










À mesure que l’accumulation de données s’accélère, l’architecture de votre schéma de base de données devient un facteur déterminant crucial de la stabilité du système. Lorsqu’une application passe d’opérations lecture-intensives à des charges de travail écriture-intensives, le diagramme d’entité-relation (ERD) standard nécessite souvent des ajustements importants. Concevoir pour un haut débit implique bien plus que l’ajout d’index ; cela exige une réflexion fondamentale sur la manière dont les données sont structurées, liées et stockées. Ce guide explore les changements architecturaux nécessaires pour maintenir les performances sous pression sans compromettre l’intégrité des données.
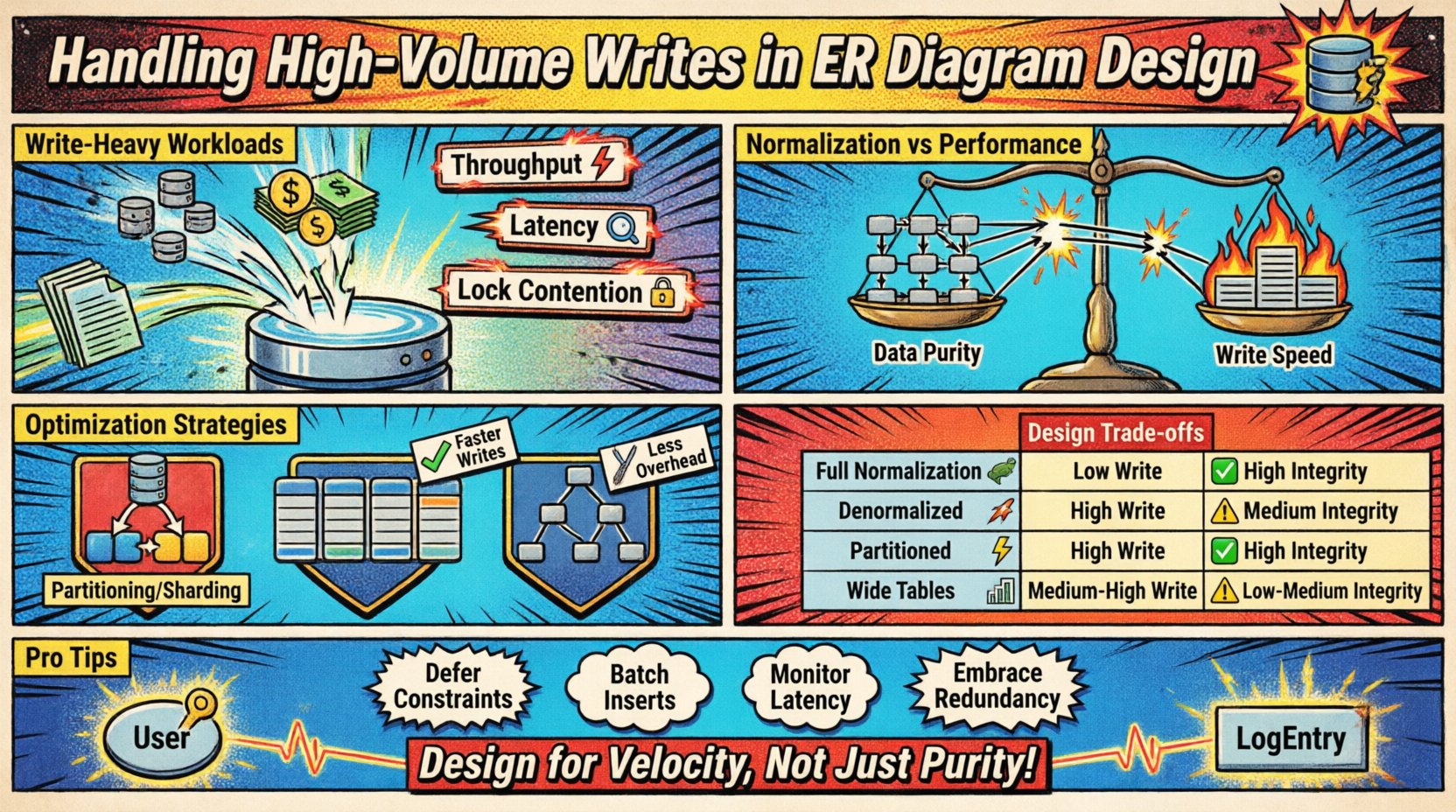
Comprendre les charges de travail à écriture intense 📈
Les scénarios d’écriture à fort volume surviennent lorsque le taux de données entrantes dépasse la capacité des techniques de normalisation standard. Cela se produit souvent dans les systèmes de journalisation, les flux de capteurs IoT, les registres de transactions financières ou les plateformes d’analyse en temps réel. Le défi principal réside dans l’équilibre entre la vitesse d’insertion et les exigences de cohérence du modèle.
- Débit : Le nombre d’opérations d’écriture traitées par seconde.
- Latence : Le temps nécessaire pour persister un enregistrement avec succès.
- Contention sur les verrous : Concurrence pour les ressources lorsque plusieurs processus tentent de modifier les mêmes données.
Lorsque ces métriques se dégradent, le schéma lui-même est souvent le goulot d’étranglement. Une conception rigide optimisée pour des requêtes complexes peut s’effondrer sous le poids des mises à jour constantes. Par conséquent, le ERD initial doit tenir compte de la vitesse d’entrée des données.
Normalisation vs. compromis performance ⚖️
La conception traditionnelle des bases de données encourage la normalisation (1NF, 2NF, 3NF) pour réduire la redondance. Bien que cela économise de l’espace de stockage et assure la cohérence, cela introduit une surcharge lors des opérations d’écriture. Chaque relation de clé étrangère nécessite une recherche et un contrôle de jointure pour maintenir l’intégrité référentielle.
Dans un environnement à fort volume, ces vérifications deviennent coûteuses. Pensez aux implications d’une relation plusieurs-à-plusieurs lors d’un événement d’écriture :
- La table principale doit être mise à jour.
- La table de jonction doit insérer une nouvelle ligne.
- La deuxième table doit vérifier la relation.
- Les journaux de transactions doivent enregistrer tous les changements.
Chaque étape ajoute des opérations d’E/S disque et des cycles CPU. Pour gérer des charges d’écriture importantes, les concepteurs relâchent souvent les règles de normalisation. Ce processus consiste à accepter une redondance des données afin de réduire le nombre d’opérations d’écriture nécessaires pour stocker une unité d’information.
Stratégies pour optimiser la vitesse d’écriture ✍️
Plusieurs modèles structurels existent pour atténuer la pression d’écriture. Ces stratégies se concentrent sur la minimisation de la taille de chaque transaction et la réduction de la complexité du travail du moteur de stockage.
1. Partitionnement et fractionnement (sharding)
Diviser une grande table en morceaux plus petits et plus gérables permet à la base de données de répartir la charge d’écriture sur plusieurs segments physiques ou logiques.
- Partitionnement horizontal : Division des lignes selon une clé (par exemple, plages de dates, identifiants d’utilisateurs).
- Partitionnement vertical : Déplacement des colonnes peu fréquemment accessibles vers des tables séparées.
- Fractionnement (sharding) : Répartition des données sur plusieurs instances de base de données.
Cette approche réduit la taille des index à maintenir et limite le périmètre des verrous lors d’une opération d’écriture. Si un shard devient saturé, les autres restent inchangés.
2. Stratégies de dénormalisation
Le stockage de données redondantes permet au système d’éviter les jointures lors des écritures. Par exemple, au lieu de calculer chaque fois la somme totale à partir des lignes associées chaque fois qu’une nouvelle transaction arrive, le système peut mettre à jour directement une colonne de résumé prédéterminée.
- Colonnes calculées : Stocker les valeurs dérivées directement dans la ligne.
- Vues matérialisées : Pré-calculer les résultats pour les agrégations fréquentes.
- Compteurs mis en cache : Maintenir une table de compteurs distincte pour les statistiques.
Bien que cela augmente les exigences de stockage, cela réduit considérablement le coût CPU de l’insertion.
3. Stratégie d’indexation
Les index accélèrent les lectures mais ralentissent les écritures. À chaque insertion de ligne, la base de données doit mettre à jour chaque index associé. Dans les environnements à forte écriture, le gonflement des index devient un problème majeur.
- Minimiser le nombre d’index : Indexer uniquement les colonnes utilisées pour le filtrage ou les jointures.
- Index partiels : Indexer uniquement un sous-ensemble de lignes fréquemment accessibles.
- Éviter l’indexation excessive : Omettre les index sur les colonnes qui changent fréquemment.
Comparaison des approches de conception 📑
Le tableau ci-dessous décrit l’impact des différentes choix structurels sur les performances d’écriture et l’intégrité des données.
| Stratégie | Performances d’écriture | Intégrité des données | Coût de stockage | Meilleur cas d’utilisation |
|---|---|---|---|---|
| Normalisation complète | Faible | Élevée | Faible | Rapports complexes, faible volume d’écriture |
| Dénormalisé | Élevé | Moyen | Élevé | Flux en temps réel, volume élevé d’écriture |
| Schéma partitionné | Élevé | Élevé | Moyen | Données chronologiques, grands ensembles de données |
| Tables larges | Moyen-Élevé | Moyen | Moyen | Modèles NoSQL, données creuses |
Gestion des clés étrangères et des contraintes 🔗
L’intégrité référentielle est un pilier de la conception relationnelle, mais imposer des contraintes à chaque insertion peut saturer une pipeline à haute vitesse. Le moteur de base de données doit vérifier que la ligne parente référencée existe avant d’accepter la ligne enfant.
Dans les scénarios où l’intégrité des données est critique mais la vitesse d’écriture est primordiale, envisagez les ajustements suivants :
- Contraintes différées :Valider les relations à la fin d’une transaction plutôt que de manière immédiate.
- Vérifications au niveau de l’application :Vérifier les relations dans le code de l’application avant d’envoyer les données à la base de données.
- Suppressions douces :Marquer les enregistrements comme inactifs au lieu de les supprimer afin de préserver les liens référentiels sans surcharge de suppression.
Supprimer les contraintes entièrement est risqué, mais déplacer la logique de validation peut parfois améliorer le débit. Le choix dépend de la criticalité de la cohérence immédiate pour votre workflow spécifique.
Amplification d’écriture et moteurs de stockage 💾
Comprendre comment le moteur de stockage gère les données est essentiel. De nombreux moteurs utilisent un journal d’écriture (WAL) pour assurer la durabilité. Cela signifie que chaque écriture est enregistrée avant d’être appliquée aux fichiers de données réels.
Amplification d’écriturese produit lorsque une seule opération d’écriture logique entraîne plusieurs écritures physiques. C’est courant dans les moteurs de stockage fortement soumis à la compaction. Pour gérer cela :
- Insertions par lots :Regrouper plusieurs lignes dans une seule transaction.
- Écritures séquentielles : Concevez des schémas pour favoriser la génération de clés séquentielles plutôt que des insertions aléatoires.
- Tamponnage : Autorisez un tampon temporaire au niveau de la couche application pour mettre en file d’attente les écritures avant le vidage.
En alignant la conception du schéma ERD avec les forces du moteur de stockage, vous pouvez minimiser l’effort physique nécessaire pour persister les données.
Surveillance et itération 🔄
Un schéma conçu pour de hautes écritures n’est pas statique. Au fur et à mesure que les modèles de trafic évoluent, la conception peut nécessiter des ajustements. Une surveillance continue de la latence d’écriture et de l’E/S disque est essentielle.
- Suivre la latence d’écriture : Identifier les pics qui indiquent des goulets d’étranglement.
- Surveiller les attentes de verrouillage : Détecter les points de contention où les processus sont bloqués.
- Analyser l’utilisation des index : Supprimer les index qui ne sont jamais utilisés afin de réduire la charge d’écriture.
Les audits réguliers du schéma ERD assurent que la structure reste en phase avec les exigences opérationnelles actuelles. Si un tableau spécifique peine constamment à atteindre un débit d’écriture adéquat, il peut être temps de revoir la stratégie de partitionnement ou le niveau de normalisation.
Résumé des considérations clés 🛠️
Concevoir un schéma ERD pour des écritures à fort volume exige un changement de mentalité, passant de la pureté des données à la performance du système. Les points suivants résument les actions essentielles :
- Audit de la normalisation : Assurez-vous que chaque relation apporte une valeur plutôt que de la complexité.
- Prévoir la partitionnement : Structurer les clés pour permettre un fractionnement horizontal facile.
- Limiter les index : Maintenir le chemin d’écriture aussi léger que possible.
- Accepter la redondance : Utilisez la dénormalisation pour réduire les dépendances de jointure lors de l’insertion.
- Valider progressivement : Déplacer la vérification des contraintes hors du chemin critique d’écriture, là où c’est sécurisé.
En appliquant ces principes, vous créez un modèle de données capable de soutenir la croissance sans sacrifier les performances. L’objectif n’est pas d’éliminer la complexité, mais de la gérer de manière à soutenir la vitesse de votre application.