











Projetar um banco de dados robusto começa muito antes da primeira consulta ser executada. Tudo começa com o projeto: o Diagrama de Relacionamento de Entidades (ERD). 📐 Embora muitos desenvolvedores se concentrem na criação de tabelas e tipos de colunas, o verdadeiro motor de desempenho reside na forma como os índices se alinham com o seu modelo de dados. Indexar não é meramente uma configuração; é uma manifestação física das suas relações lógicas.
Quando você estrutura o seu ERD, define a cardinalidade e a conectividade dos seus dados. Essas escolhas estruturais determinam as estratégias de indexação mais eficientes. Uma relação um para um exige uma abordagem diferente daquela usada em uma junção muitos para muitos. Ignorar essas nuances frequentemente resulta em junções lentas, I/O excessivo e armazenamento fragmentado. Este guia explora como traduzir o seu ERD em padrões de indexação de alto desempenho sem depender de ferramentas específicas de fornecedores.
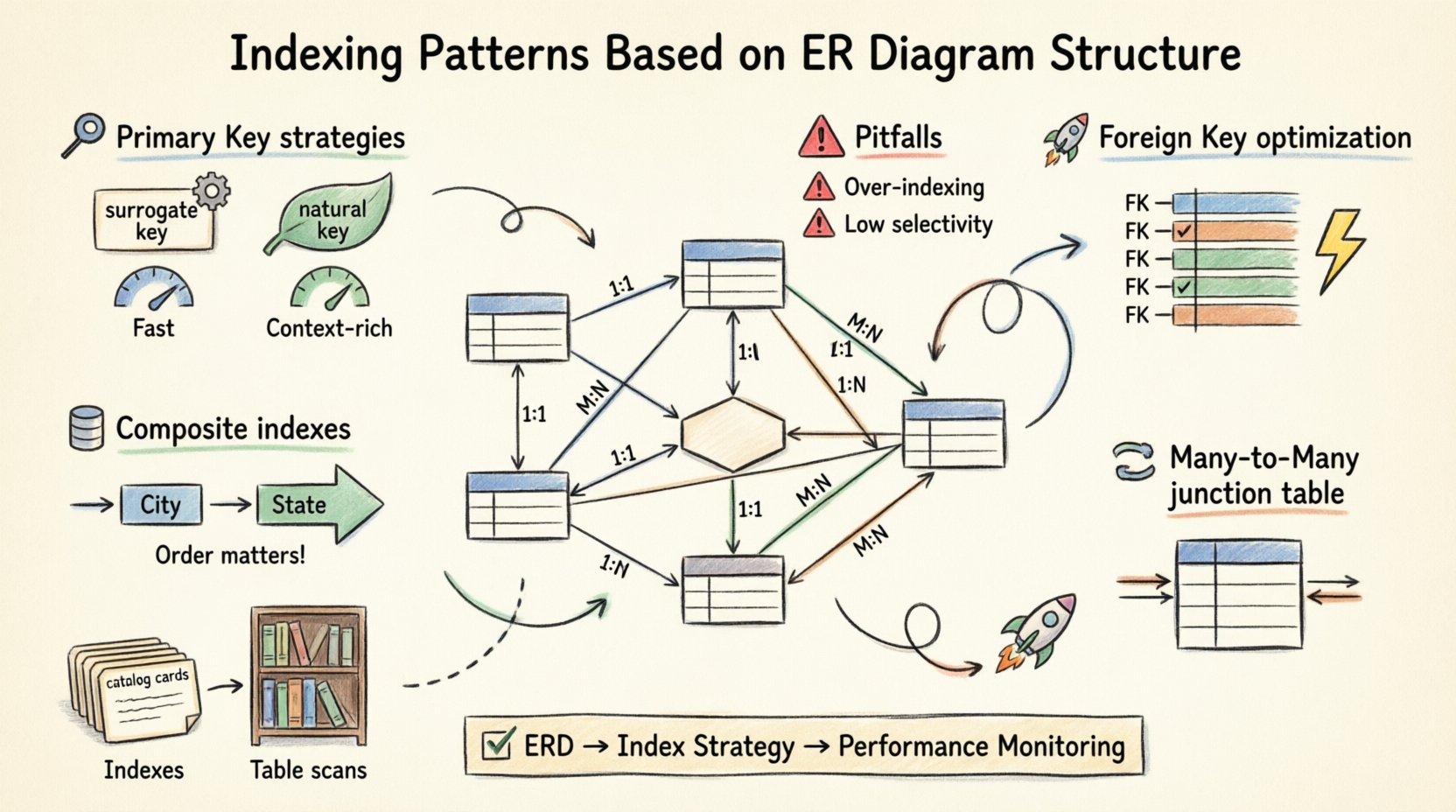
🔑 Compreendendo a Fundação: ERD e Indexação
Um ERD é mais do que uma ajuda visual; é um contrato entre a lógica da sua aplicação e o motor de armazenamento. Cada linha traçada entre entidades representa uma restrição que o banco de dados deve garantir. Os índices servem para acelerar a aplicação dessas restrições e a recuperação de dados entre elas.
Considere a camada de armazenamento como uma biblioteca. Sem um índice, encontrar um livro exige varrer cada prateleira (uma varredura completa da tabela). Um índice é a ficha do catálogo. No entanto, colocar as fichas do catálogo incorretamente — talvez por gênero em vez de por autor, quando os autores são a chave de pesquisa principal — torna o sistema ineficiente. O seu ERD indica quem são os autores e os gêneros, e quais relações são mais importantes.
Os principais aspectos a considerar incluem:
- Cardinalidade:Colunas de alta cardinalidade (valores únicos) se beneficiam mais dos índices.
- Frequência de Junção:Tabelas que são frequentemente unidas exigem indexação específica nas chaves estrangeiras.
- Volume de Escrita:Cada índice adiciona sobrecarga às operações de inserção e atualização.
- Padrões de Consulta:Como você filtra? Como você ordena? O ERD dá pistas sobre a resposta.
🏗️ Estratégias de Indexação da Chave Primária
A chave primária (PK) é a base de cada tabela. Ela garante a unicidade e fornece o mecanismo de agrupamento para o armazenamento de dados em muitos sistemas. Alinhar a sua indexação com a definição da PK é o primeiro passo.
1. Chaves Surrogadas vs. Chaves Naturais
Escolher entre uma chave surrogada (um ID auto-incrementado) e uma chave natural (como um e-mail ou número de seguro social) afeta significativamente o desempenho do índice.
- Chaves Surrogadas:São ideais para agrupamento. São curtas, crescem monotonicamente e são sequenciais. Isso minimiza divisões de páginas e fragmentação durante gravações. 📈
- Chaves Naturais:Embora sejam semanticamente significativas, podem ser longas, variáveis em comprimento ou propensas a mudanças. Indexá-las pode resultar em tamanhos maiores de índice e buscas mais lentas em comparação com chaves baseadas em inteiros.
2. Implicações do Índice Agrupado
Na maioria das arquiteturas, a chave primária define o índice agrupado. Isso significa que as linhas de dados reais são armazenadas fisicamente na ordem da chave. Se o seu ERD sugerir que consultas frequentemente filtram por um atributo natural específico, você pode precisar reconsiderar a definição da PK ou aceitar que o índice agrupado será otimizado para um tipo de consulta, enquanto os índices secundários lidarão com os demais.
🔗 Otimização da Chave Estrangeira
As chaves estrangeiras (FK) definem relações entre tabelas. Elas são a fonte mais comum de gargalos de desempenho se deixadas sem índice. Quando você faz uma junção entre duas tabelas, o motor do banco de dados deve corresponder linhas com base na coluna FK. Sem um índice, essa operação degrada-se para uma varredura em loop aninhado, o que é computacionalmente custoso para conjuntos de dados grandes.
1. Indexação da Coluna da Chave Estrangeira
Sempre crie um índice na coluna da chave estrangeira na tabela filha. Isso permite que o motor localize rapidamente as linhas relacionadas sem varrer toda a tabela.
| Cenário | Requisito de Indexação | Impacto no Desempenho |
|---|---|---|
| Um para Muitos (Filho) | Indexar FK na Tabela Filha | Permite pesquisas rápidas para dados do pai |
| Muitos para Um (Pai) | Indexar PK na Tabela Pai (geralmente padrão) | Comportamento padrão da chave primária |
| Exclusão em Cascata | Indexar FK + PK do Pai | Evita o bloqueio de toda a tabela durante a exclusão |
2. Chaves Estrangeiras Compostas
Às vezes, uma relação depende de múltiplas colunas (por exemplo, uma chave composta da tabela pai). Nesse caso, você deve criar um índice composto na tabela filha, correspondendo à ordem e às colunas da chave pai. O desalinhamento na ordem das colunas no índice pode torná-lo inútil para operações de junção.
🔀 Tratamento de Relacionamentos Muitos para Muitos
Relacionamentos Muitos para Muitos (M:N) são resolvidos por meio de uma tabela de junção. Essa tabela contém chaves estrangeiras que apontam para ambas as tabelas pais. A estratégia de indexação aqui é crítica para o desempenho.
Considere um cenário em que Alunos se matriculam em Cursos. A tabela de junção os conecta. Para encontrar todos os cursos de um aluno, você precisa consultar a tabela de junção de forma eficiente.
- Indexação Bi-Direcional: Você deve indexar ambas as colunas de chave estrangeira independentemente. Isso permite que você consulte a relação de qualquer lado (Aluno → Cursos ou Curso → Alunos) sem uma varredura completa.
- Indexação Composta: Se suas consultas sempre recuperarem os cursos de um aluno específico, um índice composto em (Student_ID, Course_ID) é mais eficiente do que dois índices separados. Ele cobre os critérios de pesquisa em uma única busca.
📊 Índices Compostos e Cobertores
Nem todas as consultas filtram por uma única coluna. Consultas complexas frequentemente envolvem múltiplas condições. É aqui que os índices compostos brilham. Um índice composto é um único índice construído em múltiplas colunas.
1. A Ordem das Colunas Importa
A ordem das colunas em um índice composto não é arbitrária. O motor do banco de dados só pode utilizar o índice até o ponto em que as condições de igualdade param. Por exemplo, se você indexar (Cidade, Estado), uma consulta filtrada por Cidade usará o índice. Uma consulta filtrada apenas por Estado provavelmente ignorará o índice.
2. Índices Cobertores
Um índice cobertor inclui todas as colunas necessárias para satisfazer uma consulta, incluindo a lista SELECT. Isso permite que o banco de dados recupere os dados diretamente da árvore do índice, sem acessar a tabela principal (heap). Isso representa uma grande vantagem de desempenho para operações intensivas de leitura.
⚠️ Armadilhas Comuns e Melhores Práticas
Mesmo com um ERD perfeito, erros de implementação podem degradar o desempenho. Abaixo estão armadilhas comuns a serem evitadas ao traduzir a estrutura para armazenamento.
- Sobrecarga de Índices:Cada índice consome espaço em disco e desacelera as operações de escrita. Índice apenas colunas que são frequentemente consultadas ou usadas para restrições.
- Baixa Seletividade:Indexar uma coluna com baixa cardinalidade (por exemplo, uma flag booleana “is_active”) é frequentemente ineficiente. O otimizador pode decidir que uma varredura completa da tabela é mais rápida do que saltar para um índice.
- Ignorar Valores Nulos:Índices tratam valores NULOS de forma diferente dependendo do motor. Certifique-se de que a lógica da sua consulta leve em conta como os NULOS são indexados na sua configuração específica.
- Fragmentação:Com o tempo, os índices ficam fragmentados. Manutenção regular é necessária para manter o desempenho ótimo.
🛠️ Monitoramento e Manutenção de Desempenho
Uma vez que sua estratégia de indexação esteja em vigor, o monitoramento é essencial. Você não pode otimizar o que não mede. Revise regularmente os planos de execução de consultas para verificar se seus índices estão sendo usados de forma eficaz.
1. Analise os Planos de Execução
Procure operações como “Varredura de Índice” versus “Busca de Índice”. Uma busca é eficiente; uma varredura não é. Se você observar varreduras completas de tabelas grandes, reavalie sua estratégia de indexação com base nos padrões de consulta reais.
2. Monitore o Uso de Índices
Às vezes, índices são criados, mas nunca usados. São um peso morto. Audite regularmente as estatísticas de uso de índices para identificar índices não utilizados que podem ser removidos para melhorar o desempenho de escrita.
3. Considerações sobre Crescimento de Dados
À medida que seus dados crescem, o custo de manutenção aumenta. Um índice que funciona bem com 10.000 linhas pode se tornar um gargalo com 10 milhões de linhas. Reavalie seus padrões de indexação derivados do ERD à medida que o conjunto de dados cresce. Estratégias de particionamento também podem se tornar necessárias junto com a indexação.
🔄 Resumo de Alinhamento
Alinhar sua estratégia de indexação com a estrutura do seu ERD é um processo contínuo. Exige compreensão das relações de dados definidas em seu projeto e traduzi-las em otimizações de armazenamento físico.
- Chaves Primárias:Use para agrupamento e unicidade.
- Chaves Estrangeiras:Indexe para desempenho de junções.
- Tabelas de Junção:Indexação bidirecional para relações M:N.
- Padrões de Consulta:Personalize índices compostos para ordens específicas de filtro.
Ao respeitar a integridade estrutural do seu ERD, você constrói um banco de dados que escala de forma elegante. Evita as armadilhas comuns do indexamento improvisado e garante que seus dados permaneçam acessíveis e com bom desempenho à medida que seu aplicativo evolui. Esse método disciplinado garante que o banco de dados suporte sua lógica de negócios sem se tornar um gargalo. 🚀