











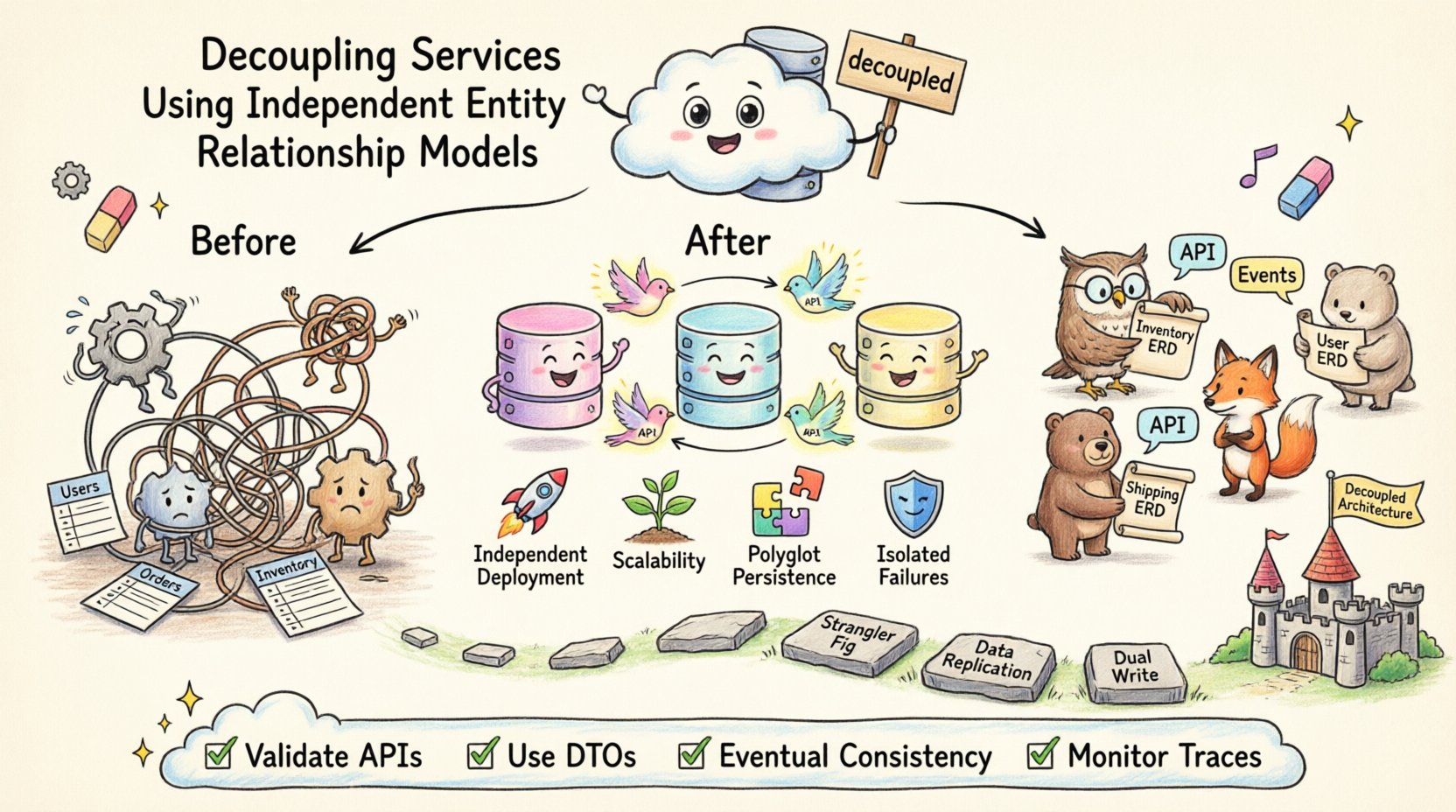
Na arquitetura de software moderna, a separação de responsabilidades estende-se além da lógica do código até a propriedade dos dados. Quando os serviços compartilham um único esquema de banco de dados, inevitavelmente tornam-se dependentes das implementações internas uns dos outros. Esse acoplamento rígido cria fragilidade, dificulta a velocidade de implantação e complica os esforços de escalabilidade. Para alcançar uma modularidade verdadeira, as equipes devem adotar modelos independentes de relacionamento de entidades para cada fronteira de serviço. Essa abordagem garante que as estruturas de dados permaneçam privadas para o serviço que as detém, promovendo resiliência e autonomia.
🤔 O Desafio dos Dados Compartilhados
Sistemas legados frequentemente dependem de um banco de dados monolítico onde múltiplos módulos de aplicação consultam as mesmas tabelas. Embora isso simplifique o desenvolvimento inicial, introduz riscos significativos à medida que o sistema cresce. Uma alteração nos requisitos de dados de um módulo pode quebrar a funcionalidade de outro módulo que depende dessa mesma estrutura de tabela. Esse fenômeno é conhecido como o anti-padrão de banco de dados compartilhado.
Considere um cenário em que o Serviço de Usuário precisa adicionar um novo campo na tabela de perfil. Se o Serviço de Pedidos consultar essa tabela diretamente para obter nomes de usuários, a atualização pode exigir uma implantação coordenada ou uma migração de banco de dados que afete ambas as equipes simultaneamente. Esse sobrecarga de coordenação desacelera a inovação e aumenta o risco de incidentes em produção.
-
Dependências de Implantação:Os serviços não podem ser implantados de forma independente se compartilharem definições de esquema.
-
Limitações de Escalabilidade:Um único banco de dados frequentemente se torna um gargalo quando serviços específicos exigem mais recursos do que outros.
-
Riscos de Segurança:O acesso direto às tabelas contorna a camada de serviço, potencialmente expondo lógica sensível de dados.
🗺️ Definindo Modelos Independentes de Relacionamento de Entidades
Um modelo independente de relacionamento de entidades (ERD) atribui um esquema de dados específico a um único serviço. Isso significa que o serviço controla seu próprio banco de dados, suas próprias tabelas e suas próprias relações. Outros serviços não têm acesso direto a essas tabelas. Em vez disso, interagem por meio de interfaces definidas, como APIs ou filas de mensagens.
Esse estilo arquitetônico é frequentemente referido como Banco de dados por serviço. Ele alinha a propriedade dos dados com as capacidades de negócios. Por exemplo, um Serviço de Estoque gerencia níveis de estoque, enquanto um Serviço de Entrega gerencia endereços de entrega. Nenhum desses serviços deveria possuir uma referência de chave estrangeira para as tabelas internas do outro.
O processo envolve:
-
Identificando Fronteiras: Determine quais dados pertencem a quais capacidades de negócios.
-
Projetando Esquemas Locais: Crie ERDs que atendam apenas às necessidades específicas desse serviço.
-
Definindo Interfaces: Estabeleça como os dados são trocados entre serviços sem expor suas estruturas internas.
📈 Principais Benefícios da Isolamento de Esquemas
Adotar ERDs independentes transforma a forma como as equipes gerenciam a complexidade. Isso desloca o foco do controle centralizado para a autonomia distribuída. Cada equipe pode otimizar sua estratégia de armazenamento de dados sem se preocupar com impactos globais.
|
Aspecto |
Modelo de Banco de Dados Compartilhado |
Modelo de ERD Independente |
|---|---|---|
|
Implantação |
Coordenado, arriscado |
Independente, frequente |
|
Escalabilidade |
Apenas horizontal (cluster) |
Vertical por serviço |
|
Tecnologia |
Um único tipo de banco de dados |
Persistência poliglota |
|
Domínio de falha |
Ponto único de falha |
Falhas isoladas |
🔗 Projetando para acoplamento fraco
Quando os serviços não podem se comunicar diretamente com os bancos de dados uns dos outros, eles devem se comunicar por meio de APIs. Isso exige um projeto cuidadoso do contrato entre os serviços. A API torna-se o único contrato compartilhado. Se o contrato da API permanecer estável, o modelo de dados subjacente pode mudar sem afetar os consumidores.
Versionamento de API: Como os modelos de dados evoluem, as APIs devem suportar versionamento. Isso permite que clientes antigos funcionem enquanto clientes novos adotam estruturas atualizadas.
Objetos de Transferência de Dados (DTOs): Não exponha objetos de entidade diretamente. Crie DTOs específicos que contenham apenas os dados necessários para o consumidor. Isso evita que mudanças internas se propaguem para fora.
-
Validação: Valide a entrada na fronteira da API, e não apenas no nível do banco de dados.
-
Idempotência: Garanta que operações possam ser repetidas com segurança sem causar registros duplicados.
-
Documentação: Mantenha documentação clara para todos os formatos de troca de dados.
⚖️ Gerenciando transações e consistência
Um dos desafios mais significativos no desacoplamento é manter a integridade dos dados. Em um banco de dados compartilhado, uma transação pode abranger múltiplas tabelas facilmente. Em um sistema distribuído, uma única transação lógica pode abranger múltiplos serviços. Isso é conhecido como o Problema de Transação Distribuída.
Para resolver isso, as equipes frequentemente adotam o Consistência eventual padrão. Em vez de garantir que os dados sejam idênticos em todos os lugares imediatamente, o sistema garante que eles se tornem consistentes ao longo do tempo. Isso é alcançado por meio de mensagens assíncronas.
Padrão Saga:Uma saga é uma sequência de transações locais. Cada transação atualiza o banco de dados e publica um evento para acionar a próxima transação. Se uma etapa falhar, transações compensatórias são executadas para desfazer as alterações anteriores.
-
Padrão Outbox:Escreva eventos em uma tabela local junto com a alteração principal dos dados. Um processo em segundo plano publica esses eventos, garantindo que nenhum dado seja perdido.
-
Consumidores Idempotentes:Os manipuladores de mensagens devem lidar com mensagens duplicadas de forma adequada.
-
Ações Compensatórias:Defina uma lógica de rollback clara para cada ação de avanço.
🚚 Estratégias de Migração
Migrar de um banco de dados compartilhado para ERDs independentes é uma tarefa significativa. Exige uma abordagem em fases para minimizar riscos. Apressar a migração pode levar à perda de dados ou interrupções no serviço.
Padrão Figura de Estrangulamento:Mova gradualmente a funcionalidade para novos serviços. Comece com um recurso específico, como notificações de usuários. Crie um novo serviço com seu próprio ERD para esse recurso. Encaminhe o tráfego para o novo serviço enquanto mantém o sistema legado em funcionamento.
Replicação de Dados:Durante a transição, você pode precisar manter os dados sincronizados entre os bancos de dados antigo e novo. Isso permite que o novo serviço leia dados do sistema antigo temporariamente enquanto preenche o seu próprio.
Escrita Dupla:Escreva simultaneamente nos bancos de dados antigo e novo durante a janela de migração. Verifique se o novo serviço funciona corretamente antes de desativar as escritas antigas.
🔍 Monitoramento e Manutenção
Com armazenamentos de dados independentes, o monitoramento torna-se mais complexo. Você já não está olhando para um único painel de saúde do banco de dados. Você deve agrupar logs e métricas de várias fontes.
Rastreamento Distribuído:Implemente rastreamento para acompanhar uma solicitação enquanto ela passa por diferentes serviços. Isso ajuda a identificar qual serviço está causando latência ou erros.
Registro de Esquemas:Mantenha um registro de contratos de API. Isso garante que qualquer alteração no modelo de dados seja revisada e aprovada antes da implantação.
-
Alertas:Defina alertas para atraso na replicação e filas de mensagens com backlog.
-
Planejamento de Capacidade:Monitore o crescimento do armazenamento por serviço para evitar custos inesperados.
-
Estratégias de Backup:Garanta que cada serviço tenha seu próprio plano de backup e recuperação.
🛠️ Armadilhas Comuns a Evitar
Mesmo com um plano sólido, as equipes frequentemente tropeçam na implementação. Compreender esses erros comuns pode poupar tempo e esforço significativos.
-
Acoplamento Oculto:Evite usar visualizações de banco de dados ou tabelas compartilhadas, mesmo que estejam em esquemas separados. O acesso direto ao banco de dados deve ser proibido.
-
Sobrefragmentação:Não crie um novo banco de dados para cada pequena função. Agrupe entidades relacionadas em serviços lógicos.
-
Ignorar a Latência:Chamadas de rede são mais lentas que consultas locais. Projete APIs para minimizar as viagens de ida e volta.
-
Consultas Complexas:Evite junções entre serviços. Se precisar de dados de múltiplos serviços, consulte-os separadamente e combine os resultados na camada de aplicação.
🧱 Pensamentos Finais
Desacoplar serviços usando modelos independentes de relacionamento de entidades é uma decisão estratégica que se mostra vantajosa a longo prazo. Exige disciplina no design e disposição para gerenciar a complexidade distribuída. No entanto, o resultado é um sistema mais fácil de escalar, mais resiliente a falhas e mais rápido para evoluir. Ao assumirem o controle de seus dados, os serviços adquirem a autonomia necessária para inovar sem coordenação constante.
Comece identificando os limites mais críticos do seu sistema. Isole primeiro os dados desses serviços. Aperfeiçoe seus contratos de API e padrões de mensagens conforme avança. Esse abordagem incremental garante estabilidade enquanto avança rumo a uma arquitetura totalmente desacoplada.