











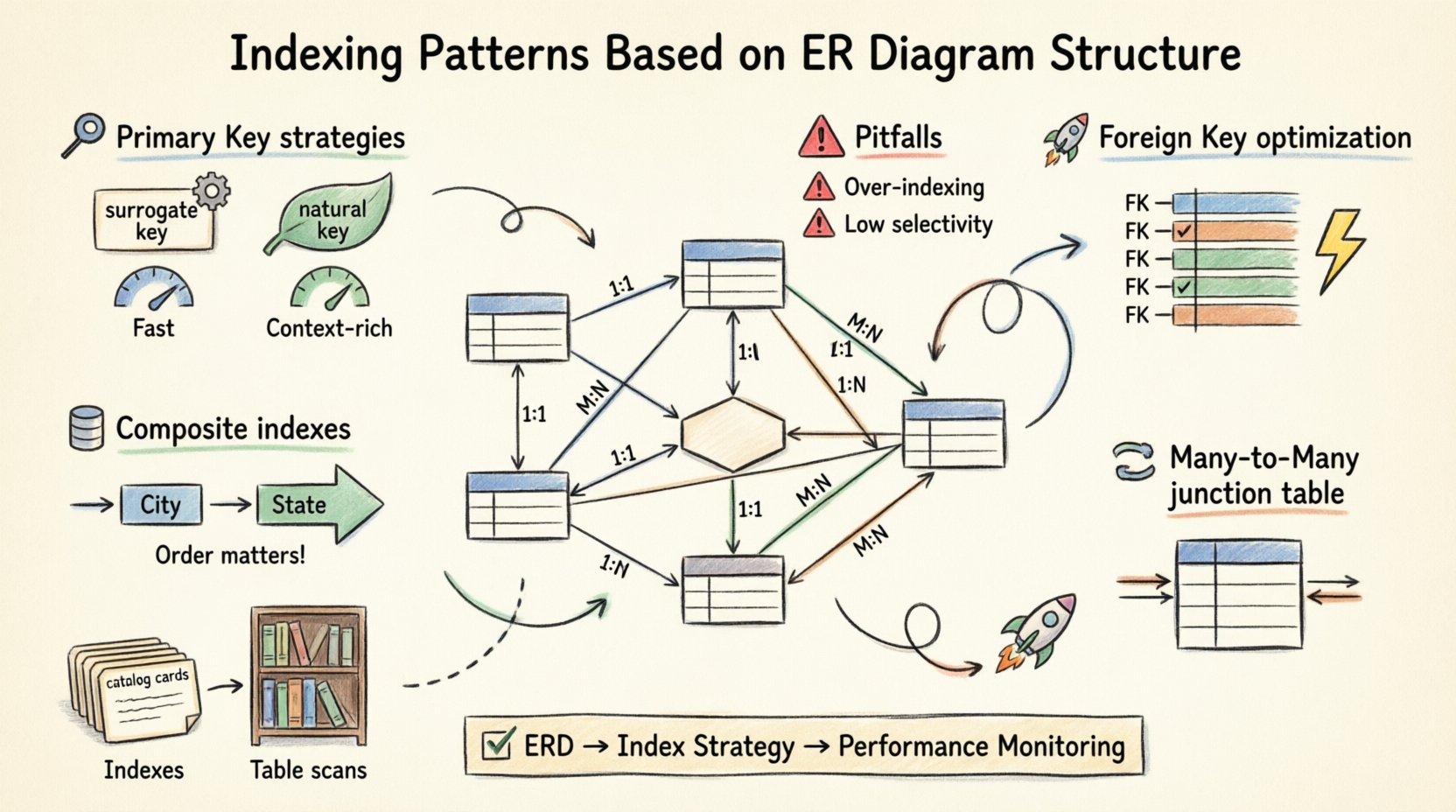
设计一个健壮的数据库,其起点远在第一个查询运行之前。它始于蓝图:实体关系图(ERD)。📏 虽然许多开发人员关注表的创建和列类型,但真正决定性能的关键在于索引如何与你的数据模型相匹配。索引不仅仅是配置设置;它是你逻辑关系的物理体现。
当你构建ERD时,你定义了数据的基数和连接性。这些结构上的选择决定了最高效的索引策略。一对一关系的处理方式与多对多关联截然不同。忽视这些细微差别通常会导致连接缓慢、I/O操作过多以及存储碎片化。本指南探讨如何将你的ERD转化为高性能的索引模式,而无需依赖特定厂商的工具。
🔑 理解基础:ER图与索引
ER图不仅仅是视觉辅助工具;它是应用程序逻辑与存储引擎之间的契约。实体之间每一条连线都代表数据库必须强制执行的约束。索引的作用是加速这些约束的执行以及跨约束的数据检索。
将存储层视为一个图书馆。如果没有索引,查找一本书需要扫描每一排书架(即全表扫描)。索引就像是目录卡片。然而,如果目录卡片放置不当——例如,当作者是主要搜索键时却按类别排序——就会导致系统效率低下。你的ER图会告诉你作者和类别是谁,以及哪些关系最为关键。
关键考虑因素包括:
- 基数:高基数列(唯一值)最受益于索引。
- 连接频率:频繁连接的表需要在外键上进行特定索引。
- 写入量:每个索引都会增加插入和更新操作的开销。
- 查询模式:你是如何过滤的?如何排序的?ER图会暗示答案。
🏗️ 主键索引策略
主键(PK)是每张表的支柱。它保证唯一性,并在许多系统中提供数据存储的聚簇机制。将你的索引策略与主键定义对齐,是第一步。
1. 代理键与自然键
在代理键(自增ID)和自然键(如电子邮件或社会安全号码)之间进行选择,会显著影响索引性能。
- 代理键: 它们非常适合聚簇。它们短小、单调递增且连续。这能最大限度地减少写入时的页分裂和碎片化。📈
- 自然键: 虽然在语义上具有意义,但它们可能很长、长度可变,或容易发生变化。与基于整数的键相比,对它们建立索引可能导致索引尺寸更大,查找速度更慢。
2. 聚簇索引的影响
在大多数架构中,主键定义了聚簇索引。这意味着实际的数据行按键的顺序物理存储。如果你的ERD表明查询经常按某个特定的自然属性进行过滤,你可能需要重新考虑主键的定义,或者接受聚簇索引将只为一种查询类型优化,而其他查询则由二级索引处理。
🔗 外键优化
外键(FK)定义了表之间的关系。如果未建立索引,它们是最常见的性能瓶颈来源。当你连接两张表时,数据库引擎必须根据外键列匹配行。如果没有索引,该操作会退化为嵌套循环扫描,这对大型数据集来说计算成本极高。
1. 对外键列建立索引
始终在外键列所在的子表上创建索引。这使得引擎能够快速定位相关行,而无需扫描整个表。
| 场景 | 索引要求 | 性能影响 |
|---|---|---|
| 一对多(子表) | 在子表中索引外键 | 可实现对父表数据的快速查找 |
| 多对一(父表) | 在父表中索引主键(通常为默认) | 标准主键行为 |
| 级联删除 | 索引外键 + 父表主键 | 防止删除时锁定整个表 |
2. 复合外键
有时,一个关系依赖于多个列(例如,父表中的复合键)。在这种情况下,您必须在子表上创建一个复合索引,其列顺序和列必须与父键匹配。索引中的列顺序不匹配会导致其在连接操作中失效。
🔀 处理多对多关系
多对多(M:N)关系通过一个连接表来解决。该表包含指向两个父表的外键。这里的索引策略对性能至关重要。
考虑这样一个场景:学生注册了课程。连接表将它们关联起来。要查找某个学生的所有课程,需要高效地查询连接表。
- 双向索引:您应独立地对两个外键列进行索引。这样可以从任一方向查询关系(学生 → 课程 或 课程 → 学生),而无需全表扫描。
- 复合索引:如果您的查询总是获取特定学生的课程,那么在(学生ID,课程ID)上建立复合索引比使用两个独立索引更高效。它可以在一次查找中覆盖所有搜索条件。
📊 复合索引和覆盖索引
并非所有查询都只按单个列过滤。复杂查询通常涉及多个条件。这正是复合索引发挥作用的地方。复合索引是基于多个列构建的单一索引。
1. 列顺序很重要
复合索引中列的顺序并非随意。数据库引擎只能利用索引到等值条件停止的位置为止。例如,如果您对(城市,州)建立索引,按城市过滤的查询将使用该索引。而仅按州过滤的查询很可能忽略该索引。
2. 覆盖索引
覆盖索引包含满足查询所需的所有列,包括SELECT列表中的列。这使得数据库可以直接从索引树中获取数据,而无需访问主表(堆)。这对于读取密集型操作来说是巨大的性能提升。
⚠️ 常见陷阱与最佳实践
即使ERD设计完美,实现错误仍可能导致性能下降。以下是将结构转换为存储时应避免的常见陷阱。
- 过度创建索引:每个索引都会占用磁盘空间并减慢写入操作。仅对经常查询或用于约束的列创建索引。
- 选择性低:对低基数列(例如布尔型“is_active”标志)创建索引通常效率低下。优化器可能认为全表扫描比跳转到索引更快。
- 忽略空值:不同数据库引擎对空值的索引处理方式不同。请确保您的查询逻辑考虑到在特定配置下空值的索引方式。
- 碎片化:随着时间推移,索引会变得碎片化。需要定期维护以保持性能最优。
🛠️ 性能监控与维护
一旦确立了索引策略,监控就至关重要。无法优化你无法衡量的内容。定期审查查询执行计划,以确认索引是否被有效使用。
1. 分析执行计划
注意“索引扫描”与“索引查找”等操作。查找是高效的,而扫描则不是。如果在大表上看到全表扫描,应根据实际查询模式重新审视索引策略。
2. 跟踪索引使用情况
有时创建了索引却从未使用。这些是无用负担。定期审计索引使用统计信息,识别出可删除的未使用索引,以提升写入性能。
3. 数据增长考量
随着数据量增长,维护成本也随之增加。一个在1万行数据下表现良好的索引,在1000万行时可能成为瓶颈。随着数据集规模扩大,应重新评估基于ERD的索引模式。同时,分区策略也可能需要与索引配合使用。
🔄 对齐总结
将索引策略与ERD结构对齐是一个持续的过程。这需要理解设计中定义的数据关系,并将其转化为物理存储优化。
- 主键:用于聚簇和唯一性。
- 外键:为连接性能创建索引。
- 关联表:为多对多关系创建双向索引。
- 查询模式:根据特定的筛选顺序定制复合索引。
通过尊重ERD的结构完整性,您将构建一个可平稳扩展的数据库。您能避免临时索引的常见陷阱,并确保随着应用程序的演进,数据始终保持可访问且高性能。这种严谨的方法确保数据库能够支持您的业务逻辑,而不会成为瓶颈。🚀