











堅牢なデータアーキテクチャを設計するには、箱と線を描くだけでは不十分です。データの流れ、成長、時間とともにどのように相互作用するかを深く理解する必要があります。システムがスケーリングする際、エンティティ関係モデル(ERD)は論理的一貫性のための設計図となり、パーティショニング戦略は物理的なパフォーマンスに焦点を当てます。これら二つの側面を整合させることは、クエリ速度、データ整合性、運用効率を維持するために不可欠です。このガイドでは、不要な複雑性やリスクを導入することなく、既存のデータモデルとパーティショニング技術を調和させる方法を探ります。
🧩 基盤:ERDを設計図として
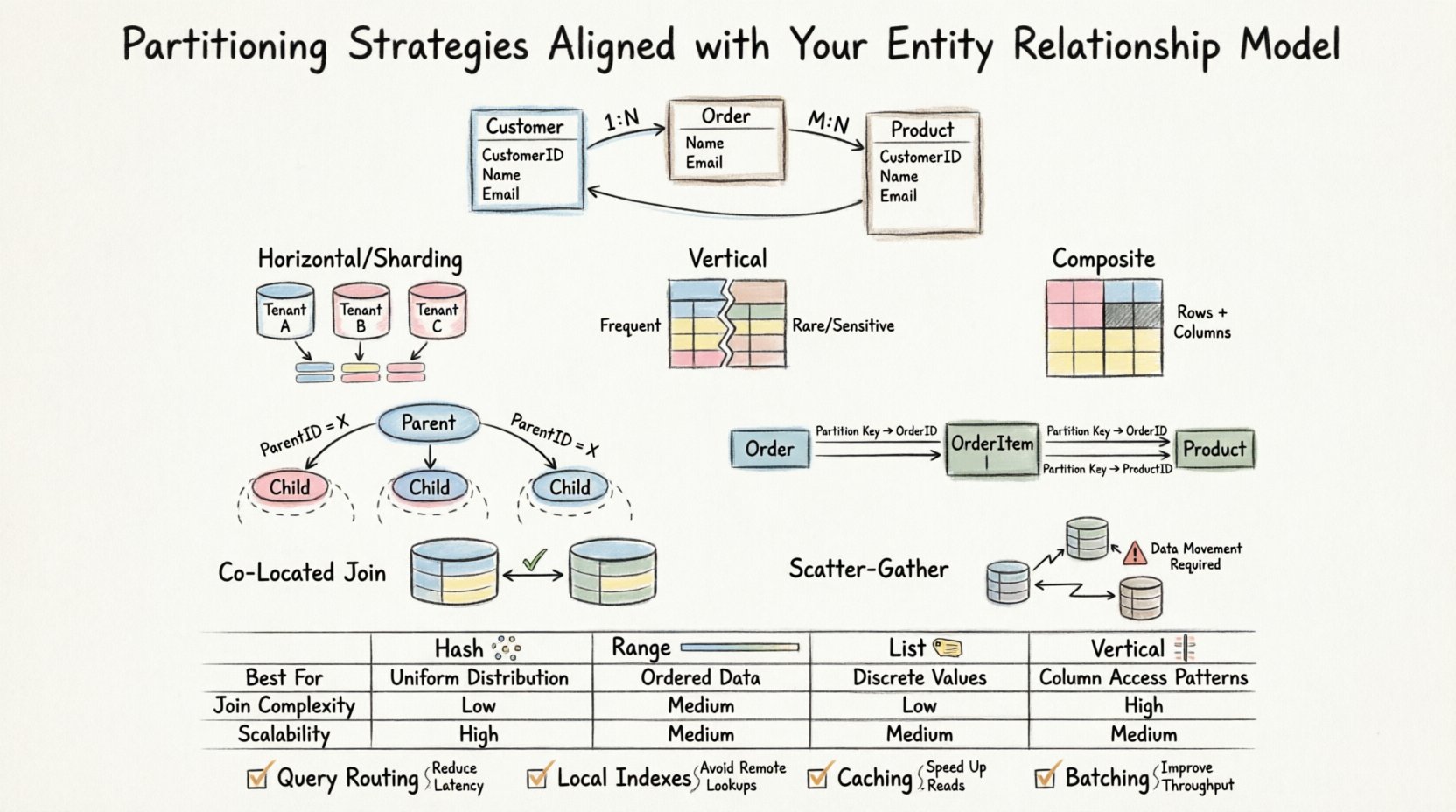
データを分割する方法を検討する前に、データを結びつける関係を理解する必要があります。ERDはエンティティ、属性、およびそれらの間の基数を定義します。これらの関係が、データの取得や結合の仕方を決定します。パーティショニングを導入する際、実質的にこれらの論理的関係を物理的なストレージ境界にわたって分散することになります。
以下のパーティショニングのスキーマへの影響を検討してください:
- 主キー:パーティション間での均等な分布を確保するために、慎重に選択する必要があります。
- 外部キー:異なるパーティションにあるテーブルを結合すると、大きなオーバーヘッドが発生する可能性があります。
- インデックス:グローバルインデックスは、パーティションキーを考慮せずに設計された場合、ボトルネックになる可能性があります。
- データローカリティ:関連するデータは、ネットワーク遅延を最小限に抑えるために、理想的には同じノード上に配置されるべきです。
これらの要因を無視すると、論理モデルは設計上完璧に機能するが、物理的な実装が負荷に耐えられない状況に陥る可能性があります。目標は、関連データをできるだけ近くに保ちつつ、独立した成長を可能にすることです。
🔄 パーティショニングの種類とスキーマの適合性
異なるパーティショニング手法は、異なるデータアクセスパターンに適しています。適切な手法を選択するには、ERDが関係をどのように定義しているか、および想定されるクエリパターンに大きく依存します。以下に、一般的な戦略と、それらがリレーショナル構造とどのように相互作用するかを説明します。
水平パーティショニング(シャーディング)
水平パーティショニングは、テーブルの行を異なるグループに分割します。これは、テーブルが単一インスタンスで管理できなくなる場合に頻繁に使用されます。ERDの文脈では、パーティションキーが自然なアクセスパターンと相関している場合、この戦略が最も効果的です。
- 使用例:明確なユーザーまたはテナントグループを持つ大規模なトランザクションテーブル。
- ERDへの影響:親テーブルを指す外部キーは慎重に管理する必要があります。親テーブルもパーティショニングされている場合、キーは整合性を保つ必要があります。
- 利点:ノードを追加することで、大規模なスケールアウトを可能にします。
- 課題:複数のパーティションにまたがる複雑なクエリには、集約ロジックが必要です。
垂直パーティショニング
垂直パーティショニングは、テーブルの列を異なるグループに分割します。特定の列が一緒にアクセスされることが稀である場合、または機密データを隔離する必要がある場合に有効です。
- 使用例:行が広く、頻繁にクエリされるのは列のサブセットのみのテーブル。
- ERDへの影響: 主キーは、すべての垂直パーティションに存在しなければ、完全な行の再構成ができない。
- 利点: 必要なカラムのみをメモリに読み込むことで、I/Oを削減する。
- 課題: 完全なエンティティを再構成するには結合が必要であり、クエリの複雑さが増す。
複合パーティショニング
このアプローチは水平および垂直戦略を組み合わせる。行数とカラム幅の両方が大きな制約となる高性能システムでは、しばしば必要となる。
- 使用例:データウェアハウスまたは高頻度取引ログ。
- ERDへの影響: 実装前に厳格なスキーマ定義が必要である。
🔑 キーと関係性の整合
このプロセスで最も重要なステップは、パーティションキーを選択することである。このキーが、どの行がどの物理ストレージユニットに配置されるかを決定する。関係データベースの文脈では、パーティションキーは、外部キーの関係性と一致するのが理想的である。
親子関係
1対多の関係を扱う場合、子テーブルは親テーブルよりもはるかに速く成長することが多い。子テーブルを親IDでパーティション化すれば、関連するすべての子レコードが同じノード上に存在する。
- 利点: 親とすべての子を取得するクエリでは、ノード間通信が不要になる。
- 利点: 削除操作が単一のパーティション内で効率的に伝播する。
- 警告: 1つの親が他の親よりも著しく多くの子を持つ場合、データの偏りが発生する可能性がある。
多対多関係
多対多関係は通常、結合テーブルを伴う。このテーブルは適切にパーティション化されない場合、パフォーマンスのボトルネックになる可能性がある。
- 戦略: 関与する外部キーのいずれかでパーティション化する。
- 戦略: クエリが常にパーティションキーでフィルタリングされるようにし、フルテーブルスキャンを避ける。
- 戦略: 絶対に必要な場合を除き、複数のパーティションにまたがる結合テーブルの結合を避ける。
⚖️ ジョイン操作の処理
ジョインはリレーショナルデータベースの生命線ですが、データが分割されるとコストが高くなります。パーティション間でジョインがどのように動作するかを理解することは、パフォーマンスを維持するために不可欠です。
コロケートパーティション
Table AとTable Bが同じキー(例:Tenant_ID)でパーティション化されている場合、それらの間のジョインはローカルで行われます。データベースエンジンはノード間でデータを移動する必要がありません。
- 要件:両方のテーブルは同じパーティション化アルゴリズムとキーを使用しなければなりません。
- 要件:ERDはこの整合性を論理的にサポートしなければなりません。
スキャッターガザージョイン
テーブルが異なる方法でパーティション化されている場合、システムは複数のノードからデータを取得し、結果を集約して最終的なセットを返す必要があります。これをスキャッターガザーオペレーションと呼びます。
- パフォーマンスコスト: 高いネットワークオーバーヘッド。
- パフォーマンスコスト: ラテントシーの増加。
- 推奨事項: ERD設計段階でこれらのジョインを最小限に抑えること。
🛡️ パーティション間での整合性の維持
データが分散されていると、データ整合性制約を維持することが難しくなります。ERDはこれらのルールを論理的に定義しますが、実装は物理的な分散を処理しなければなりません。
- 参照整合性:子レコードが親レコードの挿入前に存在することを保証するのは、異なるノード上に存在する場合に複雑になります。
- 一意制約:グローバルな一意性は、すべてのパーティション間での調整を必要とします。
- トリガー:分散環境では、ロックの問題を避けるために、アプリケーションレベルのトリガーがデータベースレベルのトリガーに置き換えられることがよくあります。
- トランザクション:分散トランザクションはスループットに影響を与える可能性があります。可能な限りトランザクションを単一のパーティション内に留めてください。
📊 パーティション化戦略の比較
以下の表は、異なる戦略が一般的なERDシナリオとどのように相互作用するかを要約しています。
| 戦略 | ERDシナリオに最適 | 結合の複雑さ | 書き込みのスケーラビリティ |
|---|---|---|---|
| ハッシュパーティショニング | 均一な分布が必要で、特定の範囲は不要 | 高 (ランダムな分布) | 高 |
| 範囲パーティショニング | 日付ベースまたは連続するID | 低 (整合されている場合) | 中 |
| リストパーティショニング | 固定されたカテゴリ(例:地域、ステータス) | 低 (整合されている場合) | 高 |
| 垂直パーティショニング | 広い行、頻繁でない列 | 中 (再構築が必要) | 高 |
🔄 演化と移行
スキーマの進化は避けられない。ビジネス要件は変化し、新しい属性が追加される。ERDを変更する際には、パーティショニング戦略を再検討する必要がある。
- 列の追加:垂直パーティショニングは、列を新しいパーティションに配置できるため、列の追加を容易にする。
- キーの変更:既存データの再パーティショニングは重い作業である。初期設計段階でこれを計画する必要がある。
- アーカイブ:パーティショニングにより、アクティブなパーティションに影響を与えずに、古いデータ範囲のアーカイブが容易になる。
- モニタリング:パーティションのサイズを定期的に確認し、単一のパーティションがホットスポットにならないようにする。
🚀 パフォーマンス最適化のヒント
システムが応答性を保つためには、パーティショニング戦略と併せて、特定の最適化を適用する必要がある。
- クエリルーティング: アプリケーションがパーティションキーに基づいて、正しいパーティションノードにクエリを送信することを確保する。
- インデックス作成: ローカルインデックスはグローバルインデックスよりも高速です。インデックスをパーティションキーに合わせて設計する。
- キャッシュ: 頻繁にアクセスされる参照テーブルは、すべてのノードのメモリに収まるほど小さい場合はパーティション化しないべきである。
- バッチ処理: パーティション間のトランザクションオーバーヘッドを減らすために、挿入と更新をバッチ処理する。
🔍 最終的な考慮事項
スケーラブルなシステムを構築するには、論理的な明確さと物理的制約のバランスを取る必要がある。エンティティ関係モデルはデータの一貫性のルールを提供し、パーティショニングは成長のメカニズムを提供する。これらの二つが一致しているとき、データ量が指数関数的に増加してもシステムはパフォーマンスを維持できる。
モデルで定義された関係に注目する。データが特定の属性によって自然にグループ化される場合は、その属性をパーティションキーとして使用する。結合が頻繁に行われる場合は、関連するテーブルが同じパーティショニング論理を共有していることを確認する。明確なパフォーマンス上の目的を持たないパーティションでスキーマを複雑にしないようにする。
これらの原則に従うことで、長期的な安定性を支える基盤が構築される。目的は単にデータを保存することではなく、将来の要件にシステムが完全な再設計なしに適応できるように、データを構造化することである。設計段階での慎重な計画は、運用段階での大幅な工数削減につながる。