











データベースアーキテクチャはほとんど常に静的ではない。アプリケーションが成長し、要件が変化するにつれて、基盤となるデータ構造も適応しなければならない。このプロセスはスキーマ進化と呼ばれる。しかし、本番データベースに変更を導入することは大きなリスクを伴う。1つの誤った制約や削除されたカラムが、アプリケーションの機能停止や重要なデータの破損を引き起こす可能性がある。これらのリスクを軽減するために、エンジニアたちはエンティティリレーションシップモデル(ERM)に基づいた堅牢な検証戦略に頼っている。🛡️
デプロイ前にスキーマ進化を検証することで、論理的な変更が物理的制約と整合していることを保証する。設計意図と実行時の現実の間のギャップを埋める。ERモデルを真実の出所として利用することで、チームはライブデータに触れることなく、変更をシミュレートし、依存関係を確認し、互換性を検証できる。このアプローチによりダウンタイムが削減され、手動のマイグレーションスクリプトにしばしば伴う混乱を防ぐことができる。
なぜスキーマ進化が重要なのか 📉
現代の開発サイクルでは、データはすべての機能の基盤である。ビジネス要件が変化すると、データベースもその変化を反映する必要があることが多い。これは新しいフィールドの追加、テーブルの分割、またはデータ型の変更を意味する。構造化された検証プロセスがなければ、これらの変更は賭けになる。
進化中に発生する一般的な課題には以下が含まれる:
- 破壊的変更:アプリケーションが依存しているカラムを削除すると、すぐにエラーが発生する。
- パフォーマンスの低下:インデックスの追加やストレージエンジンの変更により、予期せぬ遅延がクエリに発生する可能性がある。
- データ整合性の喪失:不適切に定義された制約は、無効なデータがシステムに流入することを許す。
- ダウンタイム:マイグレーション中にテーブルをロックすると、アプリケーションがユーザーに利用できなくなる。
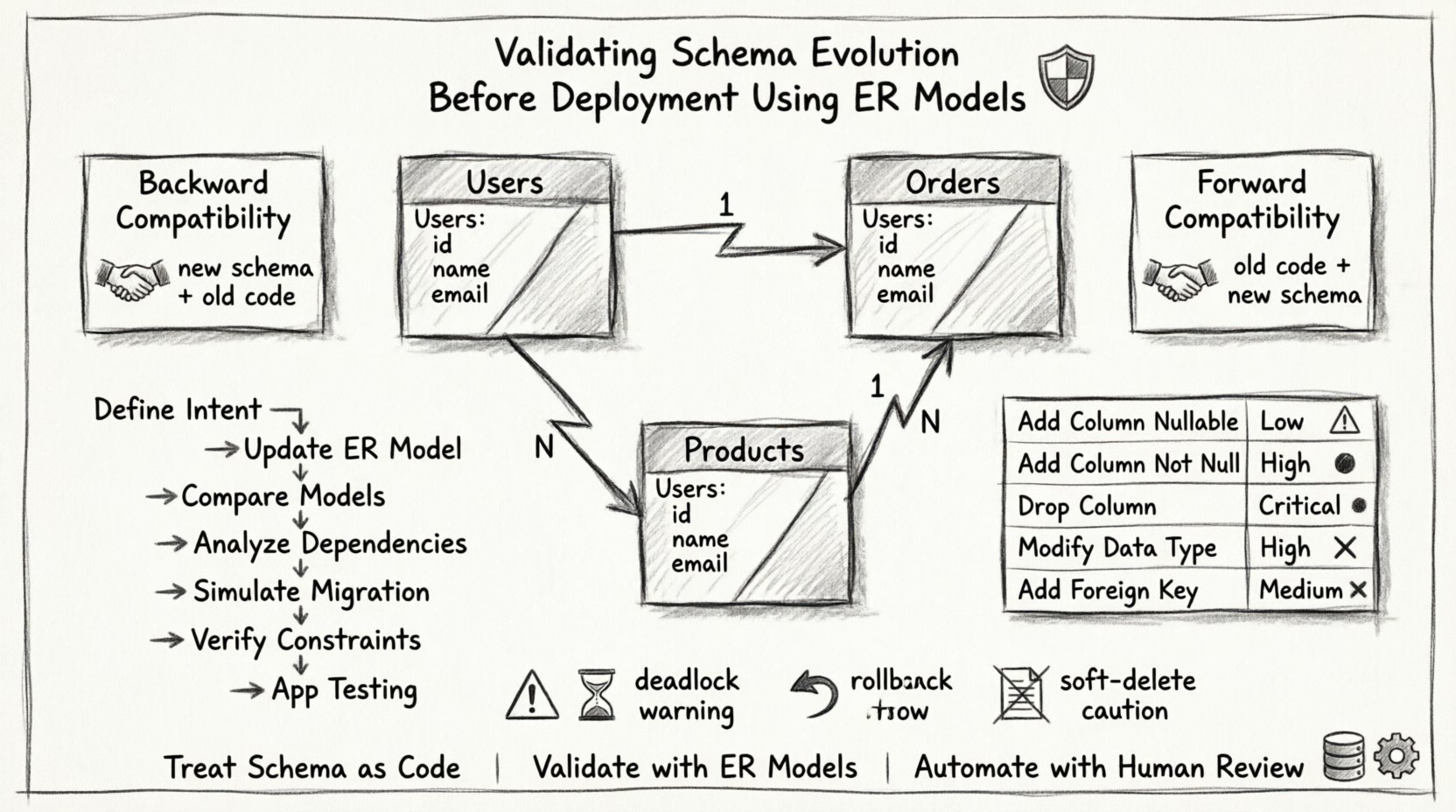
ERモデルを使用することで、アーキテクトはリスクが発生する前にそれを可視化できる。このモデルは、関係性、基数、制約を明確に示す設計図として機能する。 📐
検証におけるERモデルの役割 🧩
エンティティリレーションシップモデルは、データベースの論理構造を表す。エンティティ(テーブル)、属性(カラム)、関係性(外部キー)を定義する。進化の検証において、ERモデルは比較の基準となる。
このモデルが検証を支援する方法は以下の通りである:
- 依存関係マッピング:どのテーブルが他のテーブルに依存しているかを示す。親テーブルが変更された場合、子テーブルを確認しなければならない。
- 制約の検証:主キーと一意制約は一目で確認でき、更新時に違反されないことを保証する。
- 正規化の確認:新しい構造が正規化ルールに準拠していることを確認するのを助け、冗長性を防ぐ。
- 歴史的文脈:現在のER図と提案された図を比較することで、何が変更されたかを正確に把握できる。
ER図をバージョン管理されたアーティファクトとして扱うことで、チームは進化の履歴を時間とともに追跡できる。これにより、特定のスキーマ決定がなされた理由の監査証跡が作成される。
変更タイプの特定 🔍
すべてのスキーマ変更が同等というわけではない。安全な変更もあれば、複雑なマイグレーション戦略を要するものもある。変更を分類することで、必要な検証の深さを判断できる。
| 変更タイプ | リスクレベル | 検証の焦点 |
|---|---|---|
| 列の追加(NULL許容) | 低 | デフォルト値とストレージサイズを確認する。 |
| 列の追加(NOT NULL) | 高 | 既存のデータが制約を満たしていることを確認する、またはデフォルト値を提供する。 |
| 列の削除 | 重大 | アプリケーションコードがこの列を参照していないことを確認する。 |
| データ型の変更 | 高 | データの切り捨てや精度の損失がないか確認する。 |
| 外部キーの追加 | 中 | 既存の行全体で参照整合性が維持されていることを確認する。 |
これらのカテゴリを理解することで、エンジニアはテストの優先順位を適切に設定できる。重大な変更は手動でのレビューを要するが、低リスクの変更は自動化可能である。
互換性戦略 🔄
スキーマの変更をデプロイする際、アプリケーションとの互換性を維持することは重要である。主に考慮すべき2つの戦略がある:後方互換性と前方互換性。
後方互換性
これにより、新しいスキーマが古いアプリケーションコードと動作することを保証する。アプリケーションの更新より前にデータベースの変更をデプロイする場合、特に重要である。たとえば、列を追加した場合、古いコードが新しい列を無視してもクラッシュしてはならない。列を削除する場合、古いコードは依然として動作するか、同時に更新されなければならない。
前方互換性
これにより、古いアプリケーションが新しいスキーマを読み取ることができるようになる。データベースをアプリケーションより先に更新する場合に役立つ。たとえば、列を追加することで、古いクエリが新しいデータを使わなくてもエラーなく実行できる。
堅牢な検証プロセスは両方向を確認する。ERモデルは、変更がアプリケーションとデータベースの契約を破壊するかどうかを視覚化するのに役立つ。 🤝
検証プロセスのステップバイステップ 🚀
スキーマの変更を実行するには、厳密なワークフローが必要である。記憶や素早いスクリプトに頼るのは危険である。変更の検証を安全に行うため、この構造化されたアプローチに従う。
- 意図を明確にする:何が変更が必要か、なぜ変更するのかを明確に文書化する。これによりスコープクリープを防ぐ。
- ERモデルを更新する: 図の提案された状態を作成してください。物理データベースへの変更はまだ適用しないでください。
- モデルを比較する:現在のER図と提案されたER図の差分を生成する。追加、削除、または変更されたエンティティを特定する。
- 依存関係を分析する:外部キーとインデックスを追跡する。変更によって孤立した関係が生じないことを確認する。
- マイグレーションをシミュレートする:本番環境のデータ量を模倣したステージング環境でマイグレーションスクリプトを実行する。
- 制約を検証する:トリガー、チェック、制約が正しく適用されていることを確認する。
- アプリケーションテスト:新しいスキーマに対してアプリケーションを実行し、クエリが期待される結果を返すことを確認する。
自動化ツールはステップ3、5、6を支援できるが、複雑な論理については人間によるレビューが不可欠である。
データ整合性と制約 🛑
スキーマ進化において最も重要な点はデータ整合性である。紙面上では正しいように見える変更でも、数百万行のデータに適用すると失敗する可能性がある。ERモデルは制約を可視化するのに役立つが、検証には実データに対してテストを行う必要がある。
特に注目すべきポイントは以下の通りである:
- 主キー:一意性が損なわれていないことを確認する。
- 外部キー:デッドロックを引き起こす可能性のある循環依存関係がないか確認する。
- チェック制約:ビジネスルール(例:年齢は正数でなければならない)が既存データに対して成り立っていることを検証する。
- インデックス:新しいインデックスが既存のものと競合しないこと、または書き込み遅延が著しく増加しないことを確認する。
例えば、列をINTからVARCHAR安全に思えるかもしれないが、アプリケーションが数値演算を期待している場合、エラーが発生する。ERモデルは論理的な型を反映すべきだが、物理的な実装はそれに一致しなければならない。
避けたい一般的な落とし穴 ⚠️
経験豊富なチームですらミスを犯す。一般的な落とし穴を認識することで、より強靭な検証プロセスの構築が可能になる。
- デッドロックを無視する: 長時間実行されるマイグレーションはテーブルをロックする可能性があり、アプリケーションのタイムアウトを引き起こす。ロック時間の検証を行う。
- ダウンタイムゼロを前提とする: 一部の変更は本質的にダウンタイムを必要とする。最善を期すのではなく、明確に計画するべきである。
- ロールバック計画をスキップする: 検証が通ったが本番環境で失敗した場合、ロールバックスクリプトは必須である。マイグレーションと同様に、ロールバックも徹底的にテストする。
- ソフトデリートを無視する: ソフト削除されたレコードのロジックを変更すると、注意深く対処しないとデータ損失につながる。
ワークフローの自動化 ⚙️
マニュアルでの検証は徹底的だが、スケーラビリティに欠ける。自動化ツールはERモデルを解析し、マイグレーションスクリプトを生成できる。また、デプロイ前に一般的なエラーを検出するLintチェックも実行できる。
自動化の利点には以下が含まれる:
- 一貫性: すべての変更が同じルールに従う。
- スピード: スクリプトはマニュアルレビューよりも高速に実行される。
- ドキュメント化: 生成されたレポートは、コンプライアンス監査における検証の証拠となる。
- 統合: 自動化されたチェックはCI/CDパイプラインの一部となり、検証に失敗した場合にデプロイをブロックできる。
しかし、自動化は人間の判断を置き換えてはならない。複雑なビジネスロジックは、データの文脈を理解するシニアエンジニアによるレビューを必要とする場合が多い。
スキーマ管理に関する最終的な考察 🌱
スキーマの進化は、注意を要する継続的なプロセスである。データベーススキーマをコードとして扱うことは、信頼性への第一歩である。ERモデルを用いて変更を検証することで、チームは高い可用性とデータの正確性を維持できる。
目標は単に変更を行うことではなく、安全に変更を行うことである。適切に検証されたスキーマは、要件が進化してもアプリケーションが安定したまま保たれることを保証する。この規律は、開発チームとインフラストラクチャの間の信頼を築く。 🏗️
設計フェーズに時間を投資する。明確な図を描く。すべての制約を文書化する。すべてのマイグレーションをテストする。これらの実践は健全なデータエコシステムの基盤を形成する。データベースが安定しているとき、アプリケーションは繁栄できる。
スキーマ検証は一度きりの出来事ではない。それは文化である。システムが成長するにつれて、検証プロセスもそれに応じて成長しなければならない。ERモデルの定期的なレビューにより、アーキテクチャがビジネス目標と一致したまま保たれる。この前向きなアプローチにより、技術的負債が時間とともに蓄積されるのを防ぐことができる。