











टिकाऊ डेटा प्रणालियों की संरचना में, एंटिटी रिलेशनशिप डायग्राम (ERD) मूल नक्शा के रूप में कार्य करता है। जैसे-जैसे प्रणालियाँ जटिलता में बढ़ती हैं और डेटा का आयतन बढ़ता है, साफ स्कीमा बनाए रखना आवश्यक हो जाता है। बड़े पैमाने पर ERD में अतिरेक केवल बर्बाद स्टोरेज की बात नहीं है; यह प्रणालीगत अस्थिरता का कारण है। जब समान डेटा बिंदुओं को बिना सिंक्रनाइज़ेशन के तरीके के बिना कई स्थानों पर स्टोर किया जाता है, तो डेटा असंगति का खतरा तेजी से बढ़ जाता है।
यह गाइड तकनीकी रणनीतियों का अध्ययन करता है जो अतिरेक को कम करने के लिए आवश्यक हैं, जबकि उच्च आयतन वाले एप्लिकेशन के लिए आवश्यक लचीलापन को बनाए रखा जाए। हम नॉर्मलाइज़ेशन सिद्धांतों, संरचनात्मक पैटर्नों और सत्यापन विधियों का अध्ययन करेंगे ताकि आपका डेटा मॉडल समय के साथ स्थिर रहे।
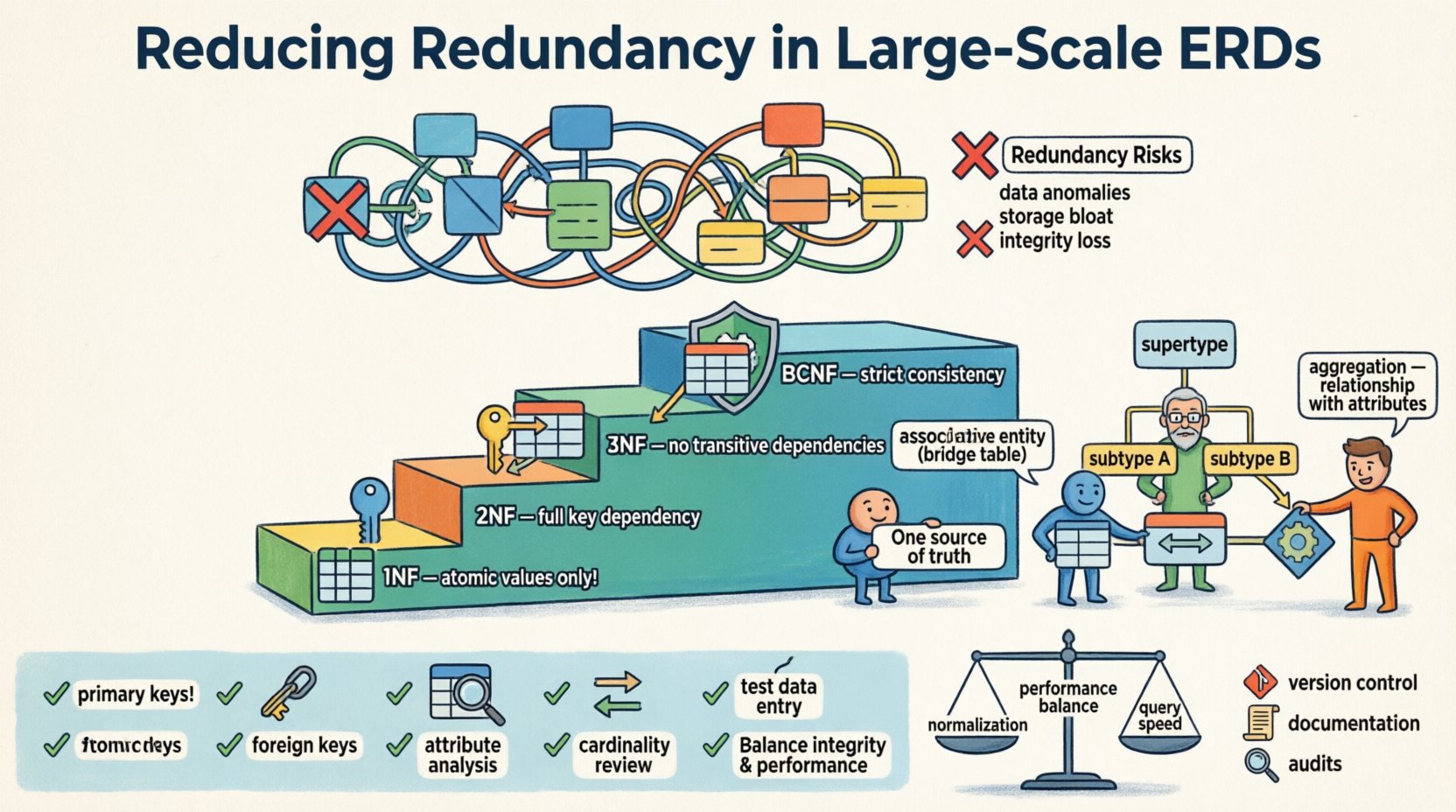
📉 डेटा मॉडल में डुप्लीकेशन की कीमत
अतिरेक तब होता है जब डेटाबेस स्कीमा के भीतर एक ही डेटा के एक से अधिक प्रतिलिपि स्टोर की जाती हैं। कुछ डेनॉर्मलाइज़ेशन प्रदर्शन अनुकूलन के लिए स्वीकार्य है, लेकिन नियंत्रण बिना डुप्लीकेशन कई जोखिम लाता है जो बड़े पैमाने पर परिवेशों में बढ़ जाते हैं।
-
डेटा विचलन:एक स्थान पर जानकारी अपडेट करना लेकिन दूसरे में नहीं करना विरोधाभासी रिकॉर्ड बनाता है। इसे अपडेट विचलन के रूप में जाना जाता है।
-
इन्सर्शन समस्याएं:कभी-कभी, आप नई जानकारी नहीं जोड़ सकते क्योंकि संबंधित जानकारी दूसरी जगह गायब है। इसे इन्सर्शन विचलन कहते हैं।
-
डिलीशन जोखिम:एक रिकॉर्ड हटाने से गलती से उस पंक्ति में स्टोर किए गए अद्वितीय जानकारी को मिटा दिया जा सकता है। इसे डिलीशन विचलन कहते हैं।
-
स्टोरेज ब्लॉट:एक ही मानों को बार-बार स्टोर करने से डिस्क स्पेस और मेमोरी का अनावश्यक उपयोग होता है।
-
पूर्णता का नुकसान:अतिरेक वाले क्षेत्रों में अद्वितीयता को बल देने वाले नियमों के बिना, सच्चाई का एकमात्र स्रोत टूट जाता है।
बड़े पैमाने पर डायग्राम में, इन समस्याओं का प्रभाव बढ़ता है। एक ही टेबल में डुप्लीकेट फॉरेन की या वर्णनात्मक विशेषताएं रखने से रखरखाव ऑपरेशन के दौरान कैस्केडिंग विफलताएं हो सकती हैं। लक्ष्य यह है कि डेटा पूर्णता को बनाए रखते हुए प्रश्न दक्षता को नहीं खोना।
🔄 नॉर्मलाइज़ेशन सिद्धांतों को समझना
नॉर्मलाइज़ेशन डेटा को व्यवस्थित करने की प्रक्रिया है जिससे अतिरेक को कम किया जाता है और निर्भरता प्रबंधन में सुधार होता है। इसमें टेबलों को छोटे, अच्छी तरह से संरचित एकांकों में विभाजित करना शामिल है। हालांकि सिद्धांत 1970 के दशक में शुरू हुए थे, लेकिन सिद्धांत आधुनिक स्कीमा डिज़ाइन की आधारशिला बने हुए हैं।
पहला सामान्य रूप (1NF)
पहला चरण परमाणुता सुनिश्चित करना है। प्रत्येक कॉलम में अविभाज्य मान होने चाहिए। एक ही सेल में सूचियां इस सिद्धांत का उल्लंघन करती हैं। उदाहरण के लिए, एक फील्ड में कई फोन नंबर स्टोर करने के लिए उन्हें अलग-अलग पंक्तियों या संबंधित टेबल में विभाजित करना आवश्यक है।
दूसरा सामान्य रूप (2NF)
जब 1NF पूरा हो जाता है, तो हम आंशिक निर्भरता को देखते हैं। एक टेबल 2NF में होती है यदि वह 1NF में है और सभी गैर-की विशेषताएं प्राथमिक की पर पूर्ण निर्भरता रखती हैं। संयुक्त की में, विशेषताएं केवल की के भाग पर निर्भर नहीं होनी चाहिए।
तीसरा सामान्य रूप (3NF)
यह सामान्य लेनदेन प्रणालियों के लिए सबसे आम मानक है। एक टेबल 3NF में होती है यदि वह 2NF में है और कोई अंतरित निर्भरता नहीं है। सरल शब्दों में, गैर-की विशेषताएं अन्य गैर-की विशेषताओं पर निर्भर नहीं होनी चाहिए। यदि A, B को निर्धारित करता है और B, C को निर्धारित करता है, तो A, C को निर्धारित करता है, जो अतिरिक्त है जब तक कि बी एक कुंजी है।
बॉयस-कॉड सामान्य रूप (BCNF)
BCNF, 3NF का अधिक कठोर संस्करण है। यह उन मामलों को संभालता है जहां कई उम्मीदवार कुंजियां हों और ओवरलैपिंग निर्भरताएं हों। हालांकि यह हमेशा आवश्यक नहीं है, लेकिन यह तार्किक सुसंगतता के उच्चतम स्तर को सुनिश्चित करता है।
|
रूप |
फोकस |
मुख्य आवश्यकता |
आवृत्ति पर प्रभाव |
|---|---|---|---|
|
1NF |
परमाणुता |
पुनरावृत्ति वाले समूह नहीं |
मूल संरचना |
|
2NF |
आंशिक निर्भरताएं |
प्राथमिक कुंजी पर पूर्ण निर्भरता |
विभाजित कुंजी आवृत्ति को कम करता है |
|
3NF |
स्थानांतरित निर्भरताएं |
गैर-कुंजियां केवल कुंजी पर निर्भर करती हैं |
लक्षण दोहराव को दूर करता है |
|
BCNF |
कठोर निर्भरताएं |
प्रत्येक निर्धारक एक उम्मीदवार कुंजी है |
जटिल ओवरलैप को न्यूनतम करता है |
🏛️ स्केल के लिए उन्नत संरचनात्मक पैटर्न
मानक सामान्यीकरण लेनदेन डेटाबेस के लिए अच्छा काम करता है, लेकिन बड़े पैमाने पर प्रणालियों को जटिलता को प्रबंधित करने के लिए विशिष्ट पैटर्न की आवश्यकता होती है बिना अत्यधिक जॉइन्स के बनाए रखने के लिए।
संबंधित एकताएं
अगर गलत तरीके से संभाला जाए, तो बहु-से-बहु संबंध आवृत्ति का मुख्य स्रोत हैं। दोनों संबंधित तालिकाओं में विदेशी कुंजियां जोड़ने के बजाय, एक संबंधित तालिका बनाएं। इस तालिका में केवल विदेशी कुंजियां और कोई भी लक्षण होंगे जो संबंध के लिए विशिष्ट हों।
-
लाभ:संबंध लक्षणों में परिवर्तन करने के लिए मूल एकताओं को बदलने की आवश्यकता नहीं होती है।
-
लाभ:कई पंक्तियों के माध्यम से संबंध विवरण के दोहराव को रोकता है।
उपप्रकार और सुपरप्रकार
जब संस्थाएँ सामान्य विशेषताएँ साझा करती हैं लेकिन विशिष्ट भिन्नताएँ होती हैं, तो सुपरप्रकार/उपप्रकार पैटर्न का उपयोग विशेषता दोहराव को कम करता है। मुख्य तालिका में केवल विशिष्ट उदाहरणों के लिए लागू होने वाले वैकल्पिक कॉलम जोड़ने के बजाय, साझा प्राथमिक कुंजी द्वारा जुड़े उपप्रकारों के लिए अलग-अलग तालिकाएँ बनाएँ।
-
लाभ:मुख्य संस्था तालिका को साफ रखता है।
-
लाभ:उपप्रकारों पर विशिष्ट सीमाएँ लागू करने की अनुमति देता है बिना माता-पिता के प्रभावित किए।
संग्रह
जब किसी संबंध की विशेषताएँ संबंध के लिए होती हैं, न कि संलग्न संस्थाओं के लिए, तो संग्रह का उपयोग किया जाता है। बड़े पैमाने पर ERD में, यह आमतौर पर दो प्रमुख क्षेत्रों के बीच सारांश या लेन-देन संबंध के रूप में दिखाई देता है।
🧩 बड़े मॉडलों में जटिलता का प्रबंधन
जैसे-जैसे संस्थाओं की संख्या बढ़ती है, यदि सही तरीके से प्रबंधित नहीं किया गया, तो आरेख स्वयं एक दोष बन जाता है। बड़े पैमाने पर ERD के लिए मॉड्यूलराइजेशन रणनीतियों की आवश्यकता होती है।
तार्किक बनाम भौतिक मॉडल
तार्किक डिज़ाइन को भौतिक कार्यान्वयन से अलग करें। तार्किक मॉडल केवल संस्थाओं और संबंधों पर ध्यान केंद्रित करता है, विशिष्ट भंडारण तकनीकों के बारे में चिंता नहीं करता है। भौतिक मॉडल इंडेक्सिंग, पार्टीशनिंग और डेटा प्रकारों का प्रबंधन करता है। इन्हें अलग रखने से भौतिक सीमाओं के तार्किक अतिरेक को बाधित करने से बचा जा सकता है।
मॉड्यूलर डिज़ाइन
प्रणाली को कार्यात्मक क्षेत्रों में बाँटें। उदाहरण के लिए, उपयोगकर्ता क्षेत्र को बिलिंग क्षेत्र से अलग करें। प्रत्येक क्षेत्र अपनी आंतरिक सुसंगतता बनाए रखता है। क्षेत्रों के बीच बातचीत प्राप्त की गई इंटरफेस या कुंजियों के माध्यम से होती है, साझा तालिकाओं के बजाय।
ऐतिहासिक डेटा का प्रबंधन
डेटा के ऐतिहासिक संस्करणों को संग्रहीत करने से अतिरेक बन सकता है। पूरी पंक्तियों को दोहराने के बजाय, संस्करण वाले कॉलम या अलग ऑडिट तालिकाओं का उपयोग करें। इससे वर्तमान स्थिति को बनाए रखा जाता है बिना मुख्य संस्था को पिछले संस्करणों से भरे रहने दिए।
🛠️ स्कीमा डिज़ाइन में आम त्रुटियाँ
अतिरेक से बचने के लिए सतर्कता की आवश्यकता होती है। आम गलतियाँ इस प्रकार हैं:
-
अत्यधिक सामान्यीकरण:तालिकाओं को इतना बारीकी से विभाजित करना कि प्रश्नों के लिए अत्यधिक जॉइन की आवश्यकता हो, जिससे प्रदर्शन खराब होता है। कभी-कभी, पढ़ने वाले कार्यभार के लिए नियंत्रित मात्रा में अतिरेक उचित हो सकता है।
-
क्रियात्मक निर्भरता को नजरअंदाज करना:किन विशेषताओं का किन कुंजियों पर निर्भरता है, इसकी पहचान न करने से छिपे हुए दोहराव बनते हैं।
-
चिंताओं का मिश्रण:व्यापार तर्क विशेषताओं को डेटा मॉडल में रखना। विशेषताएँ डेटा का वर्णन करनी चाहिए, प्रक्रिया का नहीं।
-
कड़े मूल्य:एक लुकअप तालिका के संदर्भ के बजाय विशिष्ट स्थिति कोड या श्रेणियों को स्ट्रिंग के रूप में संग्रहीत करना।
✅ सत्यापन और मान्यता चेकलिस्ट
बड़े पैमाने पर ERD को अंतिम रूप देने से पहले एक कठोर समीक्षा करें। अपने डिज़ाइन की मान्यता के लिए इस चेकलिस्ट का उपयोग करें।
-
प्राथमिक कुंजियों को पहचानें: सुनिश्चित करें कि प्रत्येक तालिका का एक अद्वितीय पहचानकर्ता हो।
-
पराजय कुंजियों की जांच करें: सुनिश्चित करें कि सभी संबंध कुंजियों द्वारा बल दिया जाता है, डेटा को दोहराकर नहीं।
-
गुणों का विश्लेषण करें: प्रत्येक गैर-कुंजी विशेषता के कुंजी पर, पूरी कुंजी पर और केवल कुंजी पर निर्भर होने के बारे में पूछें।
-
कार्डिनैलिटी की समीक्षा करें: सुनिश्चित करें कि एक से बहुत के संबंधों को एकल पराजय कुंजी द्वारा दर्शाया जाता है, बहुत से नहीं।
-
डेटा प्रविष्टि का परीक्षण करें: विचित्रताओं की जांच के लिए रिकॉर्ड्स के इन्सर्ट, अपडेट और डिलीट के सिमुलेशन करें।
🔍 प्रतिबंधों की भूमिका
प्रतिबंध डिज़ाइन के तकनीकी बल हैं। यूनिक प्रतिबंध विशिष्ट कॉलम में डुप्लीकेट मानों को रोकते हैं। पराजय कुंजी प्रतिबंध प्रतिबंधात्मक अखंडता सुनिश्चित करते हैं, जिससे अनाथ रिकॉर्ड्स को रोका जाता है। बड़े प्रणालियों में, प्रतिबंध परिभाषाओं को स्कीमा परिभाषा का हिस्सा होना चाहिए, बाद में ध्यान देने वाली बात नहीं।
साथ ही, मानों की सीमा को सीमित करने के लिए चेक प्रतिबंधों पर विचार करें। इससे अमान्य डेटा के प्रणाली में प्रवेश को रोका जाता है, जिससे बाद में त्रुटि संभालने वाले कोड की आवश्यकता कम होती है।
📈 प्रदर्शन पर विचार
नॉर्मलाइजेशन और प्रदर्शन के बीच एक व्यापार बनावट है। उच्च रूप से नॉर्मलाइज्ड स्कीमा डेटा को पुनर्निर्माण करने के लिए जॉइन की आवश्यकता होती है। पढ़ने वाले वातावरण में, इससे प्रतिक्रिया समय धीमा हो सकता है। हालांकि, पढ़ने को तेज करने के लिए अतिरिक्त डुप्लीकेशन जोड़ने से लेखन को धीमा कर सकता है, क्योंकि बहुत स्थानों को अपडेट करने की आवश्यकता होती है।
आधुनिक डेटाबेस इंजन जॉइन को कुशलतापूर्वक संभालते हैं। इसलिए, डिफ़ॉल्ट दृष्टिकोण नॉर्मलाइजेशन के पक्ष में होना चाहिए, जब तक कि प्रोफ़ाइलिंग डेटा किसी विशिष्ट बाधा को नहीं दर्शाता। यदि प्रदर्शन महत्वपूर्ण है, तो मूल स्कीमा संरचना को बदलने के बजाय मैटेरियलाइज्ड दृश्य या रीड रिप्लिका के बारे में सोचें।
🔄 समय के साथ स्कीमा का रखरखाव
डेटाबेस स्कीमा विकसित होते हैं। आवश्यकताएं बदलती हैं, और नए एंटिटीज उभरते हैं। समय के साथ कम डुप्लीकेशन को बनाए रखने के लिए:
-
संस्करण नियंत्रण: स्कीमा परिभाषाओं को कोड के रूप में लें। एक रिपोजिटरी में बदलावों को ट्रैक करें।
-
दस्तावेज़ीकरण: संबंधों और निर्भरताओं का वर्णन करने वाला अद्यतन दस्तावेज़ीकरण बनाए रखें।
-
नियमित ऑडिट: नए डुप्लीकेशन पैटर्न की पहचान करने के लिए ईआरडी की नियमित समीक्षा योजना बनाएं।
इन सिद्धांतों का पालन करके, आप सुनिश्चित करते हैं कि डेटा संरचना स्केलेबल बनी रहे। एक साफ ईआरडी केवल अद्वितीयता के बारे में नहीं है; यह एक ऐसी प्रणाली बनाने के बारे में है जो व्यवसाय के विकास के साथ समझने, रखरखाव और विस्तार करने में आसान हो।
🎯 डेटा अखंडता पर अंतिम विचार
डुप्लीकेशन को कम करना एक निरंतर प्रक्रिया है। इसके लिए यह समझने की आवश्यकता होती है कि डेटा प्रणाली में कैसे प्रवाहित होता है और संबंध कैसे बातचीत करते हैं। नॉर्मलाइजेशन नियमों के अनुप्रयोग, उन्नत संरचनात्मक पैटर्नों के उपयोग और सख्त मान्यता प्रक्रियाओं को बनाए रखने से आप लंबे समय तक स्थिरता के लिए आधार बनाते हैं। साफ डिज़ाइन में निवेश की गई मेहनत कम रखरखाव लागत और उच्च डेटा गुणवत्ता में लाभ देती है।
पहले तार्किक संबंधों पर ध्यान केंद्रित करें। भौतिक कार्यान्वयन को उस तर्क का प्रतिबिंब बनने दें, उसके त्याग के बजाय। ईआरडी डिज़ाइन के एक अनुशासित दृष्टिकोण के साथ, डुप्लीकेशन एक प्रबंधनीय चर बन जाता है, न कि एक लगातार बाधा।