











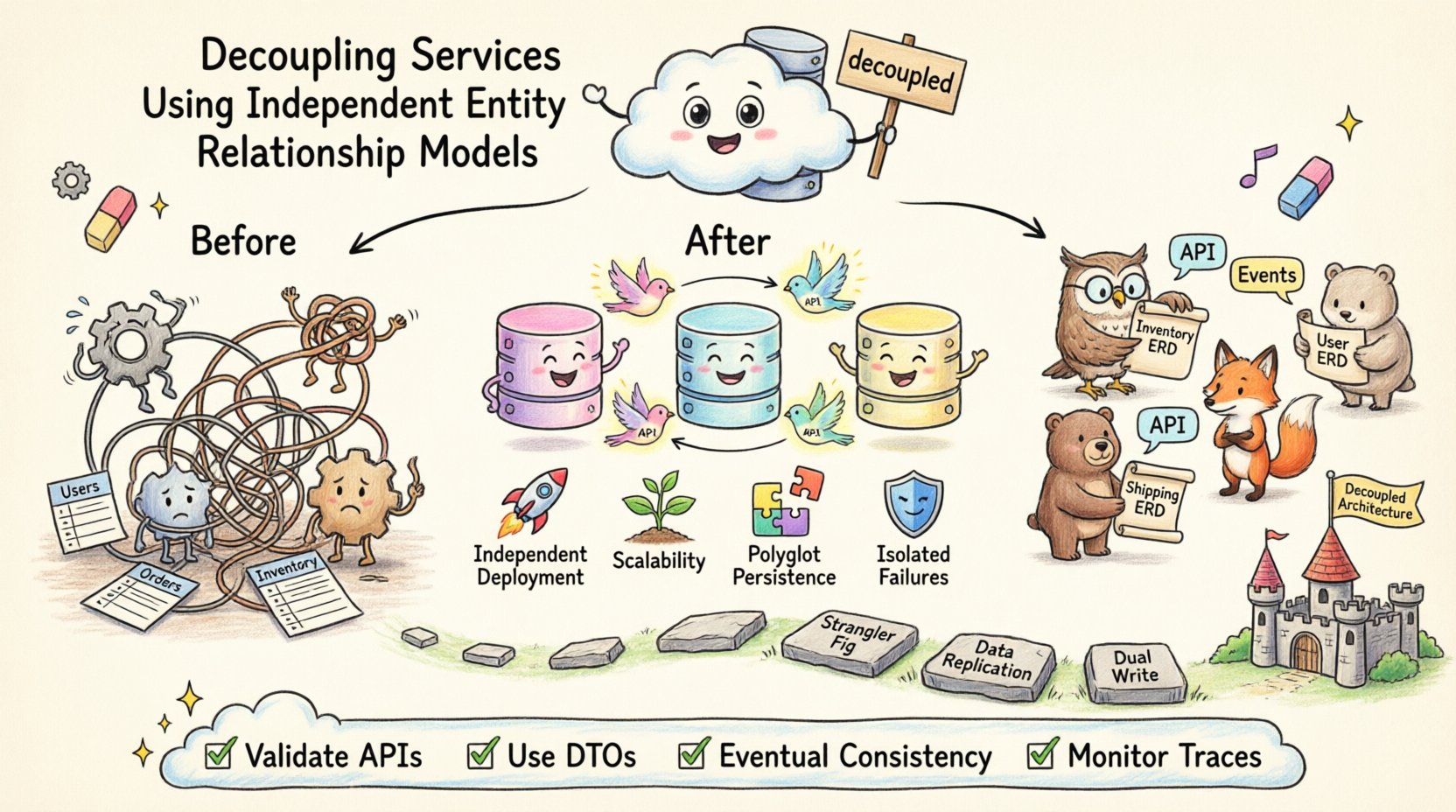
Dans l’architecture logicielle moderne, la séparation des préoccupations s’étend au-delà de la logique du code jusqu’à la propriété des données. Lorsque les services partagent un schéma de base de données unique, ils deviennent inévitablement dépendants des implémentations internes les uns des autres. Ce couplage étroit crée de la fragilité, freine la vitesse de déploiement et complique les efforts d’évolutivité. Pour atteindre une véritable modularité, les équipes doivent adopter des modèles d’entités relationnelles indépendants pour chaque frontière de service. Cette approche garantit que les structures de données restent privées au service qui les possède, favorisant ainsi la résilience et l’autonomie.
🤔 Le défi des données partagées
Les systèmes hérités reposent souvent sur une base de données monolithique où plusieurs modules d’application interrogent les mêmes tables. Bien que cela simplifie le développement initial, cela introduit des risques importants à mesure que le système grandit. Un changement dans les exigences de données d’un module peut rompre la fonctionnalité d’un autre module qui dépend de la même structure de table. Ce phénomène est connu sous le nom de anti-pattern base de données partagée.
Prenons un scénario où le service Utilisateur doit ajouter un nouveau champ à la table du profil. Si le service Commande interroge directement cette table pour obtenir les noms d’utilisateurs, la mise à jour pourrait nécessiter un déploiement coordonné ou une migration de base de données qui affecte simultanément les deux équipes. Ce surcroît de coordination ralentit l’innovation et augmente le risque d’incidents en production.
-
Dépendances de déploiement :Les services ne peuvent pas être déployés de manière indépendante s’ils partagent des définitions de schéma.
-
Limites d’évolutivité :Une seule base de données devient souvent un goulot d’étranglement lorsque certains services nécessitent plus de ressources que d’autres.
-
Risques de sécurité :L’accès direct aux tables contourne la couche de service, exposant potentiellement la logique sensible des données.
🗺️ Définition de modèles d’entités relationnelles indépendants
Un modèle d’entités relationnelles indépendant (ERD) attribue un schéma de données spécifique à un seul service. Cela signifie que le service contrôle sa propre base de données, ses propres tables et ses propres relations. Les autres services n’ont pas d’accès direct à ces tables. À la place, ils interagissent à travers des interfaces définies, telles que des API ou des files de messages.
Ce style architectural est souvent appelé Base de données par service. Il aligne la propriété des données avec les capacités métiers. Par exemple, un service Inventaire gère les niveaux de stock, tandis qu’un service Livraison gère les adresses de livraison. Aucun de ces services ne devrait contenir de référence clé étrangère vers les tables internes de l’autre.
Le processus implique :
-
Définition des frontières :Déterminer quelles données appartiennent à quelle capacité métier.
-
Conception des schémas locaux :Créer des ERD qui ne répondent qu’aux besoins spécifiques de ce service.
-
Définition des interfaces :Établir la manière dont les données sont échangées entre les services sans exposer leurs structures internes.
📈 Principaux avantages de l’isolement des schémas
Adopter des ERD indépendants transforme la manière dont les équipes gèrent la complexité. Cela déplace l’accent du contrôle centralisé vers une autonomie distribuée. Chaque équipe peut optimiser sa stratégie de stockage des données sans se soucier des impacts globaux.
|
Aspect |
Modèle base de données partagée |
Modèle ERD indépendant |
|---|---|---|
|
Déploiement |
Coordonné, risqué |
Indépendant, fréquent |
|
Évolutivité |
Horizontal uniquement (cluster) |
Vertical par service |
|
Technologie |
Type de base de données unique |
Persistence polyglotte |
|
Domaine de défaillance |
Point de défaillance unique |
Défaillances isolées |
🔗 Conception pour un couplage faible
Lorsque les services ne peuvent pas communiquer directement avec les bases de données des autres, ils doivent communiquer par le biais d’API. Cela exige une conception soigneuse du contrat entre les services. L’API devient le seul contrat partagé. Si le contrat de l’API reste stable, le modèle de données sous-jacent peut évoluer sans affecter les consommateurs.
Versioning de l’API : Étant donné que les modèles de données évoluent, les API doivent supporter le versioning. Cela permet aux anciens clients de fonctionner tandis que les nouveaux clients adoptent des structures mises à jour.
Objets de transfert de données (DTO) : Ne pas exposer directement les objets entité. Créer des DTO spécifiques qui ne transportent que les données nécessaires au consommateur. Cela empêche les modifications internes de se propager à l’extérieur.
-
Validation : Valider les entrées à la frontière de l’API, et non uniquement au niveau de la base de données.
-
Idempotence : Assurer que les opérations peuvent être répétées en toute sécurité sans provoquer de doublons.
-
Documentation : Maintenir une documentation claire pour tous les formats d’échange de données.
⚖️ Gestion des transactions et de la cohérence
L’un des défis les plus importants du découplage est le maintien de l’intégrité des données. Dans une base de données partagée, une transaction peut facilement s’étendre sur plusieurs tables. Dans un système distribué, une transaction logique unique peut s’étendre sur plusieurs services. Cela est connu sous le nom de Problème de transaction distribuée.
Pour résoudre ce problème, les équipes adoptent souvent la Consistance éventuelle modèle. Au lieu de garantir que les données soient identiques partout immédiatement, le système s’assure qu’elles deviennent cohérentes au fil du temps. Cela est réalisé grâce à la messagerie asynchrone.
Modèle Saga :Une saga est une séquence de transactions locales. Chaque transaction met à jour la base de données et publie un événement pour déclencher la transaction suivante. Si une étape échoue, des transactions compensatoires sont exécutées pour annuler les modifications précédentes.
-
Modèle Outbox :Écrire les événements dans une table locale aux côtés du changement principal des données. Un processus en arrière-plan publie ces événements, garantissant qu’aucune donnée ne soit perdue.
-
Consommateurs idempotents :Les gestionnaires de messages doivent gérer les messages en double de manière appropriée.
-
Actions compensatoires :Définir une logique de retour en arrière claire pour chaque action en avant.
🚚 Stratégies de migration
Passer d’une base de données partagée à des modèles conceptuels de données indépendants est une entreprise importante. Elle nécessite une approche progressive pour minimiser les risques. Hâter la migration peut entraîner une perte de données ou des interruptions de service.
Modèle Figuier étrangleur :Déplacer progressivement les fonctionnalités vers de nouveaux services. Commencez par une fonctionnalité spécifique, comme les notifications utilisateur. Créez un nouveau service avec son propre modèle conceptuel de données pour cette fonctionnalité. Redirigez le trafic vers le nouveau service tout en maintenant le système hérité en fonctionnement.
Réplication des données :Pendant la transition, vous devrez peut-être maintenir la synchronisation des données entre les anciennes et les nouvelles bases de données. Cela permet au nouveau service de lire les données du système ancien temporairement pendant qu’il remplit sa propre base.
Écriture double :Écrire simultanément dans les anciennes et les nouvelles bases de données pendant la fenêtre de migration. Vérifiez que le nouveau service fonctionne correctement avant de désactiver les écritures anciennes.
🔍 Surveillance et maintenance
Avec des magasins de données indépendants, la surveillance devient plus complexe. Vous ne consultez plus un seul tableau de bord de santé de base de données. Vous devez agréger les journaux et les métriques provenant de plusieurs sources.
Suivi distribué :Mettre en œuvre le suivi pour suivre une requête à mesure qu’elle passe à travers différents services. Cela aide à identifier quel service est à l’origine de la latence ou des erreurs.
Registre de schémas :Maintenir un registre des contrats API. Cela garantit que tout changement apporté à un modèle de données est examiné et approuvé avant le déploiement.
-
Alertes :Configurer des alertes pour le retard de réplication et les files d’attente de messages encombrées.
-
Planification de la capacité :Surveiller la croissance du stockage par service pour éviter des coûts imprévus.
-
Stratégies de sauvegarde :S’assurer que chaque service dispose de son propre plan de sauvegarde et de récupération.
🛠️ Pièges courants à éviter
Même avec un plan solide, les équipes ont souvent des difficultés lors de la mise en œuvre. Comprendre ces erreurs courantes peut faire économiser un temps et un effort considérables.
-
Couplage caché :Évitez d’utiliser des vues de base de données ou des tables partagées, même si elles se trouvent dans des schémas distincts. L’accès direct à la base de données doit être interdit.
-
Sur-fragmentation :Ne créez pas une nouvelle base de données pour chaque petite fonction. Regroupez les entités liées dans des services logiques.
-
Ignorer la latence :Les appels réseau sont plus lents que les requêtes locales. Concevez vos API pour minimiser les allers-retours.
-
Requêtes complexes :Évitez les jointures entre services. Si vous avez besoin de données provenant de plusieurs services, interrogez-les séparément et fusionnez les résultats au niveau de la couche application.
🧱 Réflexions finales
Découpler les services en utilisant des modèles indépendants de relations entre entités est une décision stratégique qui se révèle payante à long terme. Cela exige une discipline dans la conception et une volonté de gérer la complexité distribuée. Toutefois, le résultat est un système plus facile à mettre à l’échelle, plus résilient aux pannes et plus rapide à évoluer. En assumant la propriété de leurs données, les services acquièrent l’autonomie nécessaire pour innover sans coordination constante.
Commencez par identifier les frontières les plus critiques de votre système. Isolez tout d’abord les données de ces services. Affinez vos contrats d’API et vos modèles de communication au fur et à mesure. Cette approche progressive garantit la stabilité tout en avançant vers une architecture entièrement découpée.