










À medida que a acumulação de dados acelera, a arquitetura do seu esquema de banco de dados torna-se um determinante crítico da estabilidade do sistema. Quando uma aplicação passa de operações leitoras intensivas para cargas de trabalho com escrita intensiva, o diagrama padrão de Entidade-Relacionamento (ERD) frequentemente exige ajustes significativos. Projetar para alta taxa de transferência envolve mais do que apenas adicionar índices; exige uma reavaliação fundamental de como os dados são estruturados, vinculados e armazenados. Este guia explora as mudanças arquitetônicas necessárias para manter o desempenho sob pressão sem comprometer a integridade dos dados.
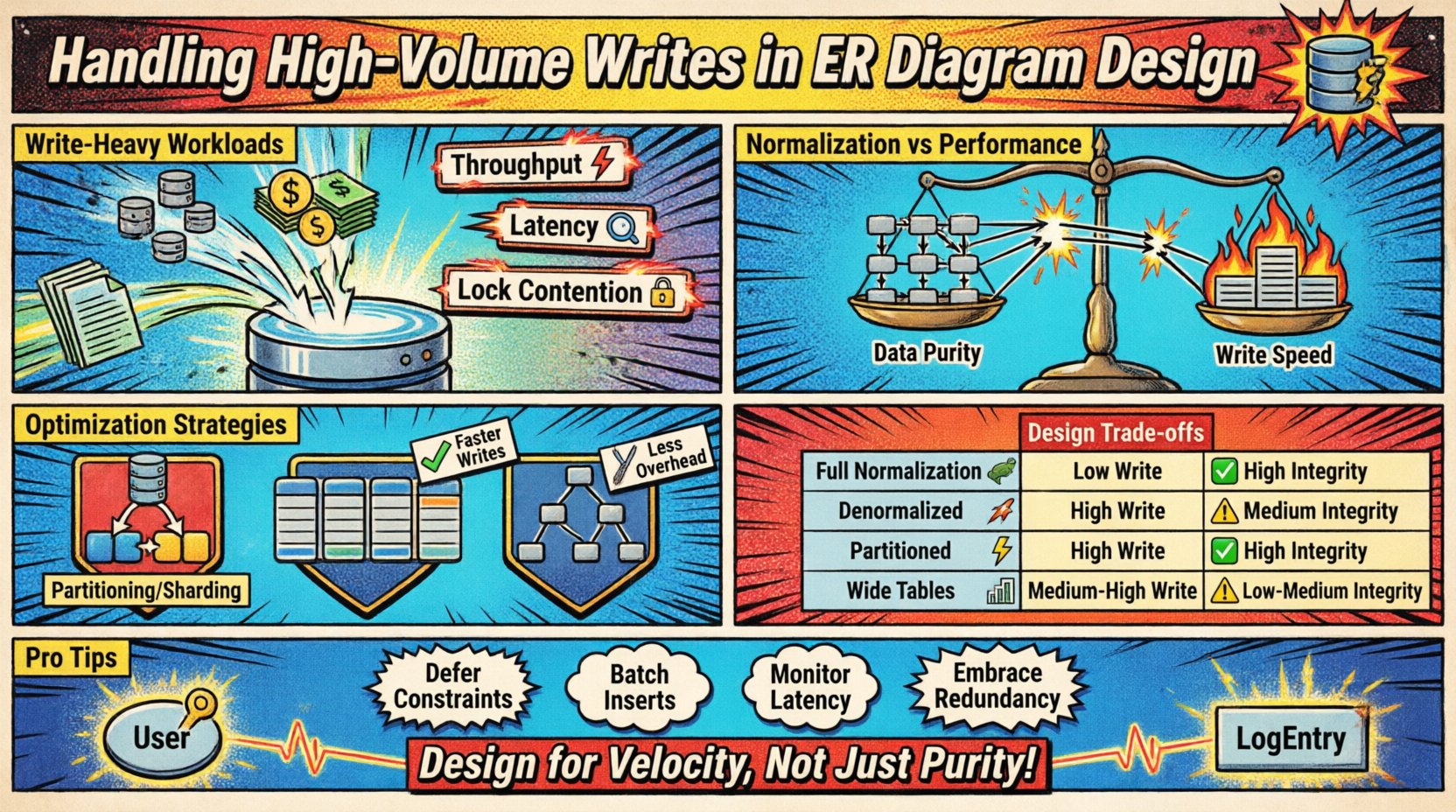
Compreendendo Cargas de Trabalho com Escrita Intensa 📈
Cenários de escrita em alta volume ocorrem quando a taxa de dados entrantes excede a capacidade das técnicas padrão de normalização. Isso frequentemente acontece em sistemas de registro, feeds de sensores IoT, livros de transações financeiras ou plataformas de análise em tempo real. O principal desafio reside em equilibrar a velocidade de inserção com os requisitos de consistência do modelo.
- Taxa de transferência: O número de operações de escrita processadas por segundo.
- Latência: O tempo necessário para persistir com sucesso um registro.
- Contenção de bloqueios: Competição por recursos quando múltiplos processos tentam modificar os mesmos dados.
Quando essas métricas pioram, o próprio esquema frequentemente se torna o gargalo. Um design rígido otimizado para consultas complexas pode desmoronar sob o peso de atualizações constantes. Portanto, o ERD inicial deve levar em conta a velocidade da entrada de dados.
Normalização versus Trade-offs de Desempenho ⚖️
O projeto tradicional de banco de dados incentiva a normalização (1FN, 2FN, 3FN) para reduzir a redundância. Embora isso economize espaço de armazenamento e garanta consistência, introduz sobrecarga durante operações de escrita. Cada relação de chave estrangeira exige uma pesquisa e uma verificação de junção para manter a integridade referencial.
Em um ambiente de alta volume, essas verificações tornam-se custosas. Considere as implicações de uma relação muitos-para-muitos durante um evento de escrita:
- A tabela principal deve ser atualizada.
- A tabela de junção deve inserir uma nova linha.
- A segunda tabela deve verificar a relação.
- Os logs de transação devem registrar todas as alterações.
Cada etapa adiciona I/O de disco e ciclos de CPU. Para lidar com cargas pesadas de escrita, os projetistas frequentemente relaxam as regras de normalização. Esse processo envolve aceitar redundância de dados para reduzir o número de operações de escrita necessárias para armazenar uma unidade de informação.
Estratégias para Otimizar a Velocidade de Escrita ✍️
Vários padrões estruturais existem para mitigar a pressão de escrita. Essas estratégias focam em minimizar o tamanho de cada transação e reduzir a complexidade do trabalho do motor de armazenamento.
1. Particionamento e Sharding
Dividir uma tabela grande em pedaços menores e mais gerenciáveis permite que o banco de dados distribua a carga de escrita entre múltiplos segmentos físicos ou lógicos.
- Particionamento Horizontal: Dividir linhas com base em uma chave (por exemplo, intervalos de data, IDs de usuário).
- Particionamento Vertical: Mover colunas pouco acessadas para tabelas separadas.
- Sharding: Distribuir dados entre múltiplas instâncias de banco de dados.
Essa abordagem reduz o tamanho dos índices que precisam ser mantidos e limita o escopo dos bloqueios durante uma operação de escrita. Se um shard ficar saturado, os outros permanecem afetados.
2. Táticas de Denormalização
Armazenar dados redundantes permite que o sistema evite junções durante gravações. Por exemplo, em vez de calcular a soma total a partir das linhas relacionadas toda vez que chega uma nova transação, o sistema pode atualizar diretamente uma coluna de resumo previamente calculada.
- Colunas Computadas: Armazene valores derivados diretamente na linha.
- Visualizações Materializadas: Calcule previamente resultados para agregações frequentes.
- Contadores em Cache: Mantenha uma tabela separada de contadores para estatísticas.
Embora isso aumente os requisitos de armazenamento, reduz significativamente o custo de CPU da inserção.
3. Estratégia de Indexação
Índices aceleram leituras, mas retardam gravações. A cada vez que uma linha é inserida, o banco de dados deve atualizar cada índice associado. Em ambientes com alta taxa de gravação, o crescimento excessivo dos índices torna-se um problema importante.
- Minimize a Quantidade de Índices: Índice apenas colunas usadas para filtragem ou junção.
- Índices Parciais: Índice apenas um subconjunto de linhas que são frequentemente acessadas.
- Evite Indexação Excessiva: Pule índices em colunas que mudam frequentemente.
Comparando Abordagens de Design 📑
A tabela abaixo descreve o impacto das diferentes escolhas estruturais no desempenho de gravação e na integridade dos dados.
| Estratégia | Desempenho de Gravação | Integridade dos Dados | Custo de Armazenamento | Melhor Caso de Uso |
|---|---|---|---|---|
| Normalização Completa | Baixo | Alto | Baixo | Relatórios complexos, baixo volume de gravação |
| Denormalizado | Alto | Médio | Alto | Feed em tempo real, alto volume de escrita |
| Esquema particionado | Alto | Alto | Médio | Dados em série temporal, grandes conjuntos de dados |
| Tabelas largas | Médio-Alto | Médio | Médio | Padrões NoSQL, dados esparsos |
Gerenciamento de Chaves Estrangeiras e Restrições 🔗
A integridade referencial é um pilar do design relacional, mas impor restrições em cada inserção pode sobrecarregar uma pipeline de alta velocidade. O motor do banco de dados deve verificar se a linha pai referenciada existe antes de aceitar a linha filha.
Em cenários onde a integridade dos dados é crítica, mas a velocidade de gravação é prioritária, considere as seguintes ajustes:
- Restrições diferidas: Valide as relações no final de uma transação, em vez de imediatamente.
- Verificações em nível de aplicação: Verifique as relações no código da aplicação antes de enviar os dados para o banco de dados.
- Exclusão suave: Marque os registros como inativos em vez de removê-los para preservar os links referenciais sem sobrecarga de exclusão.
Remover as restrições completamente é arriscado, mas mover a lógica de validação às vezes pode melhorar o throughput. A decisão depende de quão crítica é a consistência imediata para o seu fluxo de trabalho específico.
Amplificação de escrita e motores de armazenamento 💾
Compreender como o motor de armazenamento lida com os dados é essencial. Muitos motores usam um Log de Escrita Antecipada (WAL) para garantir durabilidade. Isso significa que cada gravação é registrada antes de ser aplicada aos arquivos de dados reais.
Amplificação de escrita ocorre quando uma única operação lógica de gravação resulta em múltiplas gravações físicas. Isso é comum em motores de armazenamento com alta compactação. Para gerenciar isso:
- Inserções em lote: Agrupe múltiplas linhas em uma única transação.
- Escritas Sequenciais: Projete esquemas para favorecer a geração sequencial de chaves em vez de inserções aleatórias.
- Bufferização: Permita um buffer temporário na camada de aplicação para enfileirar gravações antes de descarregar.
Alinhando o design do ERD com os pontos fortes do motor de armazenamento, você pode minimizar o esforço físico necessário para persistir os dados.
Monitoramento e Iteração 🔄
Um esquema projetado para altas escritas não é estático. À medida que os padrões de tráfego mudam, o design pode precisar evoluir. O monitoramento contínuo da latência de escrita e da I/O do disco é essencial.
- Monitore a Latência de Escrita: Identifique picos que indicam gargalos.
- Monitore Esperas de Bloqueio: Detecte pontos de contenção onde processos estão bloqueados.
- Analise o Uso de Índices: Remova índices que nunca são usados para reduzir a sobrecarga de escrita.
Auditorias regulares do ERD garantem que a estrutura permaneça alinhada com as demandas operacionais atuais. Se uma tabela específica luta constantemente com a taxa de escrita, pode ser hora de revisitar a estratégia de particionamento ou o nível de normalização.
Resumo das Principais Considerações 🛠️
Projetar um ERD para escritas em grande volume exige uma mudança de mentalidade, passando da pureza pura dos dados para o throughput do sistema. Os seguintes pontos resumem as ações essenciais:
- Audite a Normalização: Garanta que cada relacionamento agregue valor, e não apenas complexidade.
- Planeje a Particionamento: Estruture chaves para permitir uma divisão horizontal fácil.
- Limite os Índices: Mantenha o caminho de escrita o mais enxuto possível.
- Abrace a Redundância: Use a denormalização para reduzir as dependências de junção durante a inserção.
- Valide Gradualmente: Mova a verificação de restrições para fora do caminho crítico de escrita, quando seguro.
Ao aplicar esses princípios, você cria um modelo de dados capaz de sustentar o crescimento sem sacrificar o desempenho. O objetivo não é eliminar a complexidade, mas gerenciá-la de forma que apoie a velocidade da sua aplicação.