










O desempenho do banco de dados muitas vezes depende de fatores invisíveis para o observador casual. Um desses fatores críticos é a concorrência de blocos. Quando múltiplos usuários ou processos tentam acessar os mesmos dados simultaneamente, o sistema deve impor regras para manter a integridade dos dados. Essas regras resultam em blocos. O bloqueio excessivo leva a gargalos, atrasando os tempos de resposta e frustrando os usuários finais. A causa raiz muitas vezes não está no hardware, mas no Diagrama Entidade-Relacionamento (ERD) que define a estrutura dos dados.
Um esquema bem projetado atua como a base para alta concorrência. Antecipando como os dados serão acessados e modificados, arquitetos podem estruturar as tabelas para minimizar conflitos. Esse método exige um profundo entendimento da isolamento de transações, estratégias de indexação e dos mecanismos físicos de bloqueio. O guia a seguir detalha como otimizar seu modelo de dados para melhor desempenho sem depender de ferramentas externas.
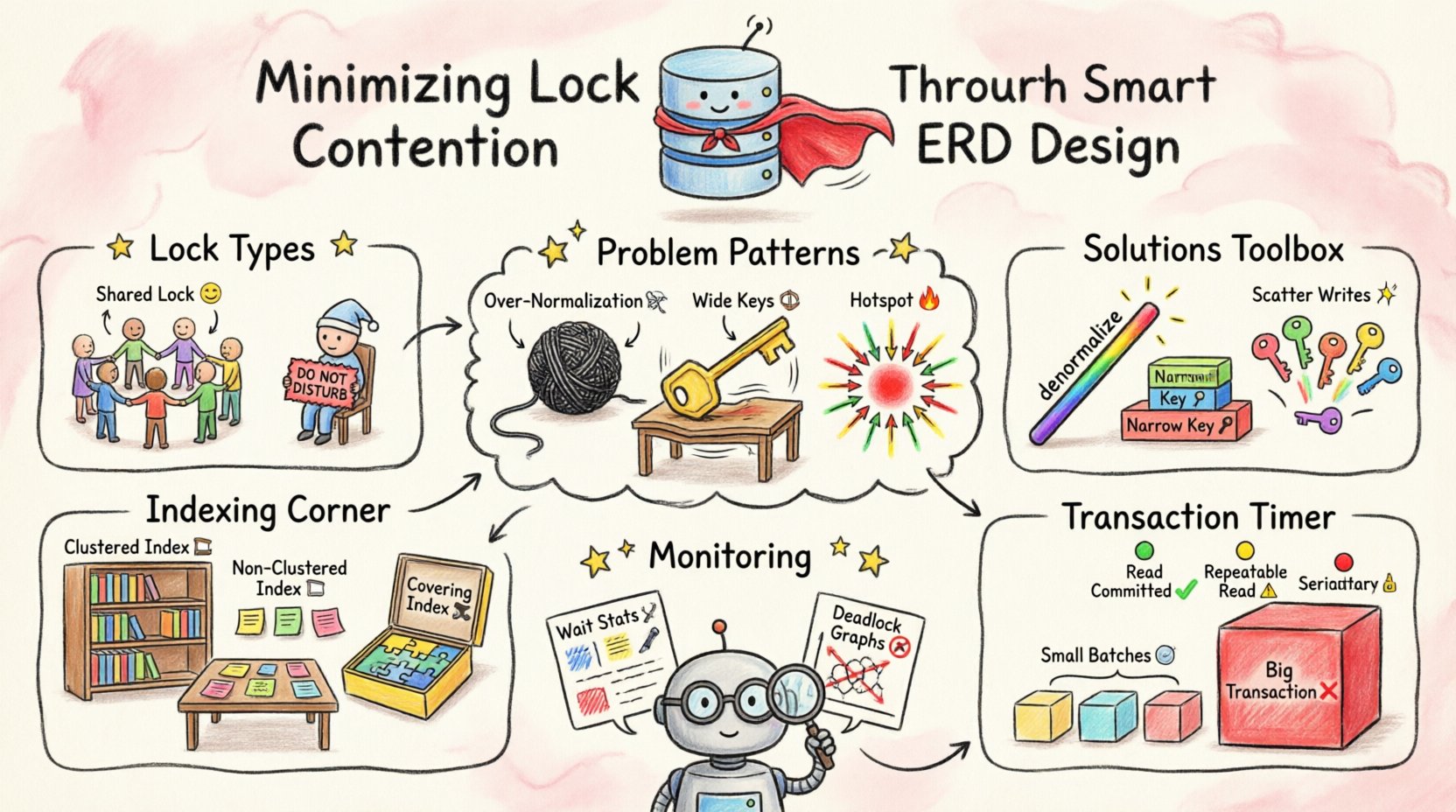
Compreendendo os Mecanismos de Bloqueio 🛡️
Antes de otimizar o projeto, é essencial entender o que os blocos realmente fazem. Bancos de dados usam blocos para prevenir inconsistências. Se duas transações tentarem atualizar a mesma linha exatamente no mesmo momento, ocorre um conflito. O sistema deve decidir quem vai primeiro.
- Blocos Compartilhados (S):Usado para leitura de dados. Várias transações podem manter blocos compartilhados no mesmo recurso simultaneamente.
- Blocos Exclusivos (X):Usado para gravação ou modificação de dados. Apenas uma transação pode manter um bloco exclusivo em um recurso de cada vez.
- Blocos de Intenção:Indicam que uma transação tem intenção de colocar um bloco em um nível inferior da hierarquia, como uma tabela ou página.
A concorrência de blocos surge quando a demanda por blocos exclusivos excede a capacidade de acesso compartilhado. Se o seu ERD obrigar o banco de dados a varrer grandes partes de uma tabela para encontrar dados, aumenta-se o escopo dos blocos mantidos. Isso amplia a probabilidade de colisões entre processos concorrentes.
Padrões de Esquema que Geram Concorrência 📉
Algumas escolhas de projeto aumentam inherentemente a área de superfície para bloqueio. Reconhecer esses padrões permite que você refatore cedo no ciclo de desenvolvimento.
1. Sobrenormalização
Embora a normalização reduza a redundância, a normalização excessiva pode prejudicar o desempenho. Unir muitas tabelas para recuperar um único registro exige o bloqueio de múltiplas linhas em várias tabelas. Se uma transação precisar ler dados de cinco tabelas normalizadas, ela adquire blocos em todas elas.
- O Risco:Se outra transação modificar uma dessas tabelas, a primeira transação pode precisar esperar.
- A Solução:Considere a desnormalização de colunas frequentemente unidas. Reduzir o número de junções reduz o número de blocos necessários por consulta.
2. Chaves Primárias Amplas
Chaves primárias são usadas para identificar linhas de forma única. Se uma chave primária for uma chave composta que abrange múltiplas colunas, isso afeta como os índices são construídos. Chaves amplas aumentam o tamanho do índice.
- O Risco:Índices maiores significam mais páginas para ler e bloquear durante pesquisas. Atualizações na chave primária podem desencadear alterações em cascata em tabelas relacionadas.
- A Solução:Use chaves substitutas simples e estreitas (como inteiros) sempre que possível. Mantenha chaves compostas mínimas e apenas quando logicamente necessárias.
3. Pontos Quentes em Chaves Sequenciais
Usar inteiros autoincrementais para chaves primárias é comum. No entanto, se o aplicativo insere dados sequencialmente, todas as novas gravações apontam para o final do índice. Isso cria um “ponto quente” onde muitas transações competem pelo mesmo página folha.
- O Risco:O motor do banco de dados deve bloquear a última página do índice para cada nova inserção.
- A Solução:Use chaves aleatorizadas ou distribuições baseadas em hash em cenários de alta escrita para espalhar a carga entre diferentes páginas.
Estratégias para Otimização de Esquema 🛠️
Otimizar o ERD envolve tomar decisões específicas sobre colunas, relacionamentos e restrições. A tabela abaixo apresenta decisões de design comuns e seu impacto no comportamento de bloqueio.
| Decisão de Design | Impacto no Bloqueio | Abordagem Recomendada |
|---|---|---|
| Restrições de Chave Estrangeira | Pode causar bloqueios em cascata em tabelas pai. | Use restrições diferidas ou validação em nível de aplicativo em sistemas de alta escrita. |
| Colunas Grandes de BLOB/Texto | Aumenta o tamanho da linha, exigindo mais páginas por linha. | Armazene dados grandes separadamente para manter a tabela principal estreita. |
| Colunas de Alta Cardinalidade | Pode levar ao uso ineficiente de índices. | Garanta que colunas seletivas sejam indexadas para evitar varreduras de tabela. |
| Valores Padrão | Atualiza linhas desnecessariamente se os valores padrão forem aplicados. | Permita valores NULL quando apropriado para evitar gatilhos de escrita. |
Desacoplamento dos Modelos de Escrita e Leitura
Separar o esquema usado para escrita do esquema usado para leitura pode reduzir significativamente a contenção. Modelos de escrita focam na integridade e normalização. Modelos de leitura focam na velocidade e desnormalização.
- Armazene dados em uma estrutura altamente normalizada para processamento de transações.
- Replicar dados para uma estrutura otimizada para leitura para relatórios ou exibição.
- Isso garante que consultas de leitura pesadas não bloqueiem operações de escrita.
Indexação e Escolha de Chaves 📊
Índices são vitais para o desempenho, mas não são gratuitos. Cada índice deve ser mantido durante uma atualização. Se uma tabela tiver muitos índices, cada inserção ou atualização exige o bloqueio de várias estruturas de índice.
Clusterizado vs. Não Clusterizado
- Índice Clusterizado: Determina a ordem física dos dados. Normalmente há apenas um por tabela. Escolha com cuidado, pois isso afeta como os dados são armazenados.
- Índice Não Clusterizado: Uma estrutura separada que aponta para dados. Útil para cobrir consultas sem tocar na tabela principal.
Evite criar índices em colunas que são frequentemente atualizadas. Quando o valor de uma coluna muda, o índice precisa ser reconstruído. Esse processo gera bloqueios de escrita na estrutura do índice.
Índices Cobertores
Um índice cobertor inclui todas as colunas necessárias para uma consulta. Isso permite que o banco de dados atenda à solicitação sem procurar os dados reais da tabela. Isso reduz o escopo dos bloqueios mantidos, pois o motor não precisa bloquear as linhas da tabela base.
- Identifique consultas de leitura frequentes.
- Crie índices que incluam os
SELECTcolunas. - Monitore os planos de execução de consultas para garantir que esses índices estejam sendo utilizados.
Escopo e Isolamento de Transações ⏱️
O diagrama ER influencia como as transações se comportam. Transações de longa duração mantêm bloqueios por períodos mais longos. Um esquema bem estruturado ajuda a manter as transações curtas.
Processamento em Lotes
Em vez de processar milhares de linhas em uma única transação, divida o trabalho em lotes menores. Isso libera os bloqueios mais cedo, permitindo que outros processos prosseguem.
- Limite o número de linhas modificadas por commit.
- Use cursores ou loops para processar dados em partes.
- Equilibre a sobrecarga de múltiplos commits com o benefício de reduzir a duração do bloqueio.
Níveis de Isolamento
Sistemas de banco de dados oferecem diferentes níveis de isolamento. Níveis de isolamento mais altos (como Serializable) impedem mais anomalias, mas aumentam o bloqueio. Níveis de isolamento mais baixos (como Read Committed) permitem mais concorrência.
- Evite Serializable, a menos que seja estritamente necessário para precisão financeira.
- Use Read Committed ou Repeatable Read para a maioria das tarefas operacionais.
- Alinhe o nível de isolamento com o requisito de negócios para consistência de dados.
Monitoramento e Iteração 🔄
O design não é uma atividade única. À medida que os padrões de uso mudam, também mudam os problemas de contenção de bloqueios. O monitoramento contínuo é necessário para manter o desempenho.
- Estatísticas de Espera:Monitore por quanto tempo as transações esperam por bloqueios.
- Gráficos de Deadlock:Analise diagramas que mostram quais consultas causaram deadlocks.
- Desempenho de Consultas:Identifique consultas lentas que podem estar mantendo bloqueios por mais tempo do que o esperado.
Revise regularmente o ERD em relação às métricas de desempenho atuais. Se uma tabela específica mostrar tempos de espera altos de forma consistente, considere particionar os dados ou ajustar o esquema para reduzir a carga.
Pensamentos Finais sobre Arquitetura de Dados 🧩
Minimizar a contenção de bloqueios é um equilíbrio entre a integridade dos dados e o throughput do sistema. Ao projetar esquemas levando em conta a concorrência, você reduz a necessidade de o motor do banco de dados resolver conflitos. Isso leva a tempos de resposta mais rápidos e a um sistema mais estável.
Comece auditando suas relações e chaves atuais. Procure oportunidades para simplificar as junções e reduzir o crescimento excessivo dos índices. Teste suas alterações em um ambiente de homologação para verificar o impacto no comportamento de bloqueio. Com planejamento cuidadoso e atenção aos detalhes, você pode construir uma camada de dados robusta que escala efetivamente.