











堅牢なデータベースを設計するには、最初のクエリが実行される前から準備が必要です。その出発点は、ブループリントであるエンティティ関係図(ERD)です。多くの開発者がテーブルの作成やカラムの型に注目する中で、真のパフォーマンスの源は、インデックスがデータモデルとどのように整合しているかにあります。インデックスは単なる設定項目ではなく、論理的な関係の物理的表現なのです。
ER図を構造化する際、データの基数と接続性を定義します。これらの構造的選択が、最も効率的なインデックス戦略を決定します。1対1の関係と、多対多の結合では、異なるアプローチが必要です。これらの微細な点を無視すると、結合が遅くなり、I/Oが過剰になり、ストレージが断片化する原因になります。このガイドでは、特定のベンダー製ツールに依存せずに、ER図を高性能なインデックスパターンに変換する方法を解説します。
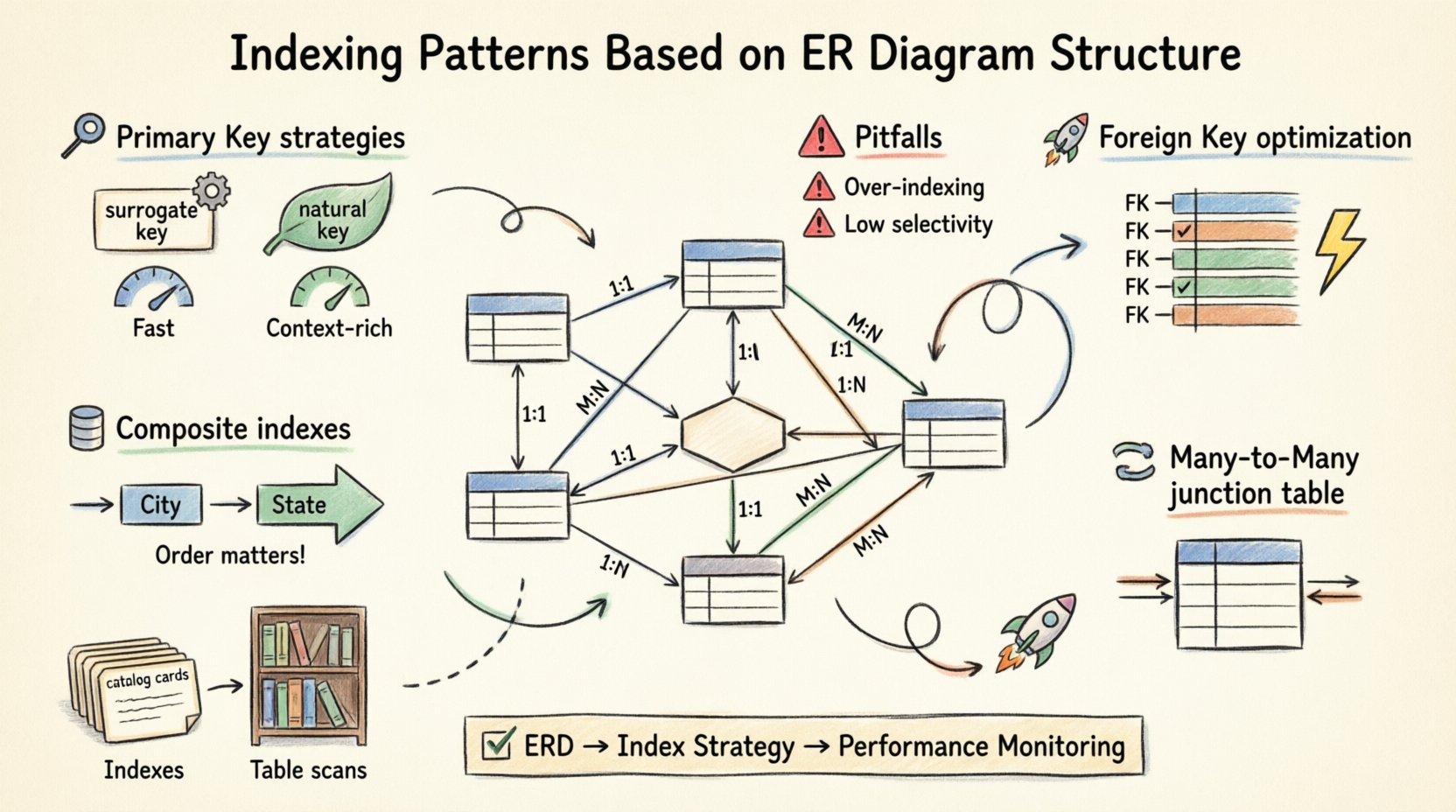
🔑 基盤を理解する:ER図とインデックス
ER図は視覚的補助以上のものであり、アプリケーションロジックとストレージエンジンとの契約です。エンティティ間の線が引かれるたびに、データベースが強制しなければならない制約が存在します。インデックスは、これらの制約の強制を高速化し、それらを跨いでデータを取得する速度を向上させます。
ストレージ層を図書館に例えると、インデックスがなければ、本を探すにはすべての棚をスキャンする必要があります(フルテーブルスキャン)。インデックスはカタログカードです。しかし、検索キーが著者であるのに、ジャンルでカタログカードを配置してしまうと、システムは非効率になります。ER図は、著者やジャンルが誰であるか、そしてどの関係が最も重要であるかを教えてくれます。
重要な考慮事項には以下が含まれます:
- 基数:高い基数を持つカラム(一意の値)は、インデックスの恩恵を最も受けます。
- 結合頻度:頻繁に結合されるテーブルは、外部キーに特定のインデックスを設定する必要があります。
- 書き込み量:すべてのインデックスは、挿入および更新操作にオーバーヘッドを追加します。
- クエリパターン:どのようにフィルタリングしますか?どのようにソートしますか?ER図がその答えを示唆しています。
🏗️ 主キーインデックス戦略
主キー(PK)は、すべてのテーブルの骨格です。一意性を保証し、多くのシステムではデータストレージのクラスタリングメカニズムを提供します。インデックス戦略をPKの定義に合わせることは、最初のステップです。
1. 代替キー vs. 自然キー
代替キー(自動増加ID)と自然キー(メールアドレスや社会保障番号など)の選択は、インデックスのパフォーマンスに大きく影響します。
- 代替キー:これらはクラスタリングに理想的です。短く、単調に増加し、順序立てられています。これにより、書き込み時のページ分割や断片化を最小限に抑えることができます。 📈
- 自然キー:意味的に意味のある一方で、長くなる可能性があり、長さが変動したり、変更されやすい場合があります。それらにインデックスを設定すると、整数ベースのキーと比較して、インデックスサイズが大きくなり、検索が遅くなる可能性があります。
2. クラスタードインデックスの影響
多くのアーキテクチャでは、主キーがクラスタードインデックスを定義します。これは、実際のデータ行がキーの順序で物理的に格納されることを意味します。もしER図から、特定の自然属性で頻繁にフィルタリングするクエリがあると予想される場合、主キーの定義を再検討するか、クラスタードインデックスが1つのクエリタイプに最適化される一方で、サブインデックスが他のクエリを処理することを受け入れる必要があります。
🔗 外部キーの最適化
外部キー(FK)は、テーブル間の関係を定義します。インデックスがなければ、これがパフォーマンスのボトルネックとなる最も一般的な原因です。2つのテーブルを結合する際、データベースエンジンはFKカラムに基づいて行をマッチングしなければなりません。インデックスがなければ、この操作はネストされたループスキャンに劣化し、大規模なデータセットでは計算コストが非常に高くなります。
1. 外部キー列へのインデックス化
子テーブルの外部キー列には、常にインデックスを作成してください。これにより、エンジンは全テーブルをスキャンせずに、関連する行を迅速に検索できます。
| シナリオ | インデックス作成の要件 | パフォーマンスへの影響 |
|---|---|---|
| 1対多(子) | 子テーブルの外部キーにインデックスを設定 | 親データの高速検索を可能にする |
| 多対1(親) | 親テーブルの主キーにインデックスを設定(通常はデフォルト) | 標準の主キー動作 |
| 連鎖削除 | 外部キーと親の主キーにインデックスを設定 | 削除時にテーブル全体をロックするのを防ぐ |
2. 複合外部キー
場合によっては、関係が複数の列に依存する(例:親テーブルからの複合キー)。この場合、親キーの列と順序と一致するように、子テーブルに複合インデックスを作成する必要があります。インデックス内の列の順序が一致しないと、結合操作にインデックスが役立たなくなることがあります。
🔀 多対多関係の処理
多対多(M:N)関係は、中間テーブルによって解決されます。このテーブルには、両方の親テーブルを指す外部キーが含まれます。ここでのインデックス戦略はパフォーマンスにとって極めて重要です。
以下の状況を考えてみましょう:生徒に登録する授業。中間テーブルがそれらをリンクします。生徒のすべての授業を検索するには、中間テーブルを効率的にクエリする必要があります。
- 双方向インデックス:両方の外部キー列を個別にインデックス化するべきです。これにより、フルスキャンなしにどちらの方向からでも関係をクエリできます(生徒→授業、または授業→生徒)。
- 複合インデックス:クエリが常に特定の生徒の授業を取得する場合、(生徒ID、授業ID) に複合インデックスを設定すると、2つの別々のインデックスよりも効率的です。1回の検索で検索条件をすべてカバーできます。
📊 複合インデックスとカバーインデックス
すべてのクエリが1つの列でフィルタリングするわけではありません。複雑なクエリはしばしば複数の条件を含みます。ここが複合インデックスの強みです。複合インデックスは複数の列に基づいて構築された単一のインデックスです。
1. 列の順序が重要
複合インデックス内の列の順序は任意ではありません。データベースエンジンは、等価条件が終了する点までしかインデックスを利用できません。たとえば、(都市、都道府県) にインデックスを設定した場合、都市でフィルタリングするクエリはインデックスを使用します。都道府県のみでフィルタリングするクエリは、おそらくインデックスを無視します。
2. カバーインデックス
カバーインデックスは、クエリを満たすために必要なすべての列(SELECTリストを含む)を含みます。これにより、データベースはメインテーブル(ヒープ)にアクセスせずにインデックスツリーから直接データを取得できます。これは読み込みが重い操作において大きなパフォーマンス向上をもたらします。
⚠️ 一般的な落とし穴とベストプラクティス
完璧なERDがあっても、実装上の誤りによりパフォーマンスが低下する可能性があります。構造をストレージに変換する際には、以下の一般的な罠を避けることが重要です。
- 過剰なインデックス化:すべてのインデックスはディスク容量を消費し、書き込み操作を遅くします。頻繁にクエリされるか、制約に使用されるカラムだけにインデックスを設定してください。
- 選択性の低さ:低基数のカラム(例:ブール型の「is_active」フラグ)にインデックスを設定することは、しばしば非効率です。最適化子は、インデックスにジャンプするよりもフルテーブルスキャンの方が速いと判断する可能性があります。
- NULL値の無視:インデックスは、エンジンによってNULL値の扱い方が異なります。特定の環境でのNULL値のインデックス化方法を考慮したクエリロジックを確保してください。
- フラグメンテーション:時間の経過とともに、インデックスはフラグメンテーションが生じます。パフォーマンスを最適に保つためには定期的なメンテナンスが必要です。
🛠️ パフォーマンス監視とメンテナンス
インデックス戦略を確立したら、監視は必須です。測定しないものは最適化できません。インデックスが効果的に使われているかを確認するために、定期的にクエリ実行計画を確認してください。
1. 実行計画の分析
「Index Scan」と「Index Seek」のような操作を確認してください。Seekは効率的ですが、Scanはそうではありません。大規模なテーブルでフルテーブルスキャンが見られる場合は、実際のクエリパターンに基づいてインデックス戦略を見直してください。
2. インデックス使用状況の追跡
ときには、インデックスが作成されてもまったく使われないことがあります。これらは無駄な負担です。定期的にインデックス使用状況の統計を監査し、削除できる未使用インデックスを特定して、書き込みパフォーマンスを向上させましょう。
3. データ成長の考慮
データが増加するにつれて、メンテナンスコストも増加します。1万行で問題なく動作するインデックスが、1000万行になるとボトルネックになる可能性があります。データセットが拡大するにつれて、ERDから導かれるインデックスパターンを再評価してください。インデックスとともに、パーティショニング戦略も必要になる場合があります。
🔄 整合性の要約
インデックス戦略をERDの構造に合わせることは、継続的なプロセスです。設計で定義されたデータ関係を理解し、それを物理的ストレージの最適化に変換する必要があります。
- 主キー:クラスタリングと一意性の確保に使用する。
- 外部キー:結合のパフォーマンス向上のためのインデックス。
- 結合テーブル:M:N関係に対する双方向インデックス。
- クエリパターン:特定のフィルタ順に合わせて複合インデックスを調整する。
ERDの構造的整合性を尊重することで、スケーラビリティの高いデータベースを構築できます。臨時のインデックス化の一般的な落とし穴を避け、アプリケーションの進化に伴ってもデータがアクセス可能でパフォーマンスを維持できます。この厳格なアプローチにより、データベースがビジネスロジックを支えつつ、ボトルネックにならないよう保証されます。🚀