











信頼性の高いデータシステムのアーキテクチャにおいて、エンティティ関係図(ERD)は基盤となる設計図として機能する。システムの複雑さが増し、データ量が増加するにつれて、クリーンなスキーマを維持することは極めて重要になる。大規模なERDにおける冗長性は、単にストレージの無駄という問題にとどまらない。それはシステム全体の不安定性の原因となる。同じデータポイントが同期メカニズムのない複数の場所に保存されている場合、データの不整合のリスクは急激に高まる。
本ガイドでは、高ボリュームのアプリケーションに必要な柔軟性を維持しつつ冗長性を最小限に抑えるために必要な技術的戦略を検討する。正規化の原則、構造的パターン、検証手法を検討することで、データモデルが時間の経過とともに安定した状態を保つことを確実にする。
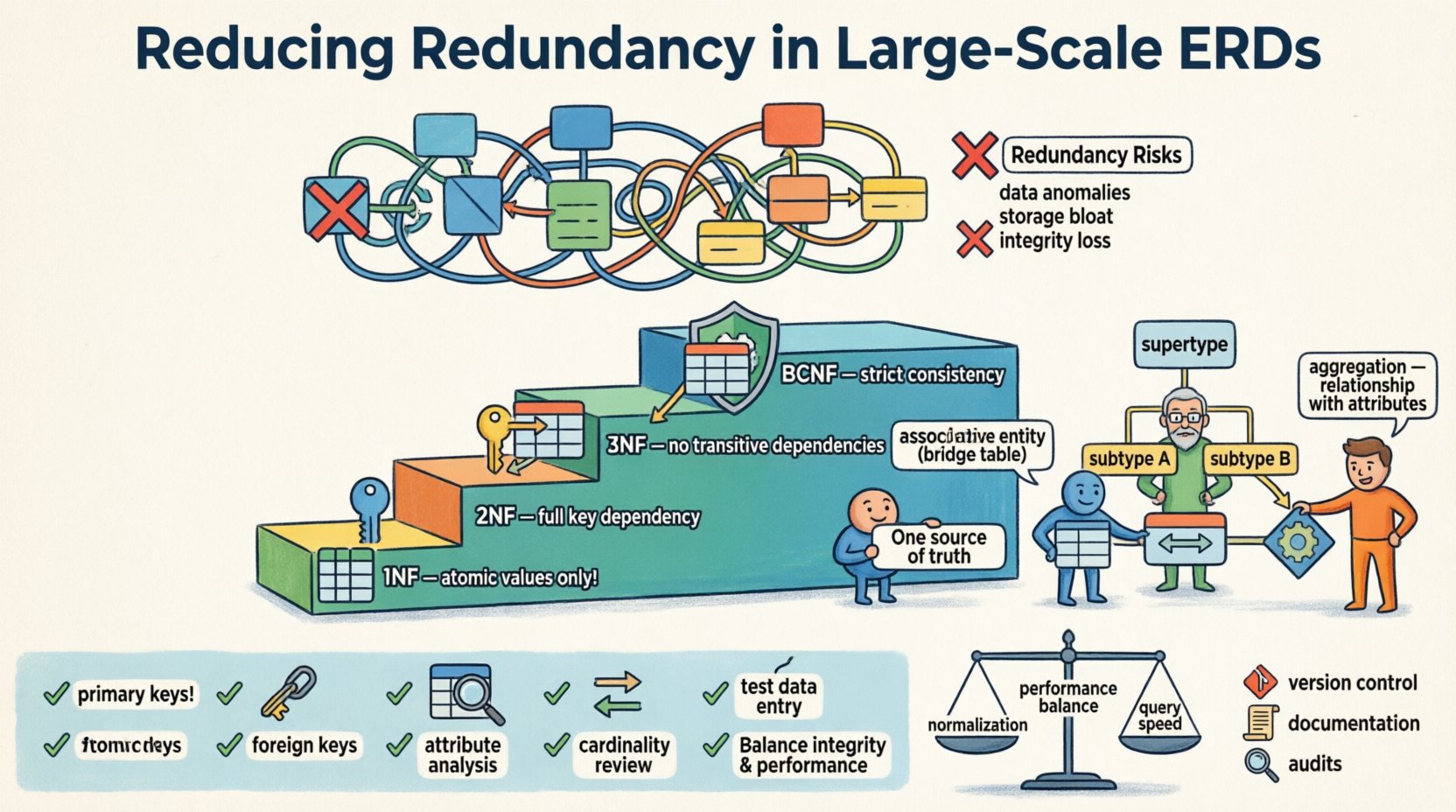
📉 データモデルにおける重複のコスト
冗長性とは、同じデータがデータベーススキーマ内で複数回保存される状態を指す。パフォーマンス最適化のためにある程度の非正規化は許容されるが、制御のない重複は、大規模な環境では顕著になるいくつかのリスクを引き起こす。
-
データ異常:ある場所での情報の更新が、他の場所での更新を伴わない場合、矛盾する記録が生じる。これを更新異常と呼ぶ。
-
挿入の問題:関連情報が他の場所に欠けているため、新しいデータを追加できないことがある。これを挿入異常と呼ぶ。
-
削除のリスク:レコードを削除すると、その行内に冗長に保存されていた固有の情報を誤って消去してしまう可能性がある。これを削除異常と呼ぶ。
-
ストレージの肥大化:同じ値を繰り返し保存すると、ディスク容量やメモリを無駄に消費する。
-
整合性の喪失:冗長なフィールド間で一意性を保証する制約がなければ、単一の真実の情報源が分散してしまう。
大規模な図において、これらの問題は相乗的に悪化する。重複した外部キーまたは記述的属性を持つ単一のテーブルが、メンテナンス作業中に連鎖的な障害を引き起こす可能性がある。目標は、データ整合性を保ちつつ、クエリ効率を犠牲にしないバランスを取ることである。
🔄 正規化の原則の理解
正規化とは、冗長性を低減し、依存関係の管理を改善するためにデータを整理するプロセスである。テーブルをより小さな、良好に構造化されたエンティティに分解することを含む。理論は1970年代にさかのぼるが、その原則は現代のスキーマ設計の基盤のままである。
第一正規形(1NF)
第一段階は原子性の確保である。各列は分割できない値を含む必要がある。セル内にリストを含むことはこの原則に違反する。たとえば、1つのフィールドに複数の電話番号を保存する場合、それらを別々の行または関連テーブルに分割する必要がある。
第二正規形(2NF)
1NFを満たした後、部分的依存関係に取り組む。テーブルが2NFにあるのは、1NFにあり、かつすべての非キー属性が主キーに完全に依存している場合である。複合キーの場合、属性はキーの一部に依存してはならない。
第三正規形(3NF)
これは一般的なトランザクションシステムで最も一般的な基準である。テーブルが3NFにあるのは、2NFにあり、かつ推移的依存関係がない場合である。より簡単に言えば、非キー属性は他の非キー属性に依存してはならない。もしAがBを決定するかつBがCを決定するならばAがCを決定するこれは冗長であるが、Bはキーです。
ボーイス・コッド正規形(BCNF)
BCNFは3NFのより厳格なバージョンです。複数の候補キーと重複する依存関係がある場合に対処できます。必ずしも必要とは限りませんが、論理的一貫性の最高レベルを保証します。
|
形式 |
焦点 |
重要な要件 |
冗長性への影響 |
|---|---|---|---|
|
1NF |
原子性 |
繰り返しグループなし |
基本構造 |
|
2NF |
部分的依存 |
主キーへの完全依存 |
分割キーの冗長性を軽減 |
|
3NF |
推移的依存 |
非キーはキーにのみ依存 |
属性の重複を排除 |
|
BCNF |
厳格な依存 |
すべての決定要因は候補キーである |
複雑な重複を最小限に抑える |
🏛️ スケーリング向けの高度な構造パターン
標準的な正規化はトランザクションデータベースには適していますが、大規模システムでは、過度な結合を生じさせずに複雑さを管理するために特定のパターンが必要な場合があります。
関連エンティティ
多対多の関係は、適切に処理されない場合、冗長性の主な原因になります。両方の関連テーブルに外部キーを追加するのではなく、関連テーブルを作成します。このテーブルには外部キーと、関係自体に特有の属性のみが含まれます。
-
利点:関係の属性の変更は、親エンティティの変更を必要としません。
-
利点:複数の行にわたって関係のメタデータが重複することを防ぎます。
サブタイプとスーパータイプ
エンティティが共通の属性を共有しているが、特定の変化がある場合、スーパータイプ/サブタイプパターンを使用することで、属性の重複を減らすことができます。特定のインスタンスにのみ適用されるオプションの列をメインテーブルに追加する代わりに、共有プライマリキーでリンクされたサブタイプ用の別々のテーブルを作成します。
-
利点:メインエンティティテーブルを整理整頓した状態に保ちます。
-
利点:親に影響を与えずに、サブタイプに対して特定の制約を適用できます。
集約
関係に属する属性が参加するエンティティではなく、関係自体に属する場合に集約が使用されます。大規模なERDでは、これ often は2つの主要なドメイン間の要約またはトランザクションリンクとして現れます。
🧩 大規模モデルにおける複雑さの管理
エンティティの数が増えるにつれて、適切に管理されない場合、図自体が負担になります。大規模なERDにはモジュール化戦略が必要です。
論理モデルと物理モデル
論理設計と物理的実装を分離します。論理モデルは特定のストレージメカニズムを気にせずにエンティティと関係に焦点を当てます。物理モデルはインデックス作成、パーティショニング、データ型を扱います。これらを明確に分けることで、物理的制約が論理的な重複を強いることを防ぎます。
モジュール設計
システムを機能ドメインに分割します。たとえば、ユーザー領域と請求領域を分離します。各ドメインは独自の内部整合性を維持します。ドメイン間のやり取りは共有テーブルではなく、定義されたインターフェースやキーを通じて行われます。
履歴データの取り扱い
データの履歴バージョンを保存すると、重複が生じる可能性があります。完全な行を複製するのではなく、バージョン管理用のカラムや別々の監査テーブルを使用します。これにより、現在の状態を保持しつつ、メインエンティティに過去のバージョンが散らばることを防ぎます。
🛠️ スキーマ設計における一般的な落とし穴
重複を避けるには注意が必要です。一般的なミスには以下が含まれます:
-
過剰な正規化:テーブルをあまりに細かく分割し、クエリに過剰な結合が必要になり、パフォーマンスが低下する。場合によっては、読み込みが重いワークロードでは、制御された範囲内の重複は正当化されることがあります。
-
関数的依存関係を無視する:どの属性がどのキーに依存しているかを特定できず、隠れた重複が生じます。
-
関心事の混同:ビジネスロジックの属性をデータモデルに配置する。属性はデータを記述すべきであり、プロセスを記述すべきではない。
-
ハードコードされた値:特定のステータスコードやカテゴリを参照テーブルではなく文字列として保存する。
✅ 検証および検証チェックリスト
大規模なERDを最終化する前に、厳密なレビューを行います。このチェックリストを使って設計を検証してください。
-
主キーを特定する:すべてのテーブルに一意の識別子があることを確認する。
-
外部キーを確認する:すべての関係がキーによって強制されていることを確認し、データの繰り返しによって強制されていないことを確認する。
-
属性を分析する:すべてのキー以外の属性が、キーに依存し、全体のキーに依存し、それ以外のものに依存しないかどうかを確認する。
-
基数を確認する:1対多の関係が複数の外部キーではなく、単一の外部キーで表現されていることを確認する。
-
データ入力をテストする:異常を検出するために、レコードの挿入、更新、削除をシミュレートする。
🔍 制約の役割
制約は設計の技術的実行である。一意制約は特定の列に重複値が入ることを防ぐ。外部キー制約は参照整合性を確保し、孤立レコードを防ぐ。大規模システムでは、制約の定義はスキーマ定義の一部として扱われるべきであり、後から追加するものではない。
さらに、値の範囲を制限するチェック制約を検討する。これにより、無効なデータがシステムに入ることを防ぎ、後でエラー処理コードの必要性を減らすことができる。
📈 パフォーマンスに関する考慮事項
正規化とパフォーマンスの間にはトレードオフがある。高度に正規化されたスキーマは、データを再構成するために結合(JOIN)を必要とする。読み込みが重い環境では、これにより応答時間が遅くなることがある。しかし、読み込みを高速化するために冗長性を追加すると、複数の場所を更新する必要があるため、書き込みが遅くなることがある。
現代のデータベースエンジンは結合を効率的に処理する。したがって、プロファイリングデータが特定のボトルネックを示さない限り、デフォルトのアプローチは正規化を優先すべきである。パフォーマンスが重要な場合は、コアスキーマ構造を変更するのではなく、マテリアライズドビューまたは読み取りレプリカを検討すべきである。
🔄 スキーマの時間経過に伴う維持
データベーススキーマは進化する。要件は変化し、新しいエンティティが出現する。時間の経過に伴って低冗長性を維持するために:
-
バージョン管理:スキーマ定義をコードとして扱う。変更をリポジトリで追跡する。
-
ドキュメント化:関係性や依存関係を記述した最新のドキュメントを維持する。
-
定期的な監査:ERDの定期的なレビューをスケジュールし、新しい冗長パターンを特定する。
これらの原則に従うことで、データアーキテクチャがスケーラブルであることを保証できる。きれいなERDは見た目の美しさだけの話ではない。ビジネスの成長に伴って、システムを理解しやすく、保守しやすく、拡張しやすいものにするためのものである。
🎯 データ整合性に関する最終的な考察
冗長性の削減は継続的なプロセスである。データがシステム内でどのように流れ、関係性がどのように相互作用するかを深く理解する必要がある。正規化ルールを適用し、高度な構造パターンを活用し、厳格な検証プロトコルを維持することで、長期的な安定性を支える基盤が築ける。きれいな設計に投資した努力は、保守コストの削減とデータ品質の向上という恩恵をもたらす。
まず論理的な関係性に注目する。物理的実装はその論理の反映であるべきであり、その論理の妥協ではない。ERD設計に対して厳格なアプローチを取ることで、冗長性は管理可能な変数となり、持続的な障害ではなくなる。