











データベース設計はバランスの取り合いである。現実世界の関係を反映するようにデータを構造化しつつ、パフォーマンスと整合性を維持する必要がある。このプロセスにおける一般的な落とし穴は、エンティティ関係図(ERD)内に循環依存が導入されることである。これらのループは、外部キーの関係の連鎖が最終的に元のエンティティに戻る場合に発生する。単体で見ると論理的に思えるが、このような構造はデータ管理、クエリ最適化、システムの安定性において大きな課題を引き起こす。
これらの問題を解決するには、関係理論に対する深い理解と、慎重なアーキテクチャ設計が必要である。このガイドでは、循環依存のメカニズム、データベースの健全性への影響、最適なパフォーマンスを実現するためのスキーマの再設計に役立つ検証済みの戦略について解説する。
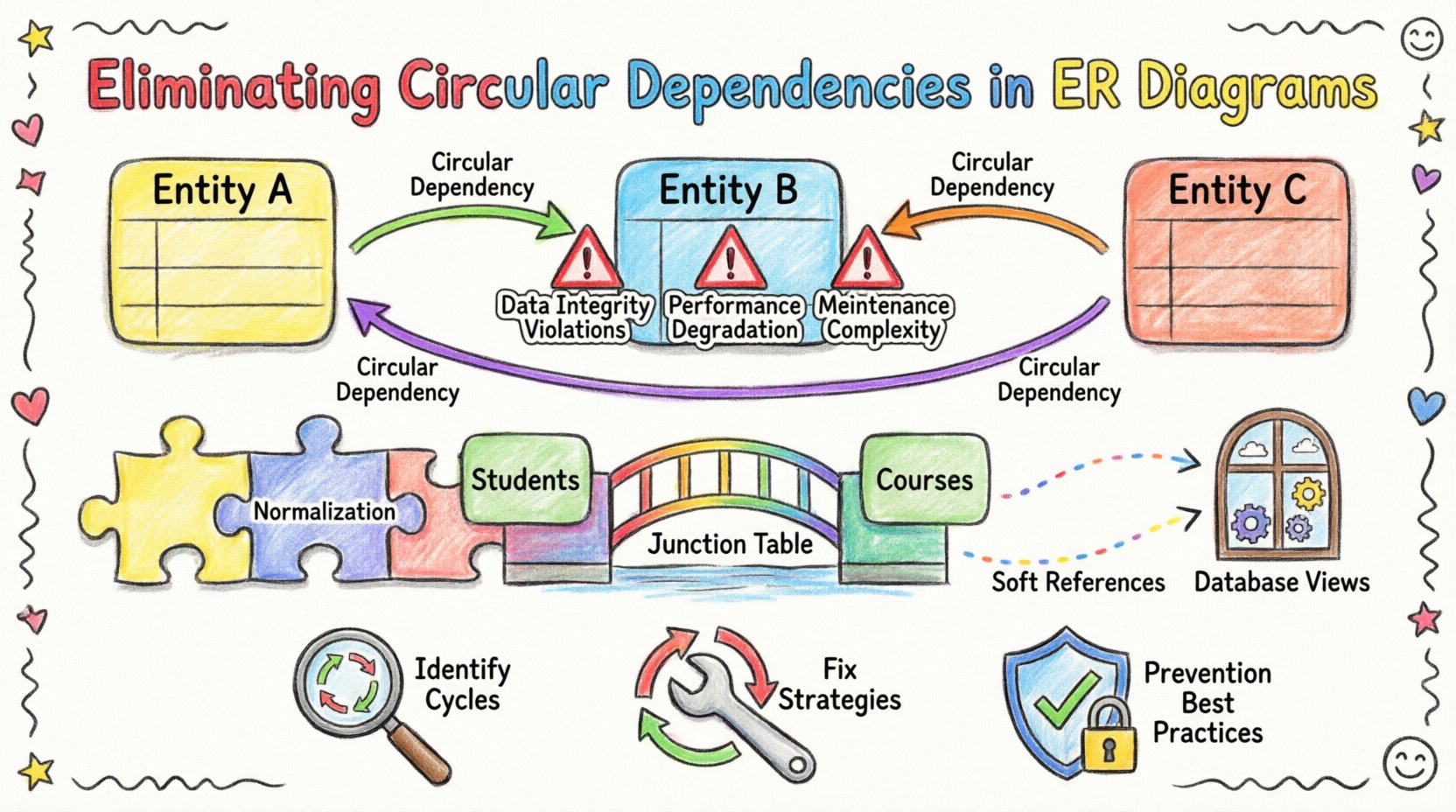
🧩 ER図における循環依存の理解
標準的な関係モデルでは、外部キー制約が子テーブルから親テーブルへのリンクを確立する。このリンクにより参照整合性が保たれ、子テーブルのデータが親テーブルの有効なエントリに対応していることを保証する。循環依存は、この連鎖が明確に終了しない場合に発生する。代わりに、エンティティAがエンティティBを参照し、エンティティBがエンティティCを参照し、最終的にエンティティCがエンティティAを参照する。
階層構造を含む状況を考えてみよう。ツリー内の各ノードが親と子を把握する必要がある場合、双方向の関係が簡単にループを形成する。慎重な処理がなければ、データの挿入や削除時にデータベースエンジンは処理順序を決定できず、問題が生じる。
循環参照の種類
- 直接的な循環:エンティティAがエンティティBへの外部キーを持ち、エンティティBがエンティティAへの外部キーを戻す。これは、両方が互いを追跡する双方向関係でよく見られる。
- 間接的な循環:3つ以上のエンティティの連鎖が戻ってくる。例えば、A → B → C → A。これらは複雑なスキーマでは視覚的に発見しにくい。
- 自己参照ループ:エンティティが自分自身を参照する。階層データ(例:マネージャーも従業員である従業員テーブル)では一般的だが、不適切な実装は無限再帰を引き起こす可能性がある。
⚠️ 解決されないループの影響
循環依存を解決しないまま放置することは、単なる理論的な懸念ではない。アプリケーション層およびデータベースエンジン自体に実際のリスクをもたらす。
1. データ整合性の違反
データベースエンジンがサイクルにデータを挿入しようとする際、処理順序を決定する必要がある。AがBの存在を必要とし、BがAの存在を必要とする場合、どちらも最初に作成できない。これにより制約違反が発生する。一部のデータベースシステムでは遅延制約チェックを許可しているが、この機能に頼ると論理エラーが隠れてしまうことがある。
2. パフォーマンスの低下
循環パスをたどるクエリは非効率になることがある。サイクル内の結合操作は、最適でない実行計画を選択させる可能性がある。最悪の場合、階層をたどるための再帰クエリが無限ループに入り、CPUとメモリリソースを消費し続け、接続が切断されるまで続く。
3. メンテナンスの複雑さ
循環依存を持つスキーマを変更するのはリスクが高い。外部キーが有効な状態でサイクル内のテーブルを削除しようとすると失敗する可能性がある。カスケード削除操作は予期せぬ連鎖反応を引き起こす。開発者はしばしばアプリケーションレベルのロジックを記述してデータベースの制約を回避せざるを得ず、整合性の責任が真の情報源からずれてしまう。
🔍 循環依存の特定
問題を修正する前に、まずその存在を特定する必要がある。小さな図では視覚的な検査で十分である。数百のテーブルを持つエンタープライズグレードのシステムでは、手動での追跡は誤りを招きやすい。以下の手法を用いてスキーマを監査しよう。
- グラフ解析:ER図を有向グラフとして扱う。ノードはテーブルを表し、エッジは外部キーを表す。パスが開始ノードに戻る場合、サイクルが存在する。
- 依存関係ツリー:各テーブルに対して依存関係ツリーを生成する。テーブルがツリー内で自分自身の先祖として現れる場合、サイクルが存在する。
- システムテーブルのクエリ:ほとんどのデータベース管理システムは、外部キーのメタデータをシステムカタログに保存している。これらの関係をプログラム的にたどるクエリを記述しよう。
🛠️ 解決のための戦略
識別された後は、循環依存関係を解除しなければなりません。目的は、物理的なループを作成せずに論理的な関係を保持することです。以下に、これを達成するための主な方法を示します。
1. スキーマの正規化
正規化とは、データを整理して冗長性を減らし、整合性を高めるプロセスです。しばしば、循環依存関係は、単一の抽象化レベルに属さない関係をモデル化しようとする試みから生じます。
- 第三正規形(3NF):非キー属性が主キーにのみ依存していることを確認してください。テーブルに階層を表すために自己参照の外部キーが含まれている場合、階層のロジックを別個の関係テーブルに分離することを検討してください。
- 冗長性の除去:エンティティAとエンティティBが互いに参照している場合、その参照のどちらかが冗長ではないか確認してください。関係を一方通行で表現できるでしょうか?
2. 中間テーブルの導入
多対多の関係は、循環ループの頻出原因です。主なエンティティに外部キーを直接配置するのではなく、中間テーブルを使用してください。
たとえば、もし生徒と授業の間に多対多の関係がある場合、授業IDを生徒テーブルに追加し、生徒IDを授業テーブルに追加してはいけません。代わりに、両方のIDを保持する登録テーブルを作成してください。これにより、2つの主要なエンティティ間の直接的なリンクが断たれます。
3. 論理関係にビューを使用する
場合によっては、物理的な格納方法が論理的な要件を完全に反映する必要はありません。アプリケーションがAとBの間に関係を認識する必要があるが、直接格納するとループが発生する場合、データベースのビューを使用してください。
- 物理モデル:AとBを、直接の外部キーのリンクなしで格納する。
- 論理モデル:共通の属性または別個の関係テーブルに基づいて、AとBを結合するビューを作成する。
これにより、ストレージ制約がアプリケーション論理から分離され、データベースが物理的なループを作成せずに、重要となる場所で整合性を維持できるようになります。
4. ソフト参照の実装
場合によっては、関係に対して厳格な参照整合性は必要ありません。関連エンティティのIDを外部キー制約ではなく、単純な整数列として保存できます。
- 長所:挿入・削除時に制約チェックが削除され、ループが物理的に存在しても操作をブロックしなくなる。
- 短所:データベースはもはや関係を強制しなくなる。アプリケーションロジックが参照されるIDが存在することを検証しなければならない。
📊 リファクタリング手法の比較
| 手法 | 複雑さ | 整合性の強制 | 最適な使用ケース |
|---|---|---|---|
| 正規化 | 高 | 完全 | データの重複が根本原因の場合。 |
| 結合テーブル | 中 | 完全 | 多対多関係。 |
| ビュー | 低 | 部分的(クエリレベル) | レポート作成や読み取り中心のワークロード。 |
| ソフト参照 | 低 | なし(アプリケーションレベル) | レガシーシステムやオプションの関係。 |
🛡️ 防止策とベストプラクティス
スキーマをリファクタリングしたら、今後のループの発生を防ぐことに焦点が移る。デザインパターンやガバナンスプロセスにより、これらの問題が再発するリスクを軽減できる。
1. 関係の方向を定義する
外部キーは常に特定の方向にのみ流れることをルールとして定める。例えば、子テーブルは常に親を参照するが、逆はしない。親が子のデータにアクセスする必要がある場合は、外部キーではなくクエリまたはビューを使用する。
2. ハイエラルキーを慎重にモデル化する
自己参照テーブルは組織図やコメントスレッドなどで一般的である。ループを防ぐために:
- 親のみ: 以下の項目のみを保存する:
parent_id。以下の項目は同じ行に保存しない:children_ids同じ行に保存しない。 - パス列挙: 深い階層構造の場合、フルパス文字列(例:
/1/5/9/)を保存することで、再帰的結合なしに高速なクエリが可能になる。
3. スキーマの自動監査
サイクル検出をCI/CDパイプラインに統合する。スクリプトはスキーマ定義ファイル(SQLマイグレーションスクリプトなど)を解析し、デプロイ前にループを生じさせる新しい外部キー定義を警告できる。
4. ドキュメント化
最新のERDを維持する。開発者がテーブルを追加する際には、図を更新するべきである。この視覚的支援は、コードを書く前に潜在的なループを特定するのに役立つ。大規模チームでは、データベーススキーマから自動ドキュメントを生成するツールの使用が強く推奨される。
🔄 レガシーシステムの対応
ダウンタイムコストやデータ量のため、本番データベースのリファクタリングが常に可能とは限らない。このような場合、段階的なアプローチが必須となる。
- 重要な経路を特定する:最も頻繁にアクセスされるクエリに影響を与えるループを優先的に解除する。
- アプリケーションロジックを利用する:一時的に関係処理をアプリケーション層に移す。IDを単純なカラムとして保存し、コード内で検証する。
- 移行計画を立てる:新しい構造が安定した後、アプリケーションレベルの参照を物理的制約に変換するためのメンテナンスウィンドウをスケジュールする。
📝 スキーマの健全性に関する最終的な考慮事項
明確なERDは堅牢なアプリケーションの基盤である。循環依存は、構造よりも利便性を優先した設計の兆候である。正規化原則を遵守し、適切な場面で結合テーブルを活用することで、データの一貫性とクエリ可能性を確保できる。
データベース設計は反復的であることを忘れないでください。ビジネス要件が進化するにつれて、関係性も変化する。スキーマが依然として目標と一致しているかを定期的に確認する。継続的な検証と外部キーに対する厳格なアプローチにより、成長するデータニーズの複雑さに対してアーキテクチャが耐性を持つ状態を保てる。