











Projetar uma arquitetura de dados robusta exige mais do que desenhar caixas e linhas. Exige uma compreensão profunda de como os dados fluem, crescem e interagem ao longo do tempo. Quando um sistema escala, o Modelo de Relacionamento de Entidades (ERD) serve como o plano para a consistência lógica, enquanto as estratégias de particionamento abordam o desempenho físico. Alinhar esses dois aspectos é fundamental para manter a velocidade das consultas, a integridade dos dados e a eficiência operacional. Este guia explora como harmonizar as técnicas de particionamento com seus modelos de dados existentes sem introduzir complexidade ou riscos desnecessários.
🧩 A Base: ERD como Plano
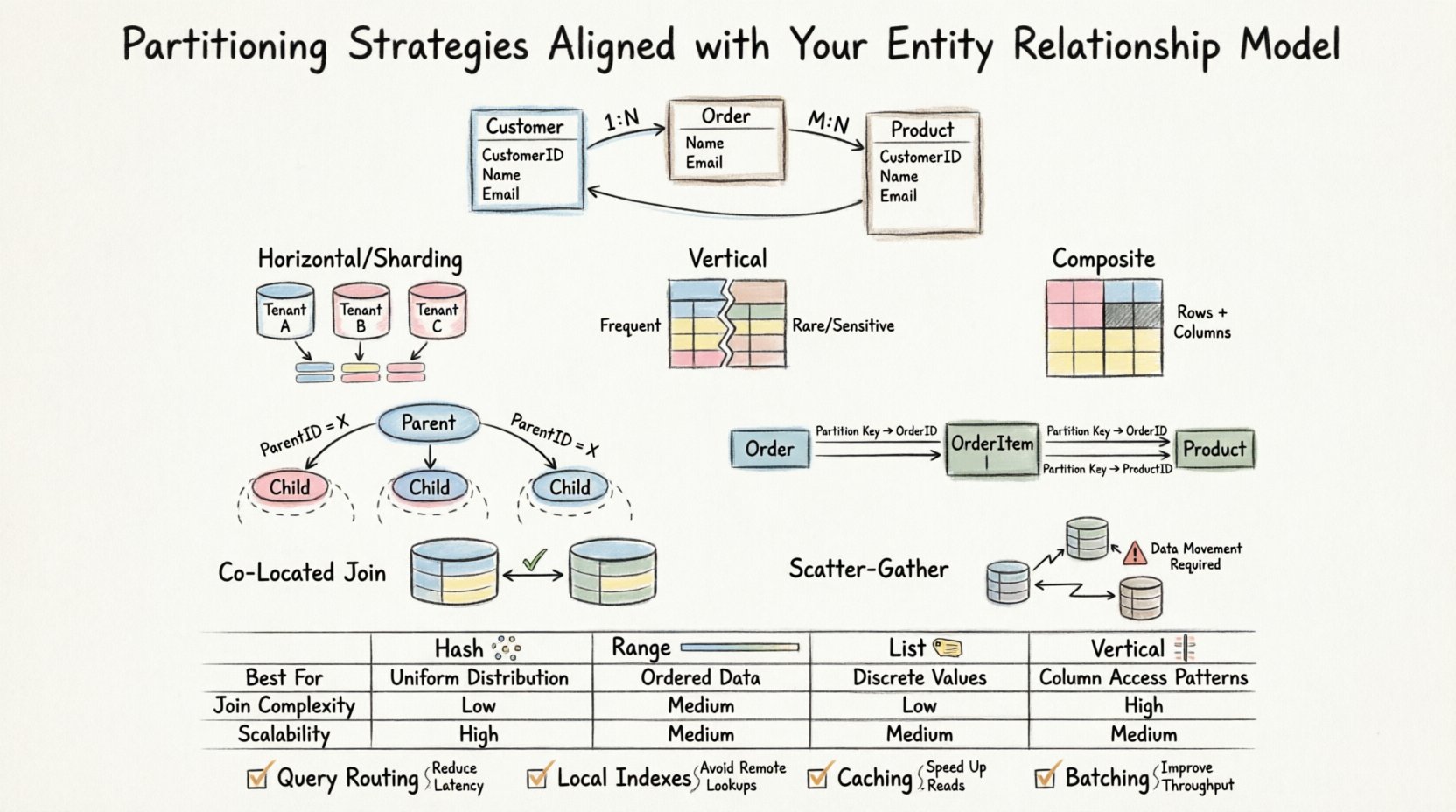
Antes de considerar como dividir os dados, é necessário compreender as relações que os unem. Um ERD define entidades, atributos e a cardinalidade entre eles. Essas relações determinam como os dados são recuperados e unidos. Quando você introduz o particionamento, está essencialmente distribuindo essas relações lógicas sobre limites físicos de armazenamento.
Considere as seguintes implicações do particionamento no seu esquema:
- Chaves Primárias: Devem ser escolhidas com cuidado para garantir uma distribuição equilibrada entre os particionamentos.
- Chaves Estrangeiras:Unir tabelas em particionamentos diferentes pode gerar sobrecarga significativa.
- Índices:Índices globais podem se tornar gargalos se não forem projetados levando em conta a chave de particionamento.
- Localidade de Dados:Dados relacionados deveriam idealmente residir no mesmo nó para minimizar a latência da rede.
Ignorar esses fatores pode levar a uma situação em que o modelo lógico funciona perfeitamente no design, mas a implementação física luta sob carga. O objetivo é manter os dados relacionados próximos uns dos outros, ao mesmo tempo em que permitem crescimento independente.
🔄 Tipos de Particionamento e Ajuste ao Esquema
Métodos diferentes de particionamento se adaptam a diferentes padrões de acesso a dados. Escolher o método certo depende fortemente de como o seu ERD define as relações e os padrões de consulta esperados. Abaixo está uma análise dos principais estratégias e como elas interagem com estruturas relacionais.
Particionamento Horizontal (Sharding)
O particionamento horizontal divide as linhas de uma tabela em grupos diferentes. Isso é frequentemente usado quando as tabelas tornam-se muito grandes para serem gerenciadas em uma única instância. No contexto de um ERD, essa estratégia funciona melhor quando a chave de particionamento está correlacionada com o padrão natural de acesso.
- Caso de Uso:Grandes tabelas transacionais com grupos distintos de usuários ou clientes.
- Impacto no ERD:As chaves estrangeiras que apontam para uma tabela pai devem ser gerenciadas com cuidado. Se a tabela pai também for particionada, as chaves devem estar alinhadas.
- Benefício:Permite uma escalabilidade massiva adicionando mais nós.
- Desafio:Consultas complexas que abrangem múltiplos particionamentos exigem lógica de agregação.
Particionamento Vertical
O particionamento vertical divide as colunas de uma tabela em grupos diferentes. Isso é útil quando colunas específicas raramente são acessadas juntas ou quando dados sensíveis precisam de isolamento.
- Caso de Uso:Tabelas com linhas largas em que apenas um subconjunto de colunas é consultado com frequência.
- Impacto no ERD: A chave primária deve existir em todas as partições verticais para permitir a reconstrução da linha completa.
- Benefício: Reduz a I/O carregando apenas as colunas necessárias na memória.
- Desafio: São necessárias junções para reconstruir a entidade completa, aumentando a complexidade das consultas.
Particionamento Composto
Esta abordagem combina estratégias horizontais e verticais. É frequentemente necessária em sistemas de alto desempenho onde tanto o volume de linhas quanto a largura das colunas são limitações significativas.
- Caso de Uso: Armazenamento de dados ou logs de negociação de alta frequência.
- Impacto no ERD: Exige uma definição rígida do esquema antes da implementação.
🔑 Alinhando Chaves com Relacionamentos
O passo mais crítico neste processo é selecionar a chave de partição. Essa chave determina qual linha vai para qual unidade de armazenamento física. Em um contexto relacional, a chave de partição deveria idealmente corresponder às relações de chave estrangeira.
Relacionamentos Pai-Filho
Ao lidar com relacionamentos um-para-muitos, a tabela filha geralmente cresce muito mais rápido que a tabela pai. Se você particionar a tabela filha pelo ID do pai, todos os registros filhos relacionados residirão no mesmo nó.
- Vantagem: Consultas que recuperam o pai e todos os filhos não exigem comunicação entre nós.
- Vantagem: Exclusão em cascata é eficiente dentro de uma única partição.
- Aviso: Se um pai tiver significativamente mais filhos que os outros, pode ocorrer desbalanceamento de dados.
Relacionamentos Muitos para Muitos
Relacionamentos muitos para muitos geralmente envolvem uma tabela de junção. Essa tabela pode se tornar um gargalo de desempenho se não for particionada corretamente.
- Estratégia: Particionar com base em uma das chaves estrangeiras envolvidas.
- Estratégia: Garanta que as consultas sempre filtrem pela chave de partição para evitar varreduras completas da tabela.
- Estratégia: Evite unir tabelas de junção entre múltiplas partições, a menos que absolutamente necessário.
⚖️ Manipulação de Operações de Junção
As junções são o sangue das bases de dados relacionais, mas tornam-se caras quando os dados são divididos. Compreender como as junções se comportam entre partições é essencial para manter o desempenho.
Partições Co-localizadas
Se a Tabela A e a Tabela B forem particionadas pela mesma chave (por exemplo, Tenant_ID), a junção entre elas ocorre localmente. O motor do banco de dados não precisa mover dados entre nós.
- Requisito:Ambas as tabelas devem usar o mesmo algoritmo e chave de particionamento.
- Requisito:O ERD deve suportar essa alinhamento logicamente.
Junções de Dispersão-Agregação
Quando as tabelas são particionadas de forma diferente, o sistema deve buscar dados de múltiplos nós, aglomerar os resultados e depois retornar o conjunto final. Isso é conhecido como uma operação de dispersão-agregação.
- Custo de Desempenho: Alto custo com rede.
- Custo de Desempenho: Latência aumentada.
- Recomendação:Minimize essas junções na fase de design do ERD.
🛡️ Mantendo a Integridade Entre Partições
As restrições de integridade de dados são mais difíceis de aplicar quando os dados são distribuídos. O ERD define essas regras logicamente, mas a implementação deve lidar com a distribuição física.
- Integridade Referencial:Garantir que um registro filho exista antes de inserir um registro pai é complexo se eles residirem em nós diferentes.
- Restrições Únicas:A unicidade global exige coordenação entre todas as partições.
- Gatilhos:Gatilhos de nível de aplicação frequentemente substituem gatilhos de nível de banco de dados em ambientes distribuídos para evitar problemas de bloqueio.
- Transações:Transações distribuídas podem afetar o throughput. Mantenha as transações locais a uma única partição sempre que possível.
📊 Comparação de Estratégias de Particionamento
A tabela a seguir resume como diferentes estratégias interagem com cenários comuns do ERD.
| Estratégia | Melhor para o Cenário do ERD | Complexidade de Junção | Escalabilidade de Escrita |
|---|---|---|---|
| Particionamento por Hash | Distribuição uniforme necessária, sem faixa específica | Alta (distribuição aleatória) | Alta |
| Particionamento por Faixa | IDs baseados em data ou sequenciais | Baixa (se alinhada) | Média |
| Particionamento por Lista | Categorias fixas (por exemplo, Região, Status) | Baixa (se alinhada) | Alta |
| Particionamento Vertical | Linhas largas, colunas pouco frequentes | Média (requer reconstrução) | Alta |
🔄 Evolução e Migração
A evolução do esquema é inevitável. Os requisitos de negócios mudam, e novos atributos são adicionados. Ao modificar um ERD, a estratégia de particionamento deve ser revisada.
- Adicionando Colunas:O particionamento vertical torna mais fácil a adição de colunas, pois elas podem ser colocadas em uma nova partição.
- Alterando Chaves:Reparticionar dados existentes é uma operação pesada. Planeje isso durante o projeto inicial.
- Arquivamento:O particionamento permite o arquivamento fácil de faixas antigas de dados sem afetar as partições ativas.
- Monitoramento:Verifique regularmente os tamanhos das partições para garantir que nenhuma partição se torne um ponto de gargalo.
🚀 Dicas de Otimização de Desempenho
Para garantir que o sistema permaneça responsivo, otimizações específicas devem ser aplicadas junto com a estratégia de particionamento.
- Roteamento de Consultas: Certifique-se de que os aplicativos enviem consultas para o nó de partição correto com base na chave de partição.
- Indexação: Índices locais são mais rápidos que índices globais. Projete os índices para corresponder à chave de partição.
- Cache: Tabelas de consulta frequentemente acessadas não devem ser particionadas se forem pequenas o suficiente para caber na memória em todos os nós.
- Agrupamento: Agrupe inserções e atualizações para reduzir a sobrecarga de transações entre partições.
🔍 Considerações Finais
Construir um sistema escalável exige equilibrar a clareza lógica com as restrições físicas. O Modelo de Relacionamento de Entidades fornece as regras para a consistência dos dados, enquanto a partição fornece o mecanismo para o crescimento. Quando esses dois aspectos estão alinhados, o sistema permanece eficiente mesmo com o aumento exponencial do volume de dados.
Concentre-se nas relações definidas no seu modelo. Se os dados forem naturalmente agrupados por um atributo específico, use esse atributo como sua chave de partição. Se as junções forem frequentes, certifique-se de que as tabelas relacionadas compartilhem a mesma lógica de partição. Evite complicar excessivamente o esquema com partições que não atendam a um propósito de desempenho claro.
Ao seguir esses princípios, você cria uma base que suporta a estabilidade de longo prazo. O objetivo não é apenas armazenar dados, mas estruturá-los de forma que o sistema possa se adaptar às demandas futuras sem exigir uma reformulação completa. Um planejamento cuidadoso na fase de design economiza esforço significativo de engenharia durante as operações.