











Les diagrammes Entité-Relation (ERD) servent de plan directeur pour l’architecture des bases de données. Ils définissent la manière dont les données sont structurées, stockées et récupérées au sein d’un système. Lorsque ces diagrammes présentent des défauts, les conséquences vont bien au-delà de la phase de développement. Les erreurs dans les environnements de production peuvent entraîner une corruption des données, des goulets d’étranglement de performance et des pertes financières importantes. Comprendre les pièges courants est essentiel pour préserver l’intégrité du système.
De nombreuses équipes se précipitent à travers la phase de modélisation, privilégiant la vitesse à la précision. Cette précipitation entraîne souvent des problèmes de schéma difficiles à résoudre une fois que les données commencent à circuler. Une conception solide exige une réflexion attentive sur les relations, les types de données et les contraintes. Ci-dessous, nous examinons les défauts de conception les plus fréquents et leurs implications techniques.
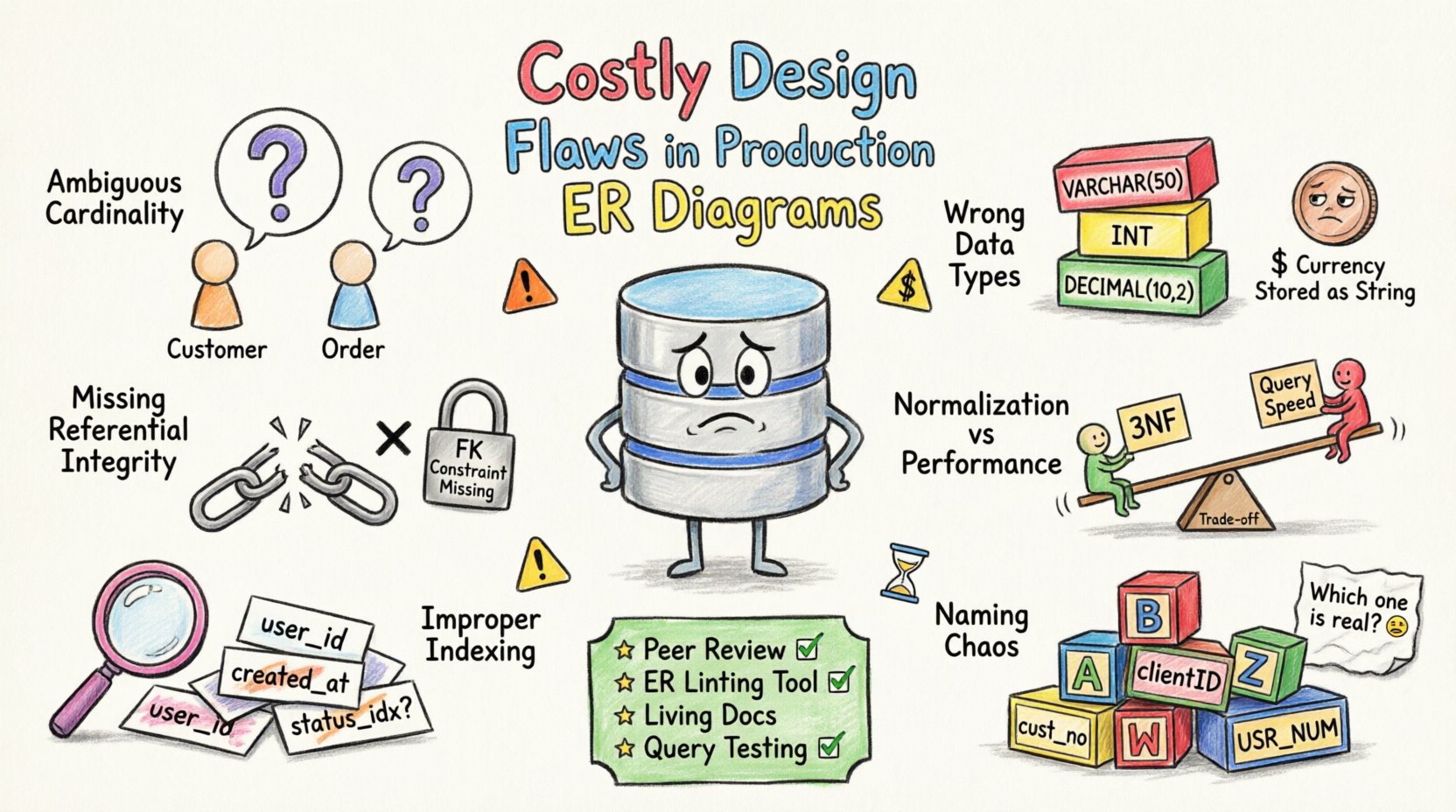
1. Cardinalité et relations ambiguës 🔗
La cardinalité définit la relation numérique entre les entités. Une cardinalité incorrecte entraîne des erreurs logiques lors de la récupération et du stockage des données. Une erreur courante consiste à supposer une relation un à un alors qu’une relation un à plusieurs existe.
- Omission de la relation plusieurs à plusieurs :L’absence de création d’une table de jonction pour les relations plusieurs à plusieurs oblige à la duplication des données ou à des requêtes de jointure complexes.
- Clés étrangères non définies :Sans clés étrangères explicites, la base de données ne peut pas garantir l’intégrité référentielle, permettant ainsi l’existence de données orphelines.
- Facultatif vs. Obligatoire :Classer à tort une relation obligatoire comme facultative introduit des valeurs nulles là où des données sont attendues.
Par exemple, considérons un client et une commande. Si le diagramme suggère qu’un client peut exister sans commande, mais que la logique de l’application l’exige, la base de données stockera des profils incomplets. Cette incohérence provoque des plantages de l’application ou des rapports incohérents.
2. Sélection incohérente des types de données 📊
Les types de données déterminent la manière dont les informations sont stockées et traitées. Choisir le mauvais type consomme un espace de stockage inutile ou limite la plage de valeurs. Les problèmes de précision surviennent souvent lorsqu’on utilise des nombres à virgule flottante pour les montants en monnaie.
- Dépassement d’entier :Utiliser des entiers petits pour les identifiants peut entraîner des erreurs de dépassement à mesure que les données augmentent.
- Longueur du texte :Utiliser des champs de caractères de longueur fixe gaspille de l’espace pour les données de longueur variable.
- Précision de la date :Le stockage des dates sans fuseaux horaires crée des problèmes de synchronisation dans les systèmes distribués.
Choisir un champ texte générique pour les numéros de téléphone est une autre erreur fréquente. Cela permet à des caractères non valides d’entrer dans le système, compliquant la logique de validation ultérieurement. Les champs numériques doivent être utilisés pour les calculs, et les champs texte uniquement pour les données alphanumériques.
3. Contraintes d’intégrité référentielle manquantes 🔒
L’intégrité référentielle garantit que les relations entre les tables restent cohérentes. Sans ces contraintes, la base de données dépend du code de l’application pour maintenir l’exactitude des données, ce qui est sujet aux erreurs humaines.
- Pas de règles de cascade :La suppression d’un enregistrement parent sans règles de cascade laisse les enregistrements enfants en suspens dans la base de données.
- Contraintes manquantes :Compter sur la validation au niveau de l’application plutôt que sur les contraintes de la base de données est insuffisant.
- Suppressions douces :Une gestion incorrecte des enregistrements supprimés crée du désordre et ralentit les performances des requêtes.
Lorsque les contraintes sont absentes, l’intégrité des données repose entièrement sur les développeurs d’applications. Si un bogue permet une écriture directe dans la base de données, les incohérences deviennent permanentes. C’est une cause principale de corruption des données dans les systèmes de production à long terme.
4. Normalisation vs. compromis performance ⚖️
La normalisation réduit la redondance, mais peut augmenter la complexité des requêtes. Une sur-normalisation entraîne des jointures excessives, tandis qu’une sous-normalisation provoque des anomalies de mise à jour. Trouver un équilibre est crucial pour les performances.
- Troisième forme normale (3FN) : Souvent idéal pour les systèmes transactionnels, mais peut nécessiter une dénormalisation pour les charges de travail intensives en lecture.
- Dénormalisation :L’introduction de redondance pour améliorer les performances doit être documentée afin d’éviter les conflits de mise à jour.
- Complexité des requêtes :Les schémas fortement normalisés nécessitent des jointures complexes qui sollicitent fortement le moteur de base de données.
Les équipes normalisent souvent de façon excessive pour garantir la pureté des données, en ignorant le coût de la jointure de plusieurs tables. Dans les environnements à fort trafic, cela entraîne des temps de réponse lents. Une dénormalisation stratégique peut améliorer les performances de lecture, à condition que les opérations d’écriture soient correctement gérées.
5. Stratégie d’indexation inappropriée 🏷️
Les index accélèrent la récupération des données, mais ralentissent les opérations d’écriture. Un modèle ERD défectueux échoue souvent à tenir compte de la manière dont les données seront interrogées. Cela entraîne des analyses de table entière et une latence élevée.
- Index manquants sur les clés étrangères :Les jointures sur des colonnes non indexées sont coûteuses en calcul.
- Sur-indexation :Trop d’index augmentent la latence des écritures et les besoins en stockage.
- Ordre des index composés :Un ordre incorrect des colonnes dans les index composés les rend inefficaces.
Un index sur une colonne fréquemment interrogée est une pratique standard. Toutefois, ignorer les modèles de requête pendant la phase de conception conduit à des chemins d’accès inefficaces. Une revue régulière des plans d’exécution des requêtes est nécessaire pour ajuster les stratégies d’indexation.
6. Chaos des conventions de nommage 🏷️
Des conventions de nommage cohérentes sont essentielles pour la maintenabilité. Des noms de tables et de colonnes incohérents rendent le schéma difficile à comprendre et à modifier.
- Majuscules et minuscules mélangées :Utiliser camelCase à certains endroits et snake_case à d’autres crée de la confusion.
- Abréviations ambigües :Des noms courts comme « cust » ou « ord » manquent de clarté pour les nouveaux membres de l’équipe.
- Mots réservés :Utiliser des mots réservés comme noms de tables provoque des erreurs de syntaxe dans les requêtes.
Une nomenclature claire réduit la charge cognitive des développeurs et des administrateurs de bases de données. Elle facilite également la génération automatique de documentation et réduit la probabilité d’erreurs de frappe dans les instructions SQL.
Analyse des impacts des défauts courants
| Défaut de conception | Impact technique | Coût des affaires |
|---|---|---|
| Clés étrangères manquantes | Enregistrements orphelins, incohérence des données | Perte de données, violations de conformité |
| Types de données incorrects | Perte d’espace de stockage, erreurs de calcul | Incohérences financières, erreurs de reporting |
| Sur-normalisation | Performance de requête lente, latence élevée | Expérience utilisateur lente, perte de revenus |
| Index manquants | Balayages complets de table, contention de verrouillage de base de données | Arrêts du système, faible évolutivité |
| Mauvais nommage | Haute charge de maintenance, taux d’erreurs élevés | Temps de développement accru, bogues |
Stratégies de prévention 🛡️
Empêcher ces défauts exige une approche rigoureuse de la conception de base de données. Les étapes suivantes aident à atténuer les risques avant le déploiement.
- Revue par les pairs : Mettre en place des revues obligatoires du schéma avant toute fusion de modifications.
- Linting automatisé : Utiliser des outils pour vérifier les conventions de nommage et les normes structurelles.
- Documentation : Maintenir des diagrammes ERD à jour qui reflètent le schéma réel.
- Tests : Exécuter des tests de validation du schéma dans l’environnement de préproduction avant la production.
Adopter un processus de contrôle de version pour les schémas de base de données garantit que les modifications sont suivies et réversibles. Cela permet aux équipes d’identifier quand un défaut a été introduit et de revenir en arrière si nécessaire. La collaboration entre développeurs et architectes est essentielle pour détecter les problèmes tôt.
Considérations pour la maintenance à long terme 🔄
Les schémas de base de données évoluent au fil du temps. Un design qui fonctionne aujourd’hui peut ne pas convenir aux besoins futurs. Les audits réguliers aident à identifier la dette technique et les modèles obsolètes.
- Décalage du schéma : Surveiller les différences entre le MCD et la base de données en production.
- Dépréciation :Planifier la suppression des tables et des colonnes inutilisées.
- Évolutivité :Concevoir en tenant compte du partitionnement et du fractionnement pour de grandes quantités de données.
Ignorer la maintenance conduit à un système fragile qui résiste aux changements. Une gestion proactive garantit que la base de données reste une fondation fiable pour l’application. Investir du temps dans la conception initiale rapporte des bénéfices tout au long du cycle de vie du logiciel.
Pensées finales sur l’intégrité du schéma 📝
Les erreurs de base de données en production sont souvent le résultat de détails négligés lors de la phase de conception. En traitant la cardinalité, les types de données, les contraintes et l’indexation, les équipes peuvent construire des systèmes plus résilients. Le coût de la correction d’un défaut en production est nettement plus élevé que celui de sa prévention lors de la modélisation.
Portez votre attention sur la clarté, la cohérence et la validation. Un MCD bien structuré est le pilier de la fiabilité des données. Privilégiez la qualité plutôt que la vitesse pour assurer une stabilité à long terme. Cette approche minimise les risques et maximise la valeur des données stockées dans le système.