











Projetar uma estrutura de banco de dados robusta exige precisão e visão de longo prazo. O Diagrama Entidade-Relacionamento (DER) serve como o plano arquitetônico fundamental para essa estrutura. Sem um mapa claro, a redundância de dados e gargalos de consultas surgem rapidamente, levando à degradação do desempenho ao longo do tempo. Este guia explora como derivar técnicas de otimização diretamente desses modelos visuais. Focamos na integridade estrutural e no ajuste de desempenho sem depender de recursos específicos da plataforma ou ferramentas proprietárias. Ao compreender as relações subjacentes, você pode construir sistemas que escalonam de forma eficiente.
📐 Compreendendo os Fundamentos do DER
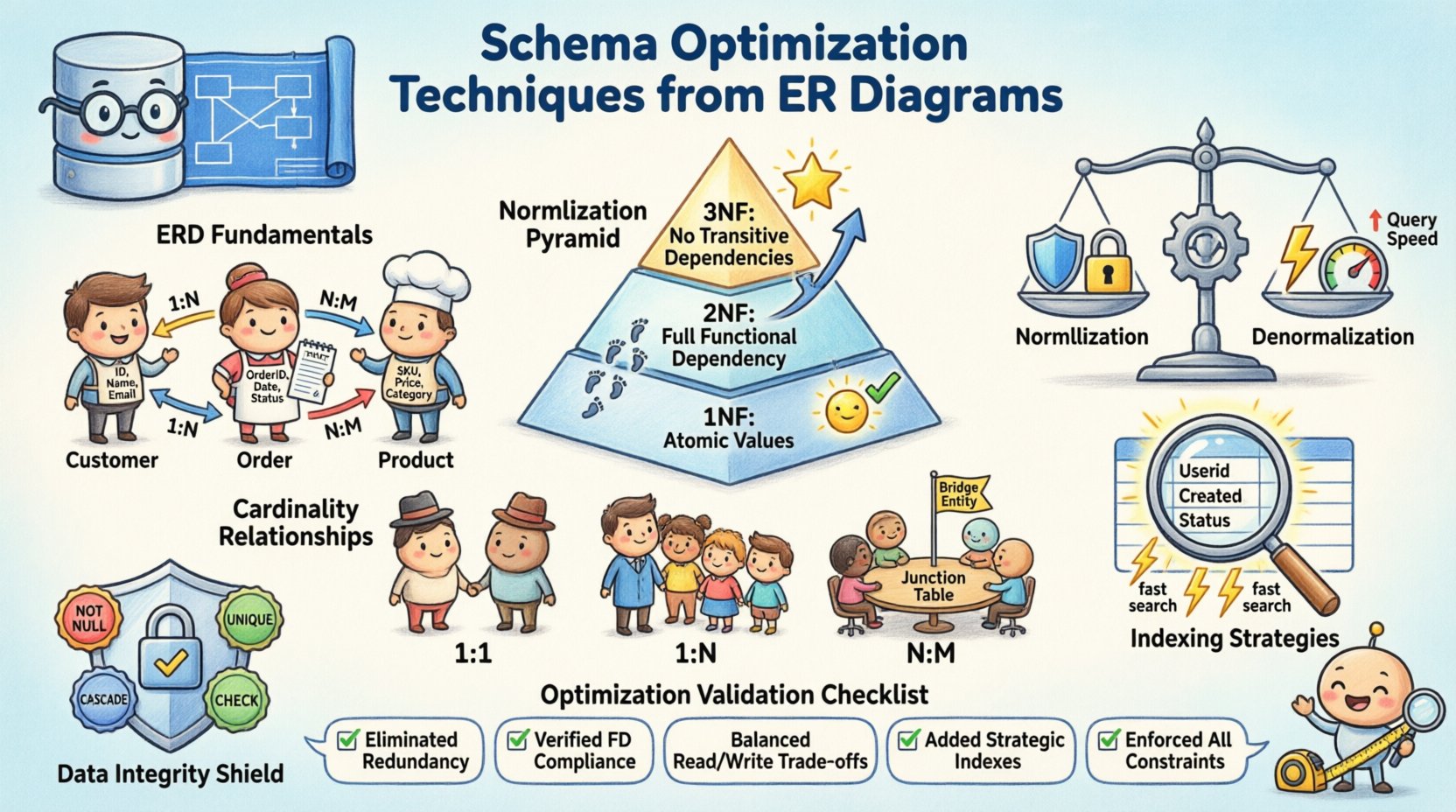
Antes que a otimização comece, os componentes principais devem estar claros. Um diagrama ER traduz requisitos de negócios em um modelo de dados lógico. Ele define como as informações são armazenadas e acessadas. Uma base sólida evita dívidas estruturais posteriormente no ciclo de desenvolvimento. Considere os seguintes elementos:
- Entidades: Representam objetos ou conceitos, como clientes, pedidos ou produtos. Cada entidade torna-se uma tabela no esquema físico.
- Atributos: Definem propriedades das entidades, como nome, ID ou horário. Esses tornam-se colunas dentro das tabelas.
- Relacionamentos: Mostram como as entidades interagem. Isso determina o uso de chaves estrangeiras e restrições.
Visualizar esses componentes permite identificar problemas potenciais antes de escrever uma única linha de código. Isso garante que o fluxo lógico corresponda aos requisitos de armazenamento físico. Essa alinhamento é crítico para manter a consistência dos dados em aplicações complexas.
🔨 Estratégias de Normalização para Integridade de Dados
A normalização é o processo de organizar dados para reduzir redundâncias e melhorar a integridade. Envolve dividir tabelas grandes em unidades menores e lógicas. Embora uma normalização excessiva possa atrasar leituras, ignorá-la por completo cria anomalias de atualização. O objetivo é encontrar o equilíbrio adequado ao seu trabalho específico.
Primeira Forma Normal (1FN)
A primeira regra exige que cada coluna contenha valores atômicos. Não são permitidos grupos repetidos ou matrizes em uma única célula. Isso garante que cada peça de dados seja distinta e consultável. Por exemplo, uma lista de números de telefone deve ser dividida em linhas separadas ou em uma tabela relacionada, e não armazenada como uma string separada por vírgulas.
Segunda Forma Normal (2FN)
Uma vez atendida a 1FN, a 2FN trata as dependências parciais. Todos os atributos não-chave devem depender da chave primária inteira. Em chaves compostas, isso evita a duplicação de dados onde apenas parte da chave determina um atributo. Esta etapa aprimora a estrutura para garantir que cada peça de informação esteja corretamente vinculada ao seu pai.
Terceira Forma Normal (3FN)
A terceira forma elimina dependências transitivas. Atributos não-chave não devem depender de outros atributos não-chave. Isso significa que, se o Atributo A depende do Atributo B, e B depende da Chave, o Atributo A não deve existir na mesma tabela. Mover esses dados para uma tabela separada melhora a manutenibilidade e reduz o desperdício de armazenamento.
A tabela abaixo resume a evolução da normalização:
| Forma Normal | Objetivo Principal | Restrição Chave |
|---|---|---|
| 1FN | Valores Atômicos | Sem grupos repetidos |
| 2FN | Dependência Completa | Remover dependências parciais |
| 3FN | Independência | Remover dependências transitivas |
⚡ Denormalização para desempenho
Enquanto a normalização garante a integridade, frequentemente exige junções complexas durante as consultas. Em sistemas com alta carga de leitura, a sobrecarga de unir múltiplas tabelas pode se tornar um gargalo. A denormalização introduz intencionalmente redundância para melhorar a velocidade de recuperação. Trata-se de uma troca entre eficiência de armazenamento e desempenho de consultas.
Considere os seguintes cenários em que a denormalização é apropriada:
- Painéis de Relatórios: Os dados agregados podem ser previamente calculados e armazenados para evitar cálculos em tempo real.
- Camadas de Cache: Os dados frequentemente acessados podem ser duplicados em um armazenamento otimizado para leitura.
- Transações de Alta Taxa de Transferência: Reduzir a profundidade das junções minimiza a contenção de bloqueios e o uso da CPU.
Ao implementar isso, estabeleça um processo claro para atualizar os dados redundantes. Inconsistências surgem se a fonte da verdade mudar sem atualizar as cópias. Disparadores automáticos ou lógica de aplicação devem lidar com a sincronização para manter a precisão.
🔗 Gerenciamento de Cardinalidade e Relacionamentos
A cardinalidade define a relação numérica entre entidades. Ela determina como as chaves estrangeiras são implementadas e como os dados são vinculados. Compreender esses padrões é essencial para evitar registros órfãos e garantir a integridade referencial.
- Um para Um: Rara em sistemas gerais, frequentemente usada para tabelas de segurança ou de extensão. Uma única linha na Tabela A está ligada exatamente a uma linha na Tabela B.
- Um para Muitos: O relacionamento mais comum. Um registro pai está relacionado a múltiplos registros filhos. A chave estrangeira reside na tabela filha.
- Muitos para Muitos:Requer uma tabela de junção para resolver o relacionamento. Essa tabela intermediária liga as chaves primárias de ambas as entidades.
Suposições incorretas sobre cardinalidade levam a armazenamento ineficiente ou estados inválidos de dados. Por exemplo, tratar um relacionamento muitos para muitos como uma coluna simples impedirá múltiplas associações. Modelar corretamente esses links garante que o banco de dados possa aplicar as regras de negócios definidas no diagrama.
📉 Estratégias de Indexação Baseadas em Análise Estrutural
Índices são o mecanismo que permite ao motor do banco de dados encontrar dados rapidamente. A estrutura do ERD informa diretamente quais colunas devem ser indexadas. Adicionar índices cegamente consome espaço em disco e desacelera as operações de escrita.
Considerações-chave sobre indexação incluem:
- Chaves Primárias: Sempre indexadas por padrão. Elas definem a identidade única de cada linha.
- Chaves Estrangeiras: Frequentemente exigem indexação para acelerar operações de junção e verificações de restrição.
- Chaves Compostas: Usadas quando as consultas filtram por múltiplas colunas. A ordem das colunas no índice importa para o desempenho.
- Colunas Seletivas: Índice colunas com alta cardinalidade. Baixa seletividade (por exemplo, gênero) raramente se beneficia de um índice.
Analise os padrões de consulta em relação ao design do esquema. Se uma junção específica for executada com frequência, certifique-se de que a coluna de chave estrangeira esteja indexada. Isso reduz o tempo que o banco de dados gasta escaneando tabelas inteiras.
🛡️ Integridade de Dados e Restrições Referenciais
Restrições de integridade protegem a precisão e a consistência dos dados. Elas atuam como uma barreira de segurança contra entradas inválidas ou exclusões acidentais. Embora algumas restrições sejam aplicadas pela aplicação, as restrições no nível do banco de dados são mais confiáveis.
Os tipos comuns de restrições incluem:
- NÃO NULO: Garante que uma coluna sempre contenha um valor. Evita lacunas em campos críticos de dados.
- ÚNICO: Garante que nenhuma linha compartilhe o mesmo valor em uma coluna específica. Útil para e-mails ou nomes de usuário.
- CASCADE: Define o que acontece com os registros filhos quando um registro pai é excluído. As opções incluem restringir, propagar (cascade) ou definir como nulo.
- CHECK: Impõe condições específicas sobre os valores dos dados, como intervalos de datas ou limites numéricos.
Implementar essas regras no nível do banco de dados evita que a aplicação precise validar cada ponto de dados. Isso centraliza a lógica de validade dos dados, reduzindo a duplicação de código e erros potenciais.
🔄 Aperfeiçoamento Iterativo e Evolução do Esquema
O design do esquema não é uma tarefa única. Os requisitos de negócios mudam, e o modelo de dados deve evoluir. Revisões regulares do diagrama ERD e do esquema físico ajudam a identificar áreas para melhoria. Monitorar o desempenho das consultas fornece insights sobre onde a estrutura está enfrentando dificuldades.
Durante o aperfeiçoamento, considere os seguintes passos:
- Revisar o Uso de Índices: Remova índices não utilizados para reduzir a sobrecarga de gravação.
- Verificar Particionamento: Tabelas grandes podem se beneficiar da divisão de dados com base em faixas ou chaves.
- Atualizar Cardinalidade: À medida que a lógica de negócios muda, as relações podem mudar de um-para-muitos para muitos-para-muitos.
- Controle de Versão: Trate as alterações de esquema como código. Registre as modificações para permitir o retorno a uma versão anterior, se necessário.
Essa abordagem iterativa garante que o banco de dados permaneça alinhado às necessidades da aplicação ao longo do tempo. Evita a acumulação de dívida técnica que atrapalha o desenvolvimento futuro.
✅ Lista de Verificação de Otimização
Use esta lista para validar o seu design de esquema antes da implantação:
- Verifique se todas as tabelas atendem ao menos à Terceira Forma Normal (3FN).
- Garanta que as chaves estrangeiras sejam indexadas onde as junções são frequentes.
- Verifique dependências circulares nas relações.
- Confirme que as chaves primárias são definidas para cada tabela.
- Revise as restrições para garantir que as regras de consistência de dados sejam aplicadas.
- Analise os padrões de consulta para identificar oportunidades potenciais de desnormalização.
- Documente todas as suposições relacionadas à cardinalidade e volume de dados.
Seguir esses passos cria uma base resistente para armazenamento de dados. Isso permite que o sistema lidar com o crescimento sem exigir uma reconstrução completa. Um esquema bem otimizado é a diferença entre uma aplicação lenta e uma responsiva.