









Na arquitetura de sistemas de dados robustos, o Diagrama de Relacionamento de Entidades (ERD) serve como o projeto fundamental. À medida que os sistemas crescem em complexidade e o volume de dados aumenta, manter um esquema limpo torna-se crítico. A redundância em um ERD em grande escala não é meramente uma questão de armazenamento desperdiçado; é uma fonte de instabilidade sistêmica. Quando pontos de dados idênticos são armazenados em múltiplas localizações sem um mecanismo para sincronizá-los, o risco de inconsistência de dados aumenta significativamente.
Este guia explora as estratégias técnicas necessárias para minimizar a redundância, ao mesmo tempo em que preserva a flexibilidade necessária para aplicações de alto volume. Analisaremos os princípios de normalização, padrões estruturais e métodos de verificação para garantir que seu modelo de dados permaneça estável ao longo do tempo.
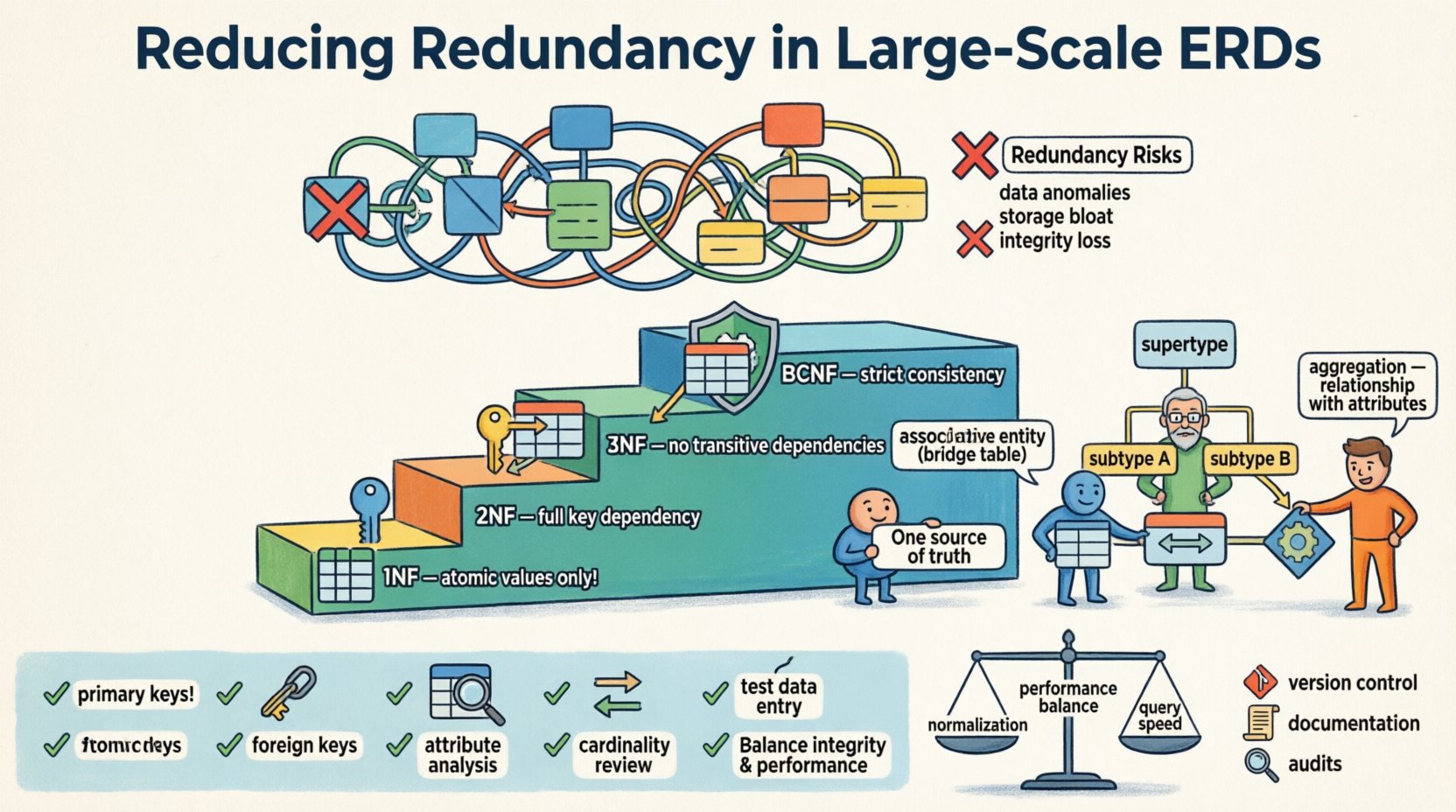
📉 O Custo da Duplicação em Modelos de Dados
A redundância ocorre quando a mesma peça de dados é armazenada mais de uma vez dentro do esquema do banco de dados. Embora alguma desnormalização seja aceitável para otimização de desempenho, a duplicação descontrolada introduz vários riscos que se agravam em ambientes em grande escala.
-
Anomalias de Dados: Atualizar informações em uma localização, mas não em outra, leva a registros conflitantes. Isso é conhecido como anomalia de atualização.
-
Problemas de Inserção: Às vezes, você não consegue adicionar novos dados porque informações relacionadas estão faltando em outro lugar. Isso é uma anomalia de inserção.
-
Riscos de Exclusão: Remover um registro pode acidentalmente apagar informações únicas que foram armazenadas de forma redundante dentro dessa linha. Isso é uma anomalia de exclusão.
-
Inchaço de Armazenamento: Armazenar os mesmos valores repetidamente consome espaço em disco e memória desnecessariamente.
-
Perda de Integridade: Sem restrições que imponham a unicidade em campos redundantes, a única fonte de verdade torna-se fragmentada.
Em diagramas em grande escala, esses problemas se acumulam. Uma única tabela com chaves estrangeiras duplicadas ou atributos descritivos pode causar falhas em cascata durante operações de manutenção. O objetivo é alcançar um equilíbrio em que a integridade dos dados seja preservada sem sacrificar a eficiência das consultas.
🔄 Compreendendo os Princípios de Normalização
A normalização é o processo de organizar dados para reduzir a redundância e melhorar a gestão de dependências. Envolve a decomposição de tabelas em entidades menores e bem estruturadas. Embora a teoria remonte aos anos 1970, os princípios permanecem a base da modelagem de esquemas modernos.
Primeira Forma Normal (1FN)
O primeiro passo é garantir a atomicidade. Cada coluna deve conter valores indivisíveis. Listas dentro de uma única célula violam esse princípio. Por exemplo, armazenar múltiplos números de telefone em um único campo exige dividir esses números em linhas separadas ou em tabelas relacionadas.
Segunda Forma Normal (2FN)
Uma vez que a 1FN é atendida, abordamos as dependências parciais. Uma tabela está na 2FN se estiver na 1FN e todos os atributos não-chave forem totalmente dependentes da chave primária. Em chaves compostas, os atributos não devem depender apenas de parte da chave.
Terceira Forma Normal (3FN)
Este é o padrão mais comum para sistemas transacionais gerais. Uma tabela está na 3FN se estiver na 2FN e não tiver dependências transitivas. Em termos mais simples, atributos não-chave não devem depender de outros atributos não-chave. Se A determina B e B determina C, então A determina C, o que é redundante, a menos que Bé uma chave.
Forma Normal de Boyce-Codd (BCNF)
A BCNF é uma versão mais rigorosa da 3FN. Ela lida com casos em que existem múltiplas chaves candidatas e dependências sobrepostas. Embora nem sempre seja necessária, garante o mais alto nível de consistência lógica.
|
Forma |
Foco |
Requisito Chave |
Impacto na Redundância |
|---|---|---|---|
|
1FN |
Atomicidade |
Sem grupos repetidos |
Estrutura básica |
|
2FN |
Dependências Parciais |
Dependência completa na chave primária |
Reduz a redundância de chaves divididas |
|
3FN |
Dependências Transitivas |
Não-chaves dependem apenas da chave |
Elimina a duplicação de atributos |
|
BCNF |
Dependências Estritas |
Todo determinante é uma chave candidata |
Minimiza sobreposições complexas |
🏛️ Padrões Estruturais Avançados para Escala
A normalização padrão funciona bem para bancos de dados transacionais, mas sistemas de grande escala frequentemente exigem padrões específicos para gerenciar a complexidade sem criar junções excessivas.
Entidades Associativas
Relacionamentos muitos para muitos são uma fonte principal de redundância se mal tratados. Em vez de adicionar chaves estrangeiras em ambas as tabelas relacionadas, crie uma tabela associativa. Essa tabela contém apenas as chaves estrangeiras e quaisquer atributos específicos para a própria relação.
-
Benefício:Alterações nos atributos da relação não exigem alterações nas entidades pais.
-
Benefício:Evita a duplicação de metadados de relacionamento em várias linhas.
Subtipos e SuperTipos
Quando entidades compartilham atributos comuns, mas têm variações específicas, usar um padrão de supertipo/subtipo reduz a duplicação de atributos. Em vez de adicionar colunas opcionais em uma tabela principal que se aplicam apenas a instâncias específicas, crie tabelas separadas para os subtipos vinculadas por uma chave primária compartilhada.
-
Benefício:Mantém a tabela principal de entidades limpa.
-
Benefício:Permite restrições específicas nos subtipos sem afetar o pai.
Agregação
A agregação é usada quando um relacionamento possui atributos que pertencem ao relacionamento, e não às entidades participantes. Em um ERD em grande escala, isso geralmente aparece como um link de resumo ou transacional entre dois grandes domínios.
🧩 Gerenciando a Complexidade em Modelos Grandes
À medida que o número de entidades cresce, o próprio diagrama torna-se um fator de risco se não for gerenciado corretamente. ERDs em grande escala exigem estratégias de modularização.
Modelos Lógico vs. Físico
Separe o design lógico da implementação física. O modelo lógico foca em entidades e relacionamentos, sem se preocupar com mecanismos específicos de armazenamento. O modelo físico lida com indexação, particionamento e tipos de dados. Manter esses dois separados evita que restrições físicas forcem redundância lógica.
Design Modular
Divida o sistema em domínios funcionais. Por exemplo, separe o Domínio de Usuário do Domínio de Cobrança. Cada domínio mantém sua própria consistência interna. As interações entre domínios ocorrem por meio de interfaces ou chaves definidas, em vez de tabelas compartilhadas.
Gerenciamento de Dados Históricos
Armazenar versões históricas de dados pode gerar redundância. Em vez de duplicar linhas inteiras, use colunas de versionamento ou tabelas de auditoria separadas. Isso preserva o estado atual sem sujar a entidade principal com iterações passadas.
🛠️ Armadilhas Comuns no Design de Esquemas
Evitar redundância exige vigilância. Erros comuns incluem:
-
Sobrenormalização:Dividir tabelas com tanta finura que as consultas exigem junções excessivas, prejudicando o desempenho. Às vezes, uma quantidade controlada de redundância é justificada para cargas de trabalho com leitura intensiva.
-
Ignorar Dependências Funcionais:Falhar em identificar quais atributos dependem de quais chaves leva à duplicação oculta.
-
Misturar Preocupações:Colocar atributos de lógica de negócios no modelo de dados. Os atributos devem descrever os dados, e não o processo.
-
Valores Codificados:Armazenar códigos de status ou categorias específicas como strings em vez de referenciar uma tabela de consulta.
✅ Lista de Verificação e Validação
Antes de finalizar um ERD em grande escala, realize uma revisão rigorosa. Use esta lista de verificação para validar seu design.
-
Identifique as Chaves Primárias: Certifique-se de que cada tabela tenha um identificador exclusivo.
-
Verifique as Chaves Estrangeiras:Verifique se todas as relações são enforceadas por chaves, e não por repetir dados.
-
Analise os Atributos:Pergunte se cada atributo não-chave depende da chave, da chave inteira e de nada além da chave.
-
Revise a Cardinalidade:Certifique-se de que relações um-para-muitos sejam representadas por uma única chave estrangeira, e não por múltiplas.
-
Teste a Entrada de Dados:Simule a inserção, atualização e exclusão de registros para verificar anomalias.
🔍 A Função das Restrições
Restrições são a aplicação técnica do design. Restrições únicas impedem valores duplicados em colunas específicas. Restrições de chave estrangeira garantem integridade referencial, impedindo registros órfãos. Em sistemas grandes, as definições de restrições devem fazer parte da definição do esquema, e não serem uma consideração posterior.
Além disso, considere restrições de verificação para limitar o intervalo de valores. Isso evita que dados inválidos entrem no sistema, reduzindo a necessidade de código de tratamento de erros posteriormente.
📈 Considerações de Desempenho
Há um compromisso entre normalização e desempenho. Esquemas altamente normalizados exigem junções para reconstruir dados. Em ambientes com muitas leituras, isso pode atrasar os tempos de resposta. No entanto, adicionar redundância para acelerar leituras pode atrasar gravações devido à necessidade de atualizar múltiplas localizações.
Engines de banco de dados modernos lidam com junções de forma eficiente. Portanto, a abordagem padrão deve favorecer a normalização, a menos que o perfilamento de dados indique um gargalo específico. Se o desempenho for crítico, considere visualizações materializadas ou réplicas de leitura em vez de alterar a estrutura central do esquema.
🔄 Mantendo o Esquema ao Longo do Tempo
Esquemas de banco de dados evoluem. Requisitos mudam e novas entidades surgem. Para manter baixa redundância ao longo do tempo:
-
Controle de Versão:Trate as definições de esquema como código. Rastreie as alterações em um repositório.
-
Documentação:Mantenha documentação atualizada descrevendo relações e dependências.
-
Auditorias Regulares:Agende revisões periódicas do diagrama ERD para identificar novos padrões de redundância.
Ao seguir esses princípios, você garante que a arquitetura de dados permaneça escalável. Um diagrama ERD limpo não é apenas sobre estética; é sobre criar um sistema mais fácil de entender, manter e expandir conforme o negócio cresce.
🎯 Pensamentos Finais sobre a Integridade dos Dados
Reduzir a redundância é um processo contínuo. Exige um entendimento profundo de como os dados fluem pelo sistema e como as relações interagem. Ao aplicar regras de normalização, utilizar padrões estruturais avançados e manter protocolos rigorosos de validação, você constrói uma base que sustenta a estabilidade de longo prazo. O esforço investido em um design limpo traz dividendos em custos reduzidos de manutenção e maior qualidade dos dados.
Concentre-se primeiro nas relações lógicas. Deixe que a implementação física seja um reflexo dessa lógica, e não um compromisso com ela. Com uma abordagem disciplinada no design do diagrama ERD, a redundância torna-se uma variável gerenciável, e não um obstáculo persistente.