











设计一个稳健的数据架构,远不止于画框和连线。它需要深入理解数据如何流动、增长以及随时间相互作用。当系统扩展时,实体关系模型(ERD)作为逻辑一致性的蓝图,而分区策略则解决物理性能问题。将这两个方面协调一致,对于保持查询速度、数据完整性和运营效率至关重要。本指南探讨如何在不引入不必要的复杂性或风险的情况下,将分区技术与您现有的数据模型相协调。
🧩 基础:ERD作为蓝图
在考虑如何拆分数据之前,必须先理解连接数据的关系。ERD定义了实体、属性以及它们之间的基数关系。这些关系决定了数据如何被检索和连接。当你引入分区时,实际上是在将这些逻辑关系分布到物理存储边界上。
请考虑分区对您的模式可能带来的以下影响:
- 主键: 必须仔细选择,以确保在各个分区之间均匀分布。
- 外键: 在不同分区中的表进行连接可能会带来显著的开销。
- 索引: 如果未考虑分区键进行设计,全局索引可能会成为瓶颈。
- 数据局部性: 相关数据应尽可能位于同一节点上,以最小化网络延迟。
忽视这些因素可能导致一种情况:逻辑模型在设计上运行完美,但物理实现却在负载下举步维艰。目标是让相关数据尽可能靠近,同时允许各自独立扩展。
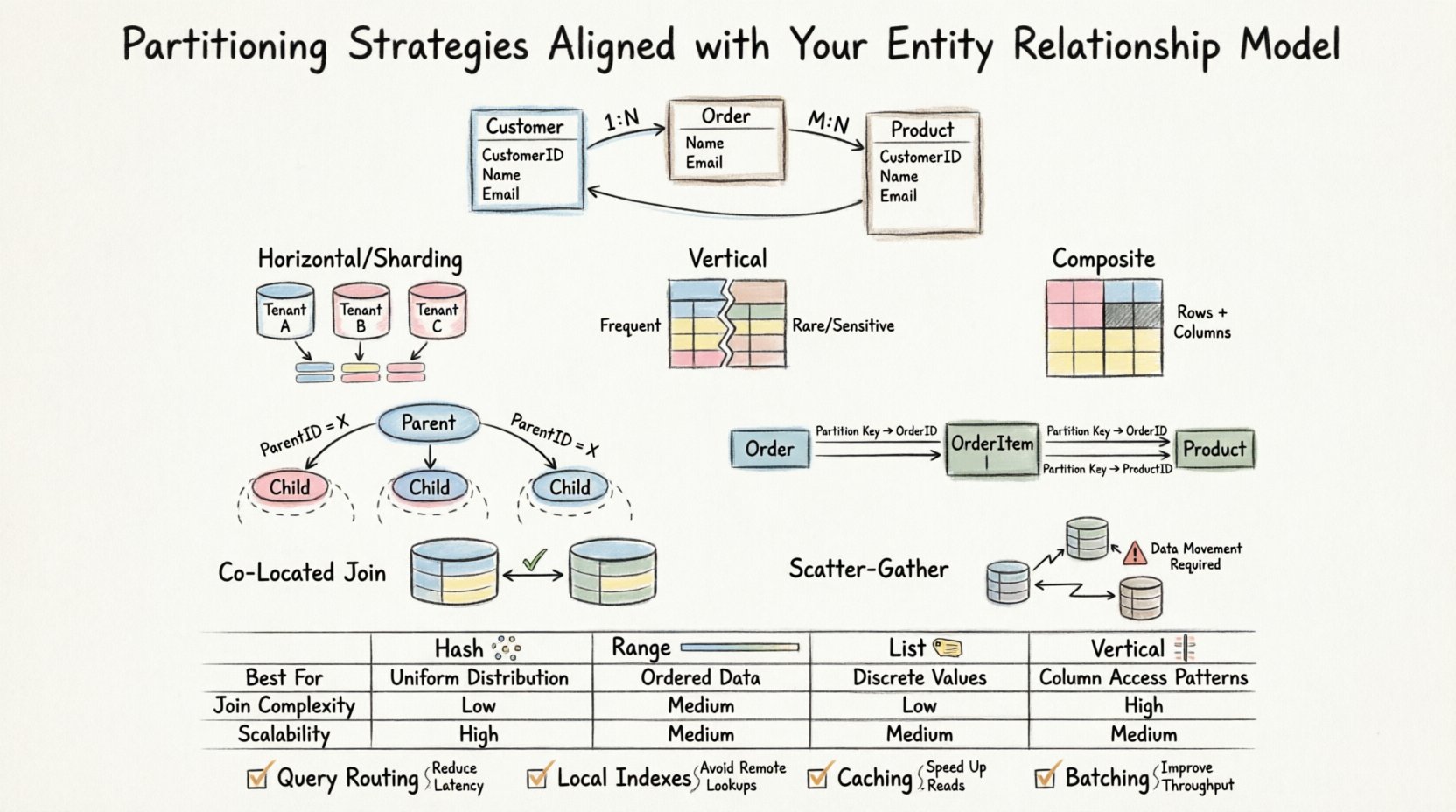
🔄 分区类型与模式匹配
不同的分区方法适用于不同的数据访问模式。选择合适的方法在很大程度上取决于您的ERD如何定义关系以及预期的查询模式。以下是常见策略的分解,以及它们如何与关系结构相互作用。
水平分区(分片)
水平分区将表的行拆分为不同的组。当表变得过大,无法在单个实例中管理时,通常会使用这种方法。在ERD的背景下,当分区键与自然访问模式相关时,该策略效果最佳。
- 使用场景: 具有明确用户或租户分组的大型事务性表。
- ERD影响: 指向父表的外键必须谨慎管理。如果父表也进行了分区,这些键必须对齐。
- 优势: 通过增加更多节点,实现大规模扩展。
- 挑战: 跨越多个分区的复杂查询需要聚合逻辑。
垂直分区
垂直分区将表的列拆分为不同的组。当某些列很少被一起访问,或敏感数据需要隔离时,这种方法非常有用。
- 使用场景: 行宽的表,其中只有部分列被频繁查询。
- ERD影响: 主键必须存在于所有垂直分区中,以允许重建完整行。
- 优势: 通过仅将必要列加载到内存中,减少I/O操作。
- 挑战: 需要连接操作来重建完整实体,增加了查询复杂性。
复合分区
这种方法结合了水平和垂直策略。在行数和列宽都是显著约束的高性能系统中,通常需要采用此方法。
- 使用场景: 数据仓库或高频交易日志。
- ERD影响: 实施前需要有严格的模式定义。
🔑 将键与关系对齐
此过程最关键的一步是选择分区键。该键决定了哪一行被分配到哪个物理存储单元。在关系型上下文中,分区键最好与外键关系相匹配。
父-子关系
在处理一对多关系时,子表通常比父表增长得快得多。如果按父ID对子表进行分区,则所有相关的子记录都位于同一节点上。
- 优势: 查询父表及所有子记录时,无需跨节点通信。
- 优势: 删除操作可在单个分区内部高效级联。
- 警告: 如果某个父记录的子记录数量远超其他记录,可能会导致数据倾斜。
多对多关系
多对多关系通常涉及一个连接表。如果分区不当,该表可能成为性能瓶颈。
- 策略: 按其中一个涉及的外键进行分区。
- 策略: 确保查询始终通过分区键进行过滤,以避免全表扫描。
- 策略: 除非绝对必要,否则避免在多个分区之间连接连接表。
⚖️ 处理连接操作
连接是关系型数据库的生命线,但当数据被分割时,连接操作会变得昂贵。理解连接在分区之间的行为对于保持性能至关重要。
共置分区
如果表A和表B使用相同的键(例如Tenant_ID)进行分区,则它们之间的连接操作会在本地发生。数据库引擎无需在节点之间移动数据。
- 要求:两个表必须使用相同的分区算法和键。
- 要求:ERD必须在逻辑上支持这种对齐。
散射-聚集连接
当表被不同方式分区时,系统必须从多个节点获取数据,聚合结果,然后返回最终集合。这被称为散射-聚集操作。
- 性能开销: 高网络开销。
- 性能开销: 延迟增加。
- 建议: 在ERD设计阶段尽量减少此类连接。
🛡️ 跨分区保持完整性
当数据分布时,数据完整性约束更难强制执行。ERD在逻辑上定义这些规则,但实现必须处理物理分布。
- 引用完整性:如果子记录和父记录位于不同节点上,则在插入父记录前确保子记录存在会变得复杂。
- 唯一性约束: 全局唯一性需要在所有分区之间进行协调。
- 触发器: 在分布式环境中,应用层触发器通常替代数据库层触发器,以避免锁定问题。
- 事务: 分布式事务会影响吞吐量。只要可能,应将事务保持在单个分区内部。
📊 分区策略对比
下表总结了不同策略如何与常见的ERD场景相互作用。
| 策略 | 适用于ERD场景 | 连接复杂性 | 写入可扩展性 |
|---|---|---|---|
| 哈希分区 | 需要均匀分布,无特定范围 | 高(随机分布) | 高 |
| 范围分区 | 基于日期或顺序的ID | 低(如果对齐) | 中等 |
| 列表分区 | 固定类别(例如,区域、状态) | 低(如果对齐) | 高 |
| 垂直分区 | 宽行,不频繁的列 | 中等(需要重建) | 高 |
🔄 演进与迁移
模式演进不可避免。业务需求会变化,新的属性会被添加。修改ERD时,必须重新审视分区策略。
- 添加列:垂直分区使添加列更简单,因为它们可以放置在新的分区上。
- 更改键:重新分区现有数据是一项繁重的操作。应在初始设计阶段就为此做好规划。
- 归档:分区使得可以轻松归档旧数据范围,而不会影响活跃分区。
- 监控:定期检查分区大小,确保没有单个分区成为热点。
🚀 性能优化建议
为确保系统保持响应性,应在应用分区策略的同时,实施特定的优化措施。
- 查询路由: 确保应用程序根据分区键将查询发送到正确的分区节点。
- 索引: 本地索引比全局索引更快。设计索引时应与分区键相匹配。
- 缓存: 如果频繁访问的查找表足够小,可以容纳在所有节点的内存中,则不应进行分区。
- 批处理: 批量插入和更新以减少跨分区的事务开销。
🔍 最终考虑事项
构建一个可扩展的系统需要在逻辑清晰性与物理限制之间取得平衡。实体关系模型提供了数据一致性的规则,而分区则提供了增长的机制。当这两者一致时,即使数据量呈指数增长,系统也能保持高性能。
关注模型中定义的关系。如果数据按某个特定属性自然分组,则使用该属性作为分区键。如果连接操作频繁,确保相关表采用相同的分区逻辑。避免因没有明确性能目的而过度复杂化模式。
遵循这些原则,可以建立一个支持长期稳定性的基础。目标不仅仅是存储数据,而是以一种使系统能够适应未来需求而无需彻底重构的方式对数据进行结构化。在设计阶段进行仔细规划,可以显著节省运营阶段的工程工作量。