











スケーラブルなソフトウェアアーキテクチャの文脈において、マルチテナントの概念は基盤となる。単一のアプリケーションインスタンスが複数の顧客(テナントと呼ばれる)をサービス提供しつつ、データの論理的な分離を維持する。下層のデータ構造を設計するには正確さが求められる。エンティティ関係図(ERD)は、このアーキテクチャの設計図として機能する。テーブル間の関係、キー、制約を可視化し、テナント全体にわたるデータ整合性を保証する。 📐
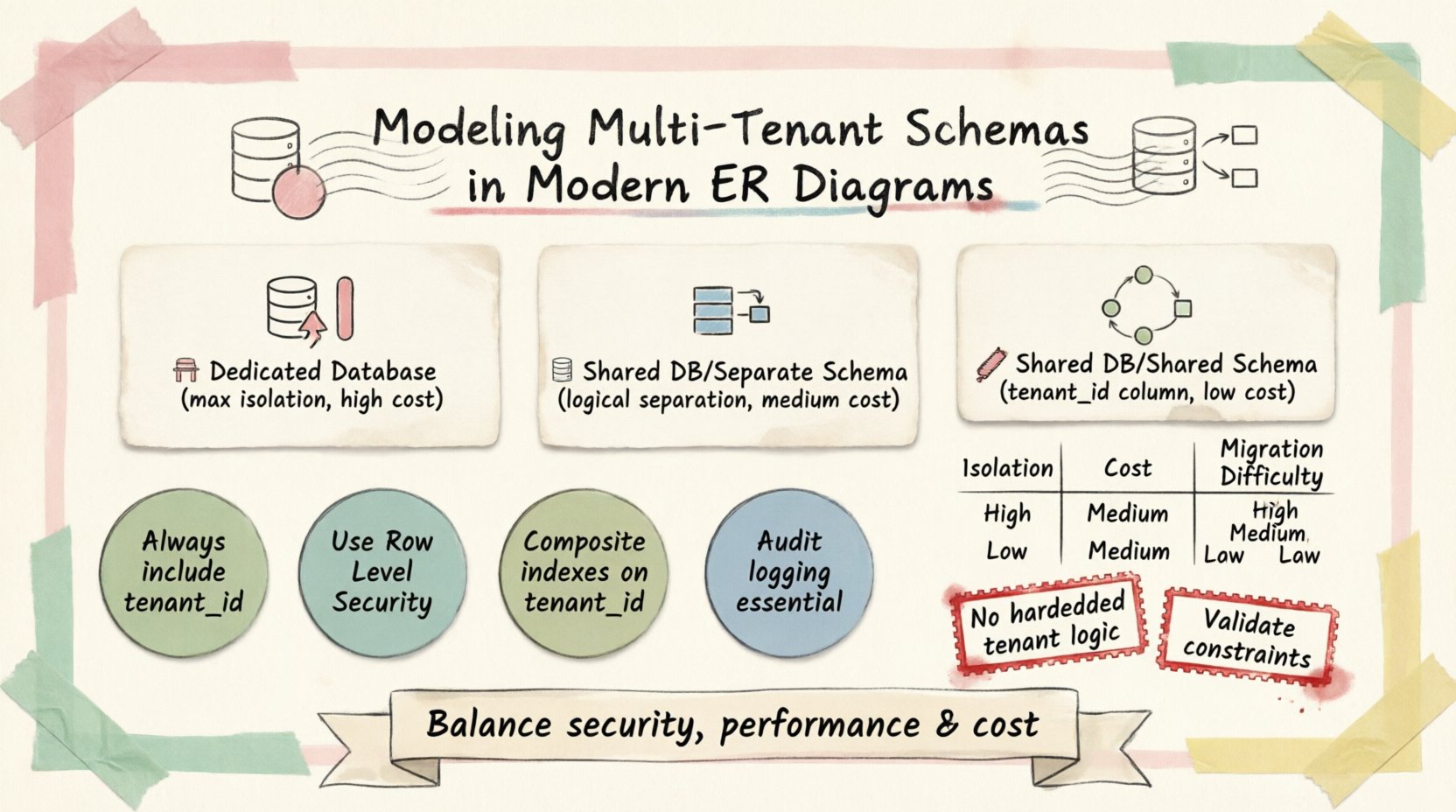
マルチテナント環境向けのERDを構築する際の主な課題は、分離性、パフォーマンス、コストのバランスを取ることである。すべてのシナリオに適する単一のソリューションは存在しない。代わりに、アーキテクトはセキュリティ要件と運用予算に合致するパターンを選択しなければならない。この記事では、これらのスキーマをモデリングするための主要な戦略を検討し、特定のベンダー製ツールに依存せずに、技術的実装の詳細に深く掘り下げる。 🛠️
コアパターンの理解 🔍
マルチテナントモデリングの基盤は、テナントデータが物理的にどのように格納され、論理的にどのように分離されるかにある。業界を支配する3つの異なるパターンが存在する。それぞれがデータ分離性と保守の複雑さに関する独自のトレードオフを提示している。
1. テナントごとの専用データベース 🏢
このアプローチでは、すべての顧客に独自の分離されたデータベースインスタンスが割り当てられる。ERDの構造はすべてのインスタンスで同一だが、物理的な境界は厳格である。
- 分離レベル:最大。1つのデータベースで発生した障害は、他のデータベースに影響しない。
- セキュリティ:高。物理的な分離により、誤ったデータ漏洩を防ぐ。
- コスト:インスタンスごとのリソースオーバーヘッドのため、高くなる。
- 移行:複雑。スキーマの変更には、すべてのインスタンスにスクリプトを実行する必要がある。
ERDの観点から見ると、このパターンは標準的なシングルテナント図に見える。しかし、デプロイパイプラインは複数の接続を管理しなければならない。これは、厳格なコンプライアンス要件を持つエンタープライズクライアントでよく使用される。
2. 共有データベース、別々のスキーマ 📂
ここでは、すべてのテナントが単一のデータベースシステム内に存在するが、各テナントは独自の異なるスキーマ(名前空間)を持つ。テーブルはスキーマごとに複製される。
- 分離レベル:高。データベースエンジン内の論理的な分離。
- セキュリティ:強。アクセス制御リスト(ACL)により、スキーマの可視性を制限できる。
- コスト:中程度。データベースエンジンのオーバーヘッドを共有する。
- 保守:専用DBよりも容易だが、スキーマの更新はすべてのスキーマに伝搬しなければならない。
ERDでは、特定の名前空間ラベルの下にテーブルをグループ化することで表現される。関係は一貫しているが、図の範囲は複数のスキーマコンテナを示すように拡大する。
3. 共有データベース、共有スキーマ 🔗
これは一般的なSaaSアプリケーションで最も一般的なパターンである。すべてのデータは、特定の列によって区別される同じテーブルセットに格納される。
- 分離レベル:論理的です。すべての行は同じテーブルに存在します。
- セキュリティ:アプリケーションロジックおよび行レベルセキュリティ(RLS)に依存します。
- コスト:最低。リソースの利用効率を最大化します。
- 保守:簡単です。スキーマの変更はすべてのテナントに即座に適用されます。
このパターンのERDでは、重要なカラムが導入されます:tenant_id。この外部キーは、すべてのレコードを特定の顧客にリンクします。このモデルにおけるデータ分離の基盤です。
ERDにおけるテナントデータの可視化 📊
マルチテナント用の効果的なERDを作成するには、パーティショニング戦略を明確に伝えるために特定の表記が必要です。ステークホルダーは、データの流れや境界の位置を理解する必要があります。
テナントIDカラム
共有スキーマでは、tenant_idユーザー固有のデータを格納するすべてのテーブルに存在しなければなりません。これは任意ではありません。トランザクションテーブルからこのカラムを省略すると、深刻なデータ漏洩を引き起こす可能性があります。
- 主キー:通常、
tenant_idtenant_idとローカルIDの組み合わせが、複合主キーを形成します。 - インデックス:パフォーマンスにとって不可欠です。tenant_idでフィルタリングするクエリは、高速でなければなりません。
tenant_id高速でなければなりません。 - 制約:外部キーは、通常、中央の
tenantsマスターテーブルを参照します。
マスターテナントテーブル
各テナントに関するメタデータを格納する専用テーブルが通常存在します。このテーブルには、設定詳細、サブスクリプションステータス、請求情報が格納されます。
- 主な属性:テナントID、名前、プランTier、作成日。
- 関係:他のすべてのデータテーブルとの1対多。
スキーマ戦略の比較 📋
適切な判断を下すために、以下の表を使用して各戦略の運用への影響を比較してください。
| 機能 | 専用DB | 共有スキーマ | 共有テーブル |
|---|---|---|---|
| データ隔離 | 物理的 | 論理的 | 論理的 |
| クエリの複雑さ | 簡単 | 複雑 | 複雑 |
| リソースコスト | 高 | 中 | 低 |
| スキーマ移行 | 困難 | 中 | 簡単 |
| バックアップ戦略 | 細粒度 | 細粒度 | フルダンプ |
セキュリティとデータパーティショニング 🔒
スキーマのモデリングは戦いの半分にすぎません。データアクセス層は、図で定義された境界を強制しなければなりません。共有テーブルを使用する際の目標は論理的な分離です。
行レベルセキュリティ(RLS)
現代のデータベースエンジンはRLSをサポートしており、行レベルでアクセスポリシーを強制します。これにより、データベース自体が現在のユーザーのコンテキストに基づいて結果をフィルタリングできます。
- ポリシー定義: ルールは、行が表示されるのは、
tenant_idがセッションと一致する場合のみであると規定しています。 - 実装: ERDは、セッションコンテキストを保存できる能力を反映すべきです。
- 利点:アプリケーションレベルのバグによるデータ漏洩のリスクを低減します。
監査とログ記録
テナント固有のデータに対するすべての変更はログに記録されるべきです。誰が何をいつ変更したかを追跡するために、ERDに監査テーブルが不可欠です。これはコンプライアンスおよびデバッグにおいて重要です。
- 必須フィールド:テナントID、ユーザーID、アクション、タイムスタンプ、旧値、新値。
- 保持期間:ポリシーはログをどのくらい保持するかを定義しなければなりません。
パフォーマンス上の考慮事項 ⚡
共有テーブルはクエリ実行計画に複雑性をもたらします。データ量が増えるにつれて、データベースエンジンは全テーブルをスキャンせずにテナントデータを効率的に分離しなければなりません。
インデックス戦略
標準的なインデックスでは不十分です。テナント識別子を優先する複合インデックスが必要です。
- プライマリインデックス: は
tenant_idから始まり、その後に自然キーが続くべきです。 - クエリ最適化: すべてのクエリが
WHERE句にテナントフィルタを含むことを確認してください。 - パーティショニング: 一部のシステムでは、テーブルを物理的にパーティション化でき、
tenant_id範囲またはハッシュによって。
クエリの複雑さ
複数のスキーマやテナント間でテーブルを結合する際、結合条件にはテナントIDを含める必要があります。これを怠ると、異なる顧客のデータのカルテシアン積が発生する可能性があります。
- 結合ロジック: 常に
tenant_idおよび関係キーで結合する。 - アプリケーションレイヤー:ミドルウェアは、テナントフィルタを自動的に挿入すべきである。
保守とマイグレーション 🔄
スキーマは静的ではない。要件の変化に伴って進化する。マルチテナント化はこれらの変更にさらに難易度を加える。
スキーマの進化
共有テーブルではカラムの追加は簡単である。一方、カラムの削除はすべてのテナントに影響する。専用データベースモデルでは、すべてのインスタンスに対して変更をスクリプト化する必要がある。
- バージョン管理:後方互換性を管理するために、スキーマのバージョンを追跡する。
- ロールバック:テナントの一部でマイグレーションが失敗した場合に変更を元に戻すための計画を持つ。
バックアップと復旧
復旧戦略はパターンによって異なる。専用データベースでは、他のテナントに影響を与えずに単一のテナントを復旧できる。共有データベースでは、全体のインスタンスを復旧する必要がある。
- 粒度:共有テーブルでは、単一のテナントに対する時点復旧が困難になる。
- テスト:ステージング環境で復旧手順を定期的にテストする。
避けるべき一般的な落とし穴 ⚠️
良好に設計されたERDであっても、実装エラーがシステムを損なう可能性がある。これらの一般的な問題に注意を払うべきである。
- ハードコードされたテナントロジック: アプリケーションコードにテナントIDをハードコードしてはならない。設定またはセッションコンテキストを使用する。
- グローバル変数:リクエスト間で永続化される可能性のあるグローバル変数にテナントコンテキストを格納しないようにしてください。
- 制約の欠如: データベースが
tenant_id一意性を強制しない場合、アプリケーションはそれを厳密に検証しなければなりません。 - 分析の無視:レポート作成のために複数のテナントにわたってデータを集計するには、注意深い処理が必要であり、機密情報が混在しないようにしなければなりません。
命名規則のベストプラクティス 🏷️
命名の一貫性は、開発者がデータ構造を即座に理解するのを助けます。共有スキーマ内にテナント固有のテーブルが存在する場合は、プレフィックスまたはサフィックスを使用してそれらを示してください。
- テーブル名:
tenant_name_ordersまたはorders_tenant_id. - カラム名: 常に
tenant_idすべてのレコードテーブルに明示的に含めてください。 - インデックス: インデックスの名前を明確にし、例えば
idx_orders_tenant_id.
アーキテクチャ選択の結論 🎯
適切なマルチテナントスキーマパターンを選択するには、技術的実現可能性とビジネスニーズのバランスが必要です。ERDは、この選択をチーム全体に伝えるためのツールです。セキュリティのための物理的分離を選択するか、効率のための共有テーブルを選択するかに関わらず、図は境界を明確に示さなければなりません。
厳格なモデリング基準を遵守し、強力なインデックスを実装し、明確な分離ロジックを維持することで、安全にスケーラブルなシステムを構築できます。基盤がしっかりしていれば、テナントの複雑さは管理可能です。図の最初の行からデータの整合性とパフォーマンスに注目してください。 🚀