









在可扩展软件架构的领域中,多租户的概念是基础性的。一个应用程序实例为多个客户(称为租户)提供服务,同时保持数据的逻辑隔离。设计底层数据结构需要精确性。实体关系图(ERD)为此架构提供了蓝图。它们可视化了表、键和约束之间的关系,这些关系在租户之间强制执行数据完整性。 📐
在为多租户环境构建ERD时,主要挑战在于平衡隔离性、性能和成本。没有一种方案适用于所有场景。相反,架构师必须选择一种与安全要求和运营预算相匹配的模式。本文探讨了建模这些架构的核心策略,深入剖析了技术实现细节,而无需依赖特定厂商工具。 🛠️
理解核心模式 🔍
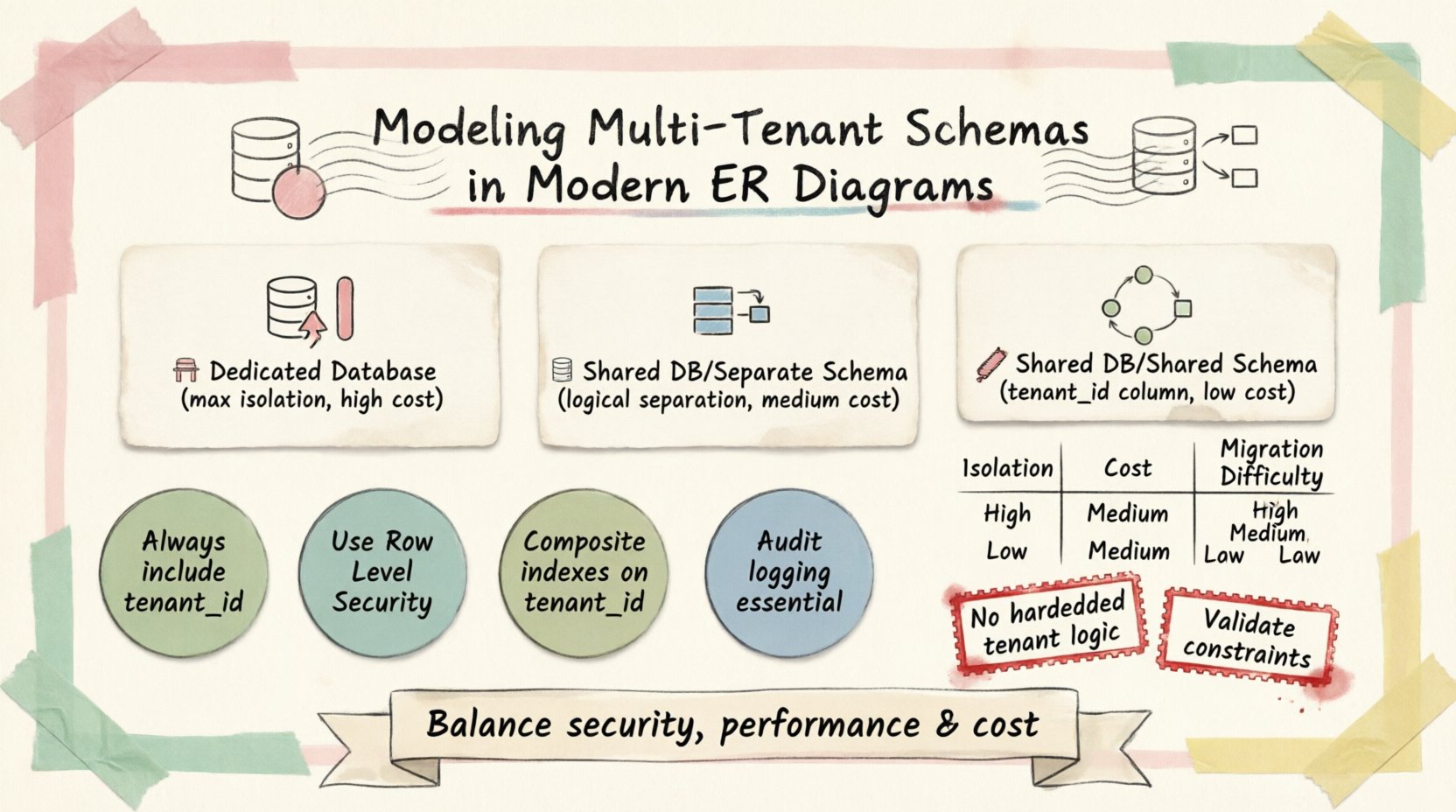
多租户建模的基础在于租户数据的物理存储方式和逻辑隔离方式。行业内有三种截然不同的模式占据主导地位。每种模式在数据隔离和维护复杂性方面都具有独特的权衡。
1. 每个租户专用数据库 🏢
在此方法中,每位客户都会获得一个独立的数据库实例。所有实例的ERD结构保持一致,但物理边界非常严格。
- 隔离级别:最高。一个数据库的故障不会影响其他数据库。
- 安全性:高。物理隔离可防止意外的数据泄露。
- 成本:较高,因为每个实例都存在资源开销。
- 迁移:复杂。模式变更需要在每个实例上运行脚本。
从ERD的角度来看,这种模式看起来像一个标准的单租户图。然而,部署流水线必须管理多个连接。这通常用于对合规性要求严格的大型企业客户。
2. 共享数据库,独立模式 📂
在此模式中,所有租户都位于同一个数据库系统中,但每个租户都有自己的独立模式(命名空间)。每个模式中都会复制表。
- 隔离级别:高。数据库引擎内部的逻辑隔离。
- 安全性:强。访问控制列表(ACL)可以限制模式的可见性。
- 成本:中等。共享数据库引擎的开销。
- 维护:比专用数据库更容易,但模式更新必须传播到所有模式。
在ERD中,这通过将表分组到特定的命名空间标签下进行表示。关系保持一致,但图的范围扩大,以显示多个模式容器。
3. 共享数据库,共享模式 🔗
这是通用SaaS应用中最常见的模式。所有数据都存储在相同的表集中,通过一个特定列进行区分。
- 隔离级别: 合理。所有行都存在于同一张表中。
- 安全性: 取决于应用程序逻辑和行级安全(RLS)。
- 成本: 最低。最大化资源利用率。
- 维护: 简单。模式更改会立即应用于所有租户。
此模式的ERD引入了一个关键列:tenant_id。此外键将每条记录链接到特定客户。它是该模型中数据隔离的基石。
在ERD中可视化租户数据 📊
为多租户创建有效的ERD需要使用特定的符号来清晰传达分区策略。利益相关者需要理解数据的流动方式以及边界所在位置。
租户ID列
在共享模式中,tenant_id必须出现在存储用户特定数据的每张表中。这并非可选。如果在事务表中遗漏此列,可能导致严重的数据泄露。
- 主键: 通常,
tenant_id与本地ID的组合形成复合主键。 - 索引: 对性能至关重要。按
tenant_id进行过滤的查询必须快速。 - 约束: 外键通常引用一个中心
tenants主表。
主租户表
通常会有一个专用表来存储每个租户的元数据。该表包含配置详情、订阅状态和账单信息。
- 关键属性:租户ID、名称、计划层级、创建日期。
- 关系:与其他所有数据表为一对多关系。
比较模式策略 📋
为了做出明智的决策,请使用下面的表格比较每种策略的运营影响。
| 功能 | 专用数据库 | 共享模式 | 共享表 |
|---|---|---|---|
| 数据隔离 | 物理 | 逻辑 | 逻辑 |
| 查询复杂度 | 简单 | 复杂 | 复杂 |
| 资源成本 | 高 | 中等 | 低 |
| 模式迁移 | 困难 | 中等 | 简单 |
| 备份策略 | 细粒度 | 细粒度 | 完整转储 |
安全与数据分区 🔒
建模数据结构只是完成了一半工作。数据访问层必须强制执行图中定义的边界。使用共享表时,目标是实现逻辑隔离。
行级安全(RLS)
现代数据库引擎支持RLS,它在行级别强制执行访问策略。这使得数据库本身可以根据当前用户上下文过滤结果。
- 策略定义: 一条规则指出,只有当
tenant_id与会话匹配时,该行才可见。 - 实现: ERD应体现存储会话上下文的能力。
- 优势: 降低应用程序级错误导致数据泄露的风险。
审计与日志记录
对租户特定数据的每一次更改都应被记录。ERD中必须包含审计表,以追踪谁在何时修改了什么内容。这对合规性和调试至关重要。
- 必需字段: 租户ID、用户ID、操作、时间戳、旧值、新值。
- 保留策略: 策略必须明确日志的保留时长。
性能考虑 ⚡
共享表会增加查询执行计划的复杂性。随着数据量的增长,数据库引擎必须高效地分离租户数据,而无需扫描整个表。
索引策略
标准索引不足以满足需求。你需要使用以租户标识符为优先的复合索引。
- 主索引: 应以
tenant_id开头,然后是自然键。 - 查询优化: 确保所有查询都在
WHERE子句中包含租户过滤条件。 - 分区: 某些系统允许按以下方式对表进行物理分区:
tenant_id范围或哈希。
查询复杂性
在跨多个模式或租户的表之间进行连接时,连接条件必须包含租户ID。如果未这样做,可能会导致来自不同客户的数据显示为笛卡尔积。
- 连接逻辑: 始终按以下条件进行连接:
tenant_id以及关系键。 - 应用层: 中间件应自动注入租户过滤器。
维护与迁移 🔄
模式并非静态的。随着需求的变化而演变。多租户为这些变更增加了额外的复杂性。
模式演进
在共享表中添加列很简单。删除列会影响所有租户。在专用数据库模型中,必须为每个实例编写变更脚本。
- 版本控制: 跟踪模式版本以管理向后兼容性。
- 回滚: 如果迁移在部分租户上失败,应有计划地回滚变更。
备份与恢复
恢复策略因模式而异。专用数据库允许您恢复单个租户而不影响其他租户。共享数据库则需要恢复整个实例。
- 粒度: 共享表使得对单个租户进行时间点恢复变得困难。
- 测试: 定期在预发布环境中测试恢复流程。
常见陷阱需避免 ⚠️
即使拥有设计良好的ERD,实现错误仍可能危及系统。务必警惕这些常见问题。
- 硬编码租户逻辑: 永远不要在应用代码中硬编码租户ID。应使用配置或会话上下文。
- 全局变量: 避免将租户上下文存储在可能跨请求持续存在的全局变量中。
- 缺失约束: 如果数据库未强制执行
tenant_id唯一性,应用程序必须严格验证。 - 忽略分析: 为报告目的跨租户聚合数据需要仔细处理,以避免敏感信息混杂。
命名规范的最佳实践 🏷️
命名的一致性有助于开发人员立即理解数据结构。如果共享模式中存在租户特定的表,请使用前缀或后缀进行标识。
- 表命名:
tenant_name_orders或orders_tenant_id. - 列命名: 始终显式包含
tenant_id显式包含在每个记录表中。 - 索引: 清晰命名索引,例如
idx_orders_tenant_id.
架构选择的结论 🎯
选择合适的多租户模式需要在技术可行性与业务需求之间取得平衡。ERD 是将这一选择传达给整个团队的工具。无论选择物理隔离以确保安全,还是共享表以提高效率,图表都必须清晰地展示边界。
通过遵循严格的建模标准、实施强大的索引并保持清晰的分离逻辑,你可以构建一个可安全扩展的系统。当基础稳固时,租户的复杂性是可以管理的。从图表的第一行开始,就应关注数据完整性和性能。 🚀