










データの蓄積が加速するにつれ、データベーススキーマのアーキテクチャはシステムの安定性にとって重要な要因となります。アプリケーションが読み取り中心の操作から書き込み中心のワークロードに移行すると、標準的なエンティティ関係図(ERD)はしばしば大幅な調整を要します。高スループットを実現するためには、インデックスの追加以上のことが求められます。データの構造化、リンク、保存方法について根本的な見直しが必要です。このガイドでは、データ整合性を損なうことなく、圧力下でも性能を維持するための必要なアーキテクチャの変更について探求します。
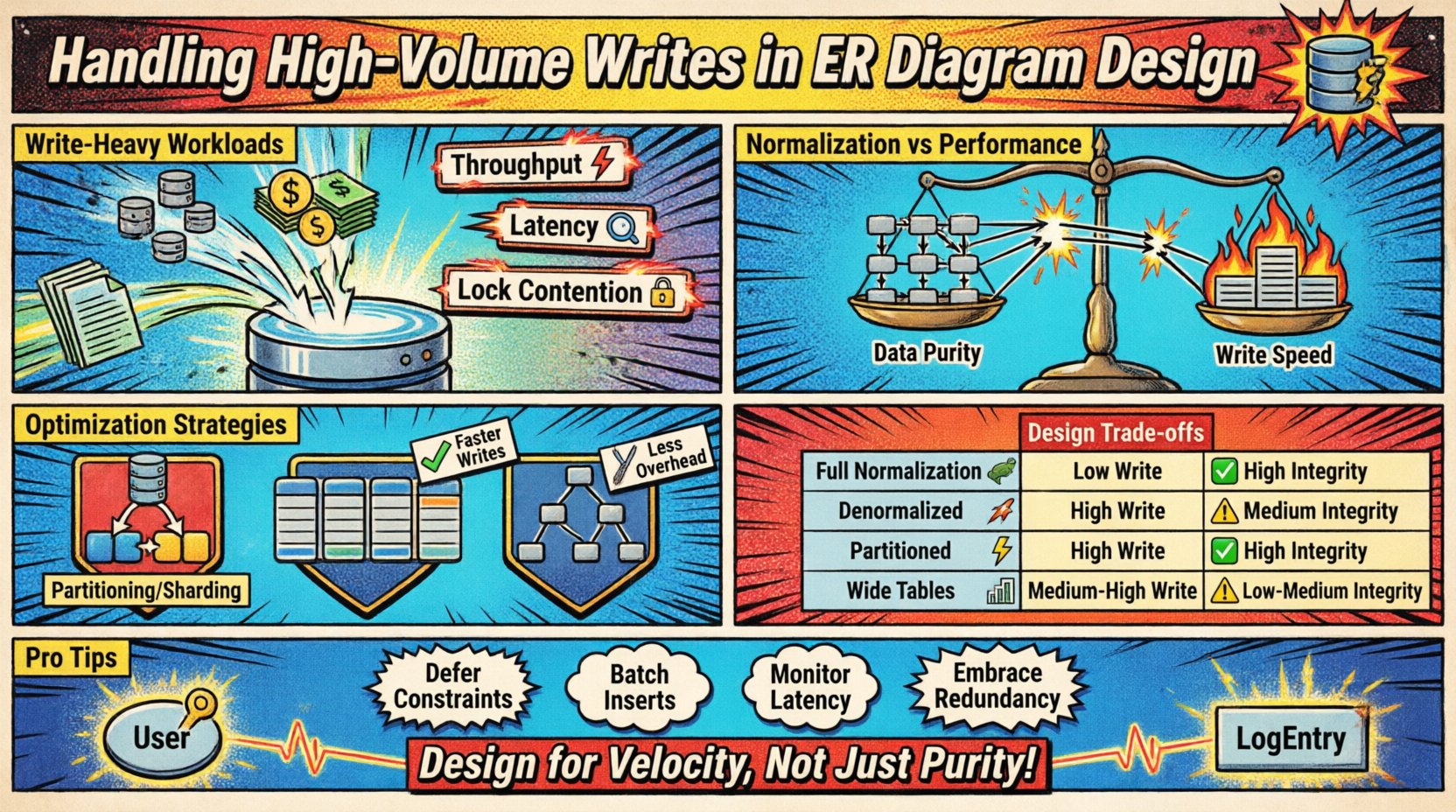
書き込み中心のワークロードの理解 📈
大量の書き込みが発生するのは、受信データの速度が標準的な正規化手法の処理能力を超えた場合です。これは、ログシステムやIoTセンサーからのデータ、金融取引の台帳、リアルタイム分析プラットフォームなどでよく見られます。主な課題は、挿入速度とモデルの整合性要件の間でバランスを取ることにあります。
- スループット: 秒あたりに処理される書き込み操作の数。
- ラテントシー: レコードを正常に永続化するまでにかかる時間。
- ロック競合: 複数のプロセスが同じデータを変更しようとする際に、リソースをめぐる競合が発生すること。
これらの指標が低下すると、スキーマそのものがボトルネックになることがよくあります。複雑なクエリに最適化された硬い設計は、継続的な更新の重みに耐えられず崩れてしまいます。したがって、初期のERDはデータ入力の速度を考慮する必要があります。
正規化とパフォーマンスのトレードオフ ⚖️
従来のデータベース設計は、冗長性を減らすために正規化(1NF、2NF、3NF)を推奨します。これによりストレージ領域の節約と整合性の確保が可能ですが、書き込み操作中にオーバーヘッドが発生します。すべての外部キー関係には、参照整合性を維持するために照合と結合チェックが必要です。
高ボリューム環境では、これらのチェックが高コストになります。書き込みイベント中に多対多の関係がもたらす影響を検討しましょう:
- 主テーブルが更新されなければならない。
- 結合テーブルに新しい行を挿入しなければならない。
- 2番目のテーブルが関係を確認しなければならない。
- トランザクションログはすべての変更を記録しなければならない。
各ステップがディスクI/OとCPUサイクルを追加します。重い書き込み負荷に対処するため、設計者はしばしば正規化ルールを緩和します。このプロセスでは、1単位の情報の保存に必要な書き込み操作の数を減らすために、データの冗長性を受け入れます。
書き込み速度を最適化するための戦略 ✍️
書き込み負荷を軽減するための複数の構造的パターンが存在します。これらの戦略は、各トランザクションのサイズを最小限に抑え、ストレージエンジンの処理の複雑さを減らすことに焦点を当てています。
1. パーティショニングとシャーディング
大きなテーブルをより小さな、管理しやすいチャンクに分割することで、データベースは書き込み負荷を複数の物理的または論理的セグメントに分散できます。
- 水平パーティショニング: キー(例:日付範囲、ユーザーID)に基づいて行を分割すること。
- 垂直パーティショニング: 頻繁にアクセスされない列を別テーブルに移動すること。
- シャーディング: データを複数のデータベースインスタンスに分散すること。
このアプローチにより、維持しなければならないインデックスのサイズが小さくなり、書き込み操作中のロックの範囲が制限されます。1つのシャードが飽和しても、他のシャードには影響が及びません。
2. デノーマライゼーションの戦略
冗長なデータを保存することで、システムは書き込み時に結合(JOIN)を回避できる。例えば、新しい取引が到着するたびに関連する行から合計を計算するのではなく、システムはあらかじめ計算された要約カラムを直接更新できる。
- 計算カラム: 行内に導出値を直接保存する。
- マテリアライズドビュー: 頻繁な集計処理の結果をあらかじめ計算する。
- キャッシュされたカウンター: 統計情報を保持するための別々のカウンターテーブルを維持する。
これによりストレージ要件が増加するが、挿入時のCPUコストを著しく低下させる。
3. インデックス戦略
インデックスは読み取りを高速化するが、書き込みを遅くする。行が挿入されるたびに、データベースはすべて関連するインデックスを更新しなければならない。高書き込み環境では、インデックスの肥大化が大きな問題となる。
- インデックス数を最小限に抑える: フィルタリングや結合に使用されるカラムのみにインデックスを設定する。
- 部分インデックス: 頻繁にアクセスされる行のサブセットのみにインデックスを設定する。
- 過剰なインデックス化を避ける: 頻繁に変化するカラムにはインデックスを設定しない。
設計アプローチの比較 📑
以下の表は、異なる構造的選択が書き込み性能およびデータ整合性に与える影響を概説している。
| 戦略 | 書き込み性能 | データ整合性 | ストレージコスト | 最適な使用ケース |
|---|---|---|---|---|
| 完全正規化 | 低 | 高 | 低 | 複雑なレポート作成、低い書き込み頻度 |
| デノーマライズド | 高 | 中 | 高 | リアルタイムフィード、高頻度の書き込み |
| パーティショニングされたスキーマ | 高 | 高 | 中 | 時系列データ、大規模なデータセット |
| 広いテーブル | 中~高 | 中 | 中 | NoSQLパターン、スパースデータ |
外部キーと制約の処理 🔗
参照整合性は関係データ設計の基盤ですが、すべての挿入に対して制約を強制すると、高速なパイプラインが停止する可能性があります。データベースエンジンは、子行を受け入れる前に参照される親行が存在することを確認しなければなりません。
データ整合性が重要だが、書き込み速度が最優先される状況では、以下の調整を検討してください:
- 遅延制約:トランザクションの終了時、直ちにではなく関係性を検証する。
- アプリケーションレベルのチェック:データをデータベースに送信する前に、アプリケーションコードで関係性を検証する。
- ソフト削除:削除のオーバーヘッドを回避するために、レコードを削除するのではなく非アクティブとしてマークする。
制約を完全に削除することはリスクがありますが、検証ロジックを移動することで、場合によってはスループットが向上します。この決定は、特定のワークフローにおいて即時整合性がどれほど重要であるかに依存します。
書き込み増幅とストレージエンジン 💾
ストレージエンジンがデータをどのように処理するかを理解することは重要です。多くのエンジンは耐久性を確保するために、事前にログを記録するWAL(Write-Ahead Log)を使用しています。これは、実際のデータファイルに書き込みを適用する前に、すべての書き込みがログに記録されることを意味します。
書き込み増幅単一の論理的書き込み操作が複数の物理的書き込みを引き起こすときに発生します。これは、コンパクションが頻繁なストレージエンジンで一般的です。これを管理するには:
- バッチ挿入:複数の行を1つのトランザクションにまとめる。
- 連続した書き込み:ランダムな挿入よりも連続したキー生成を優先するスキーマを設計する。
- バッファリング:書き込みをフラッシュする前にキューするため、アプリケーション層に一時的なバッファを許可する。
ERDの設計をストレージエンジンの強みに合わせることで、データを永続化するために必要な物理的作業を最小限に抑えることができる。
モニタリングと反復 🔄
高書き込みを想定したスキーマは静的ではない。トラフィックパターンが変化するにつれて、設計の進化が必要になる場合がある。書き込み遅延とディスクI/Oの継続的なモニタリングは不可欠である。
- 書き込み遅延を追跡する:ボトルネックを示すスパイクを特定する。
- ロック待ちをモニタリングする:プロセスがブロックされている競合ポイントを検出する。
- インデックス使用状況を分析する:一度も使われないインデックスを削除して、書き込みオーバーヘッドを削減する。
ERDの定期的な監査により、構造が現在の運用要件と整合していることを保証できる。特定のテーブルが継続的に書き込みスループットに苦労している場合、パーティショニング戦略や正規化レベルの見直しの時期かもしれない。
主な考慮事項の要約 🛠️
大量の書き込みを想定したERDを設計するには、純粋なデータの整合性からシステムのスループットへとマインドセットを変える必要がある。以下の点が必須の行動を要約している:
- 正規化の監査:すべての関係が単なる複雑さではなく、価値をもたらすことを確認する。
- パーティショニングを計画する:キーの構造を、容易に水平分割できるように設計する。
- インデックスの数を制限する:書き込みパスを可能な限り簡潔に保つ。
- 冗長性を受け入れる:挿入時に結合の依存関係を減らすために、非正規化を利用する。
- 段階的に検証する:安全な範囲で、制約チェックを重要な書き込みパスから移動する。
これらの原則を適用することで、パフォーマンスを犠牲にすることなく成長を支えることができるデータモデルが構築される。目標は複雑さを排除することではなく、アプリケーションのスピードを支える形で複雑さを管理することである。