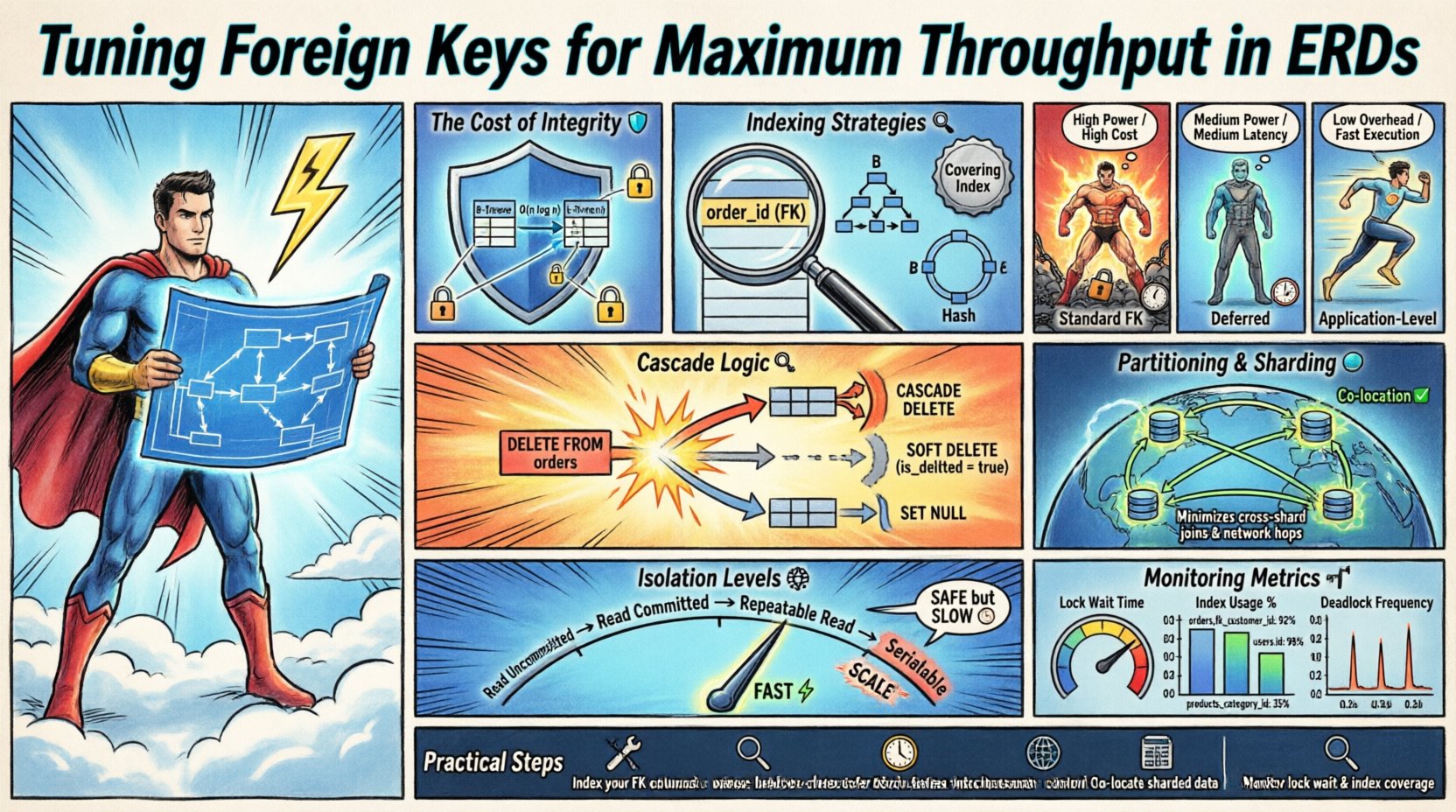
Estratégias de Indexação para Chaves Estrangeiras 🔍
A indexação é o meio mais direto para melhorar o desempenho de chaves estrangeiras. A tabela filha deve ter um índice na coluna da chave estrangeira para evitar varreduras completas da tabela durante atualizações. Se o índice estiver ausente, o banco de dados precisará percorrer toda a tabela pai para validar a relação.
Considerações-chave para indexação incluem:
- Ordem das Colunas: Se a chave estrangeira fizer parte de um índice composto, sua posição é relevante para o planejamento de consultas.
- Motor de Armazenamento: Camadas de armazenamento diferentes lidam com índices de maneiras distintas. Estruturas B-Tree são comuns, mas índices Hash podem oferecer buscas mais rápidas para verificações de igualdade.
- Índices Cobertores: Incluir a chave estrangeira no índice permite que o motor recupere dados sem acessar o heap.
Um erro comum é assumir que a chave primária é suficiente. Se a coluna da chave estrangeira for frequentemente consultada ou atualizada, ela exige seu próprio índice dedicado. Isso garante que a etapa de validação não se torne uma varredura sequencial.
Tipos de Restrição e Seu Impacto 📊
Nem todas as chaves estrangeiras se comportam da mesma forma. A definição da restrição determina o comportamento de bloqueio e a extensão da verificação. Escolher o tipo de restrição adequado é uma decisão de design crítica.
Compare os seguintes comportamentos de restrição:
| Tipo de Restrição | Impacto na Escrita | Impacto na Leitura | Caso de Uso |
|---|---|---|---|
| FK Padrão | Alto (Bloqueia o Pai) | Baixo | Dados Transacionais Principais |
| Diferido | Médio (Verificação no Commit) | Baixo | Carregamentos em Lote / Jobs em Lote |
| Sem Índice | Médio (Varre o Pai) | Médio | Um-para-Muitos com Atualizações Raras |
| Nível de Aplicação | Baixo (Sem Bloqueios no Banco) | Baixo | Registro de Alta Velocidade |
A verificação de restrição diferida permite que o banco de dados pule a validação durante a transação e realize-a apenas no momento do commit. Isso reduz a duração dos bloqueios mantidos na tabela pai. É particularmente útil quando várias linhas na tabela filha referenciam o mesmo pai, ou quando a linha pai pode ser criada dentro da mesma transação.
Amplificação de Escrita e Lógica de Cascata 🔄
As operações de cascata são ferramentas poderosas para manter a higiene dos dados, mas introduzem amplificação de escrita. Quando um registro pai é excluído, o sistema deve localizar e excluir todos os registros filhos associados. Isso multiplica as operações de E/S necessárias.
Estratégias para mitigar isso incluem:
- Exclusão Suave: Em vez de remover fisicamente os registros, marque-os como inativos. Isso evita completamente a cadeia de cascata.
- Definir como Nulo: Se a relação for opcional, definir a chave estrangeira como NULO é mais rápido do que excluir as linhas filhas.
- Restringir Evite a exclusão se houver filhos. Isso força a aplicação a lidar com a limpeza de forma controlada.
Em sistemas distribuídos, exclusões em cascata podem causar picos de latência. A exclusão de um único pai pode acionar milhares de atualizações de filhos em diferentes partições. Geralmente é melhor lidar com a limpeza de forma assíncrona usando tarefas em segundo plano.
Considerações sobre Particionamento e Sharding 🌐
À medida que os dados crescem, o desempenho de uma única tabela piora. O particionamento divide tabelas grandes em partes gerenciáveis. Chaves estrangeiras complicam esse processo porque a relação deve abranger partições.
Desafios em ambientes particionados incluem:
- Blocos entre partições: Se as tabelas pai e filha forem particionadas de forma diferente, o motor deve coordenar os bloqueios entre partições.
- Custo de roteamento:As consultas devem determinar em qual partição está armazenados os dados referenciados.
- Chaves de Sharding:A coluna da chave estrangeira deveria idealmente ser a chave de sharding para colocar dados relacionados no mesmo local.
Se a chave estrangeira não for a chave de sharding, o sistema deve rotear as consultas para o shard correto para validação. Essa latência de rede se acumula. Colocar registros pai e filho no mesmo nó minimiza esse custo.
Níveis de Isolamento de Transações e Throughput 🧩
O nível de isolamento define como as transações interagem entre si. Níveis de isolamento mais altos fornecem consistência mais forte, mas aumentam a contenção. As chaves estrangeiras interagem diretamente com os mecanismos de bloqueio definidos pelos níveis de isolamento.
Impactos comuns de isolamento:
- Leitura Comitida:Permite leituras sujas. As verificações de chaves estrangeiras podem ver dados não confirmados de outras transações, potencialmente levando a condições de corrida.
- Leitura Repetível:Bloqueia a linha pai durante a duração da transação. Isso evita leituras fantasma, mas reduz a concorrência.
- Serializável:Oferece a maior segurança. As chaves estrangeiras são estritamente aplicadas, mas o throughput cai significativamente devido à serialização.
Selecionar o nível de isolamento mais baixo que atenda à sua lógica de negócios é uma técnica de otimização padrão. Se o seu aplicativo puder tolerar consistência eventual, reduzir o nível de isolamento pode melhorar drasticamente o throughput de escrita.
Métricas de Monitoramento e Manutenção 📈
A otimização é um processo contínuo. Você deve monitorar métricas específicas para identificar gargalos relacionados a chaves estrangeiras.
Métricas-chave a acompanhar:
- Tempo de espera por bloqueio:Valores altos indicam contenção nas tabelas pai.
- Uso de índices:Índices não utilizados desperdiçam armazenamento e retardam as escritas.
- Frequência de deadlocks:Chaves estrangeiras são uma causa comum de bloqueios em sistemas concorrentes.
- Tempo de Execução da Consulta:Inserções lentas muitas vezes indicam a ausência de índices em colunas de chaves estrangeiras.
Auditorias regulares do modelo ERD em relação aos padrões de consultas reais garantem que o design corresponda à carga de trabalho. Um esquema projetado para acesso pesado em leitura pode diferir de um projetado para acesso pesado em gravação.
Passos Práticos de Implementação 🛠️
Implementar estas otimizações exige uma abordagem estruturada. Siga estas etapas para ajustar o seu ambiente:
- Perfis de Carga Atual:Identifique quais tabelas geram mais violações de chave estrangeira ou bloqueios.
- Analise os Planos de Consulta:Garanta que as colunas de chave estrangeira sejam cobertas por índices.
- Revise as Regras de Cascata:Determine se exclusões rígidas são necessárias ou se exclusões suaves são suficientes.
- Teste de Concorrência:Simule gravações em grande volume para medir a contenção de bloqueios.
- Afinar Restrições:Mude de ON DELETE CASCADEpara limpeza ao nível da aplicação, quando apropriado.
Ao abordar sistematicamente essas áreas, você reduz a tensão entre a integridade dos dados e a velocidade do sistema. O resultado é uma arquitetura robusta capaz de lidar com escalabilidade sem comprometer a confiabilidade.