











堅牢なデータベーススキーマを設計するには、データエンティティがどのように相互作用するかを深く理解することが不可欠です。管理が最も難しい構造の一つが多対多関係です。これは、あるエンティティの単一のインスタンスが、別のエンティティの複数のインスタンスと関連し、その逆もまた成り立つ状況です。適切な計画がなければ、これらの接続はデータの重複、整合性の問題、そして顕著なパフォーマンスのボトルネックを引き起こす可能性があります。このガイドでは、エンティティ関係モデル(ERM)内でのこれらの関係の最適化のメカニズムについて探求し、スケーラブルで保守しやすいシステムを確保します。
根本的な課題を理解する 🔍
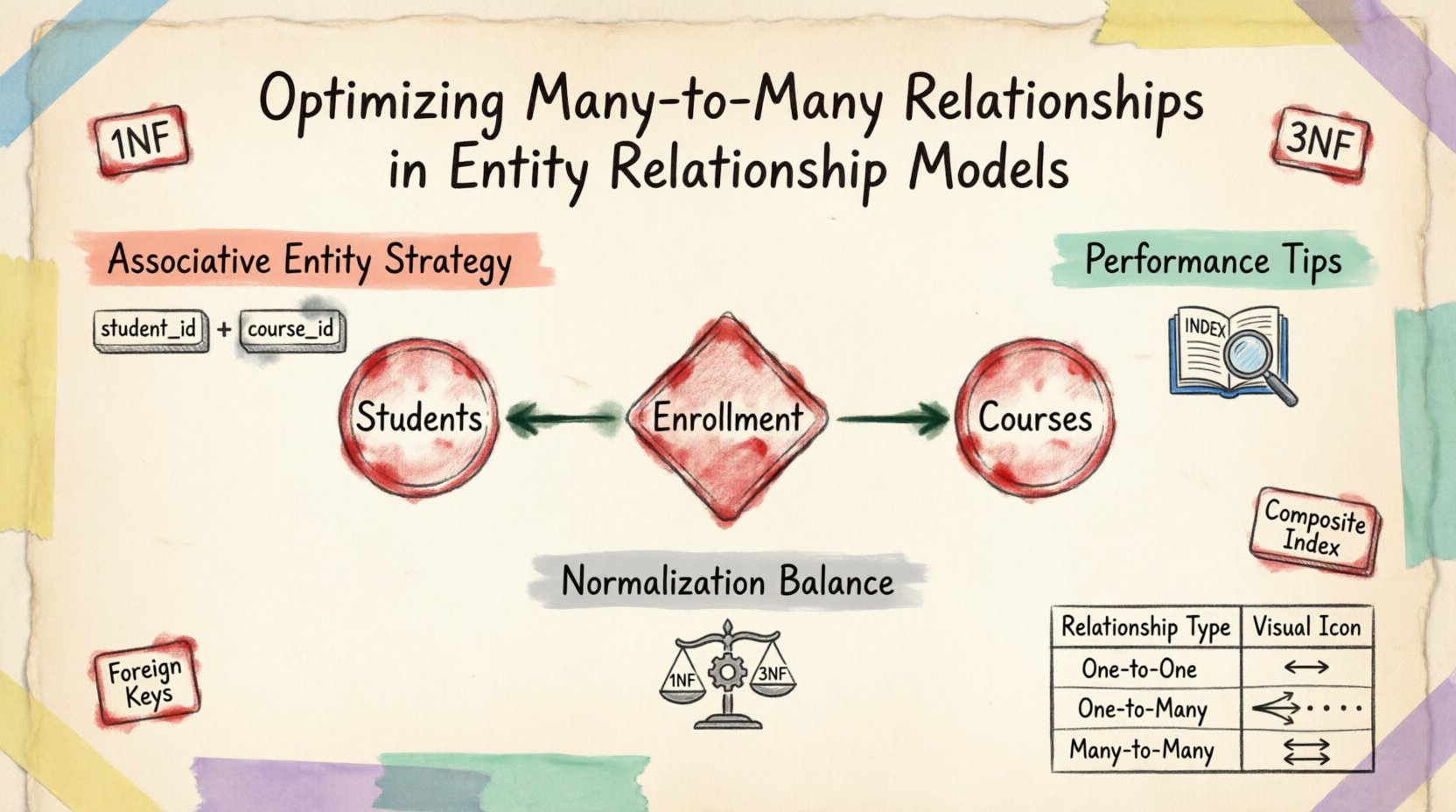
概念モデルにおいて、多対多関係は直感的です。学生と授業を考えてみましょう。学生は複数の授業に登録し、各授業には複数の学生がいます。これを物理的なデータベース構造に直接表現しようとすると問題が生じます。標準的なリレーショナルテーブルは、外部キーを通じて、1対多および1対1の関係をネイティブにサポートしています。多対多関係を正しく機能させるには、中間的な構造が必要です。
複数のIDを1つのカラムに格納しようとする(例:カンマ区切りのリスト)ことは、第一正規形(1NF)に違反します。このアプローチでは、クエリの実行、インデックスの作成、データ整合性の維持がほぼ不可能になります。解決策は、関連するエンティティ(しばしば結合テーブルまたはブリッジテーブルと呼ばれる)を介して、関係を2つの1対多関係に分割することにあります。
関連エンティティ戦略 🧩
多対多関係を解決する根本的な手法は、関連エンティティの導入です。このエンティティは、2つの親テーブルの間を橋渡しする役割を果たします。両方の親エンティティの主キーを外部キーとして含み、各関係インスタンスのユニーク性を保証する複合主キーを構成します。
- 構造: このテーブルには、関連するエンティティの主キーを参照する外部キーが含まれます。
- 一意性: 複合キーにより、同じ2つのレコード間の重複関係を防ぎます。
- 属性: このテーブルは、エンティティそのものだけでなく、関係自体に関する特定のデータを格納できます。
従業員とプロジェクトを結ぶシナリオを考えてみましょう。1人の従業員は複数のプロジェクトに従事し、1つのプロジェクトには複数の従業員がいます。関係テーブルには、割り当て日、そのプロジェクトにおける従業員の役割、または割り当てられた時間といった情報が格納されることがあります。これらの属性は、従業員やプロジェクト個々のものではなく、関係自体に属するものです。
実装ステップ
- エンティティの特定: 関係に参加する2つの異なるエンティティを定義する。
- 結合テーブルの作成: 説明的な名前(例:)を付けて新しいテーブルを生成する
従業員_プロジェクト_割り当て. - 外部キーの追加: 両方の親エンティティの主キー用のカラムを追加する。
- 制約の定義: 参照整合性を維持するために外部キー制約を設定する。
- インデックス化: ジョイン操作の高速化のために、外部キーのカラムにインデックスを適用する。
正規化とデータ整合性 🛡️
最適化は、正規化とパフォーマンスの間でトレードオフを伴うことが多いです。正規化は重複を減らしますが、過度に正規化された構造は複雑な結合を必要とし、クエリの実行を遅くする可能性があります。多対多関係を最適化する際には、これらの要因をバランスよく調整することが不可欠です。
第三正規形(3NF)は、通常、運用データベースの目標とされます。この状態では、結合テーブルに推移的依存関係が含まれてはなりません。すべての非キー属性は主キーに依存しなければなりません。結合テーブルに、外部キーのいずれか一方にのみ依存するデータが含まれている場合、それはそれぞれの親テーブルに移動すべきです。
一般的な正規化の落とし穴
- 重複する外部キー:明確な階層構造がないまま、同じ外部キーを複数の結合テーブルに含めること。
- 制約の欠如:外部キーの組み合わせに対して一意制約を適用しないこと。
- 論理削除:関係テーブル内の削除済みレコードを考慮しないことにより、孤立データが発生する。
パフォーマンス最適化戦略 ⚡
データ量が増加するにつれて、結合テーブルの行数は指数関数的に増加する可能性がある。これはクエリ実行時間に直接的な影響を与える。いくつかの戦略により、パフォーマンスの低下を緩和できる。
1. 戦略的インデックス作成
インデックスは結合のパフォーマンスにとって不可欠である。外部キー列に複合インデックスを設定すると、個別のインデックスよりも効果的であることが多い。これにより、データベースエンジンは全テーブルをスキャンせずに、関連する行をより迅速に検索できる。
- クラスタ化インデックス:一部のシステムでは、複合キーでテーブルをクラスタ化することで、範囲検索のパフォーマンスが向上する。
- カバーインデックス:頻繁にクエリされる列をインデックスに含めることで、テーブルヒープにアクセスする必要がなくなる。
2. パーティショニング
結合テーブルが管理しにくくなるほど大きくなった場合、日付や地域でパーティショニングすることで負荷を分散できる。特に、最近の関係が過去のものよりも頻繁にアクセスされる歴史データにおいて効果的である。
3. クエリ最適化
複数の結合を含む複雑なクエリはリソースを圧迫する。クエリヒントの使用や、サブクエリを最小限に抑えるためにSQLを再構成することで、改善が可能である。また、実行計画を分析してボトルネックを特定することも重要である。
| 戦略 | 利点 | トレードオフ |
|---|---|---|
| 複合インデックス作成 | 結合の検索速度向上 | ストレージおよび書き込みオーバーヘッドの増加 |
| テーブルパーティショニング | メンテナンス性およびスキャン速度の向上 | クエリ論理の複雑化 |
| キャッシュ | データベース負荷の低減 | データの一貫性のリスク |
関係属性の取り扱い 📝
関連エンティティの最大の利点の一つは、関係固有の属性を格納できる点です。たとえば、契約管理システムでは、ベンダーと製品の間に多対多の関係があります。その属性には単価、契約の開始日、合意された数量などが含まれます。
これらの属性をベンダーまたは製品テーブルに格納しようとすると、重複が生じます。価格が変更された場合、製品テーブルの複数の行を更新する必要があります。それらを結合テーブルに配置することで、特定の関係インスタンスについての単一の真実のソースを維持できます。
高度なシナリオとエッジケース 🌐
現実世界のデータモデリングは、標準的なパターンではすぐにカバーできない独自の課題をしばしば提示します。
- 自己参照関係: 自身と関係を持つエンティティ(例:従業員が他の従業員を管理する)。これには、同じテーブルの主キーを指す外部キーが必要です。
- 連鎖削除: 親エンティティを削除する際に、関係レコードも自動的に削除するかどうかを決定する。これにより、孤立した外部キーを防ぐが、歴史的な関連データを失う可能性がある。
- 再帰的関係: 結合テーブルが自身に戻る複雑な階層。
最適化されたスキーマのクエリ 🔎
スキーマが最適化されると、それをクエリするには正確さが求められます。開発者は、データベースエンジンが結合パスをどのようにたどるかを理解する必要があります。
特定の従業員のすべてのプロジェクトを取得するなど、データを取得する際には、クエリで従業員テーブルを結合テーブルに、そしてプロジェクトテーブルに結合する必要があります。効率的なSQLの記述により、データベースが利用可能なインデックスを正しく使用できることが保証されます。インデックス付きカラムに対して関数を使用しないことが、インデックスの利用効率を維持するための標準的な手法です。WHERE句は、インデックスの利用を維持するための標準的な手法です。
結合ロジックのベストプラクティス
- 明示的な結合を使用する:次を優先する:
INNER JOINまたはLEFT JOIN暗黙のコンマ区切りテーブルよりも - カラムを制限する:ネットワーク転送量と処理時間を減らすために、必要なカラムのみを選択する。
- 早期にフィルタリングする:可能な限り、結合の前に
WHERE句でフィルタを適用する。
関係の種類を比較する 📊
多くの対多数の関係がデータモデリングの広い文脈の中でどのように位置づけられるかを理解することは、より良い設計意思決定を下すのに役立ちます。
| 関係の種類 | 構造 | 使用例 |
|---|---|---|
| 1対1 | 単一の外部キー | ユーザーのプロフィールとユーザー設定 |
| 1対多 | 単一の外部キー | 注文と注文項目 |
| 多対多 | 結合テーブル | 学生と授業 |
データの一貫性の維持 🔄
関連するテーブル間でデータが一貫性を保つことを確保することは極めて重要です。これには通常、トランザクション管理が含まれます。トランザクションは、親テーブルと結合テーブルへのデータ挿入をラップするべきです。どちらかのステップが失敗した場合、全体の操作はロールバックされ、部分的なデータ状態を防ぐ必要があります。
トリガーもビジネスロジックを強制するために使用できますが、隠れたパフォーマンスコストを避けるために、使用は控えめにすべきです。たとえば、従業員の部署がプロジェクトの部署と一致しない場合、その従業員がプロジェクトに割り当てられないようにするトリガーを設けることができます。
モニタリングとメンテナンス 📈
デプロイ後は、システムの継続的なモニタリングが必要です。結合テーブルのサイズの増加は、スケーリングの問題の最初の兆候であることがよくあります。テーブルサイズ、インデックスの断片化、クエリのパフォーマンスメトリクスの定期的な監査が必要です。
- アーカイブ:関係データの履歴が現在、積極的に照会されていない場合は、冷蔵ストレージに移動する。
- 再インデックス化:定期的にインデックスを再構築または再整理して、最適なパフォーマンスを維持する。
- 結合の見直し:アプリケーションの変更が非効率なクエリパターンを導入しないように確認する。
スキーマ設計に関する最終的な考察 🎯
多くの対多数の関係を最適化することは一度きりの作業ではなく、継続的な改善プロセスです。理論的な正確性と実用的なパフォーマンスのバランスを取る必要があります。正規化の原則を遵守し、関連エンティティを活用し、戦略的なインデックスを適用することで、データベースアーキテクトは堅牢かつ効率的なシステムを構築できます。目標は、データの取得や変更に不要な制約を課さずに、ビジネスロジックを支える構造を作ることです。