











堅牢なデータベース構造を設計するには正確さと先見性が求められます。エンティティ関係図(ERD)は、このアーキテクチャの基盤となる設計図です。明確な地図がなければ、データの重複やクエリのボトルネックが急速に発生し、時間とともにパフォーマンスが低下します。このガイドでは、これらの視覚的モデルから直接最適化技術を導出する方法を検討します。特定のプラットフォーム機能や独自のツールに依存せずに、構造的整合性とパフォーマンスチューニングに焦点を当てます。基礎となる関係を理解することで、効率的にスケーラブルなシステムを構築できます。
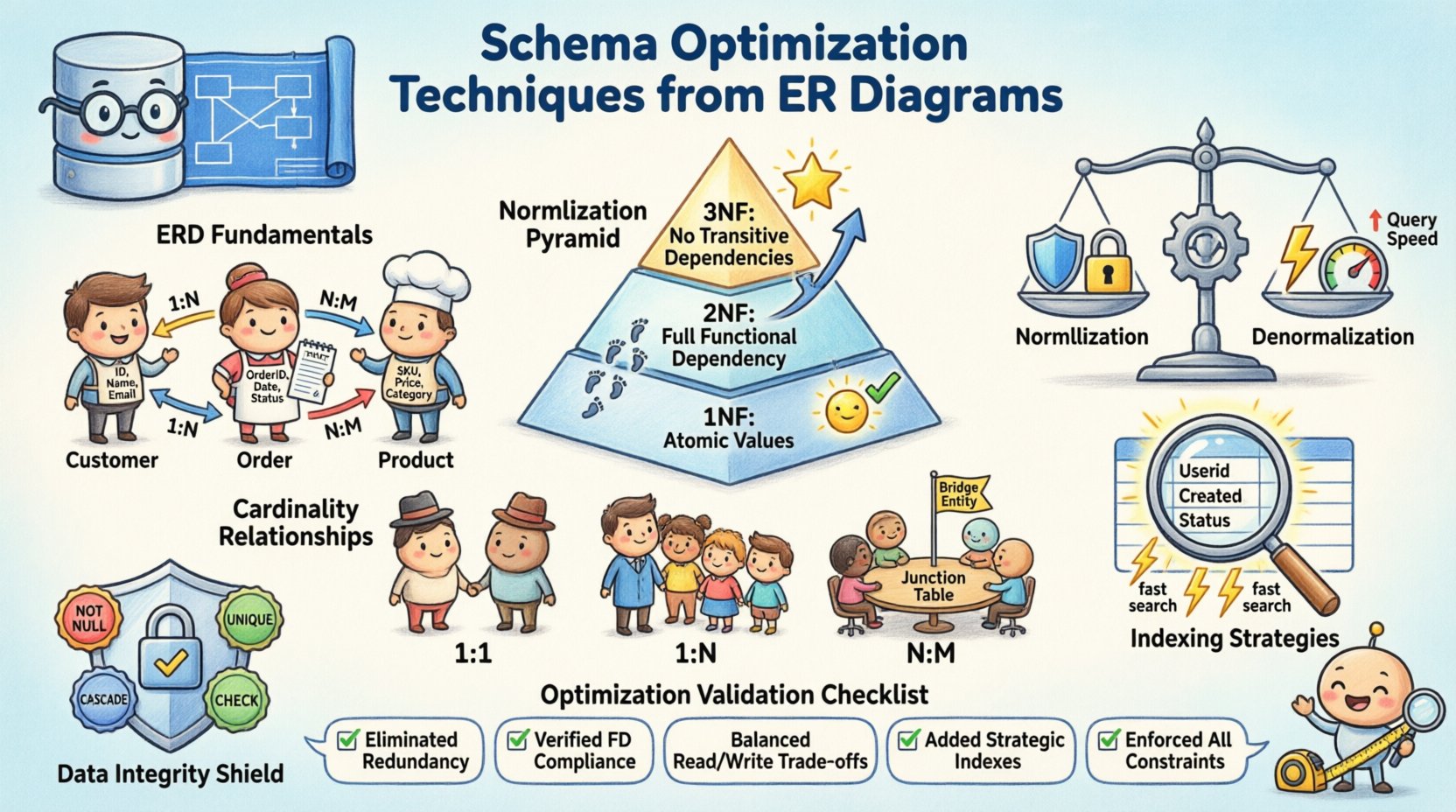
📐 ER図の基礎を理解する
最適化を始める前に、核心となる要素が明確でなければなりません。ER図はビジネス要件を論理的なデータモデルに変換します。情報の保存方法とアクセス方法を定義します。強固な基盤があれば、開発ライフサイクルの後半で構造的負債が発生するのを防げます。以下の要素を検討してください:
- エンティティ:顧客、注文、製品など、オブジェクトや概念を表します。各エンティティは物理スキーマ内のテーブルになります。
- 属性:エンティティの性質、たとえば名前、ID、タイムスタンプなどを定義します。これらはテーブル内の列になります。
- 関係:エンティティどうしがどのように相互作用するかを示します。これにより外部キーと制約の使用が決まります。
これらの要素を視覚化することで、1行のコードを書く前から潜在的な問題を特定できます。論理的な流れが物理的なストレージ要件と一致していることを保証します。この整合性は、複雑なアプリケーションにおいてデータの一貫性を維持するために不可欠です。
🔨 データ整合性のための正規化戦略
正規化とは、データの重複を減らし、整合性を高めるためにデータを整理するプロセスです。大きなテーブルをより小さな論理単位に分割します。過剰な正規化は読み取りを遅くする一方で、完全に正規化を省略すると更新異常が発生します。目的は、特定のワークロードに適したバランスを見つけることです。
第一正規形(1NF)
第一のルールは、各列が原子的な値を含むことを要求します。1つのセル内に繰り返しグループや配列は許されません。これにより、すべてのデータが明確でクエリ可能であることが保証されます。たとえば、電話番号のリストは、コンマ区切りの文字列として保存するのではなく、別々の行または関連テーブルに分割する必要があります。
第二正規形(2NF)
1NFを満たした後、2NFは部分的依存を扱います。すべての非キー属性は、完全な主キーに依存しなければなりません。複合キーの場合、キーの一部だけが属性を決定するようなデータの重複を防ぎます。このステップにより、構造が洗練され、すべての情報が親に正しく関連付けられていることを保証します。
第三正規形(3NF)
第三の形では、推移的依存を排除します。非キー属性は、他の非キー属性に依存してはいけません。つまり、属性Aが属性Bに依存し、属性Bがキーに依存する場合、属性Aは同じテーブルに存在してはいけません。このようなデータを別テーブルに移動することで、保守性が向上し、ストレージの無駄が削減されます。
以下の表は、正規化の進展を要約しています:
| 正規形 | 主な目的 | キー制約 |
|---|---|---|
| 1NF | 原子的値 | 繰り返しグループなし |
| 2NF | 完全依存 | 部分的依存の除去 |
| 3NF | 独立性 | 推移的依存関係を削除する |
⚡ パフォーマンス向上のための非正規化
正規化は整合性を保証するが、クエリ実行時に複雑な結合を頻繁に必要とする。読み込みが重いシステムでは、複数のテーブルを結合するオーバーヘッドがボトルネックになることがある。非正規化は意図的に冗長性を導入することで、データの取得速度を向上させる。これは、ストレージ効率とクエリパフォーマンスのトレードオフである。
以下の状況では、非正規化が適切であることを検討する:
- レポートダッシュボード:集計データは事前に計算して保存することで、リアルタイム計算を回避できる。
- キャッシュレイヤー:頻繁にアクセスされるデータは、読み込み最適化されたストアに複製できる。
- 高スループット取引:結合の深さを減らすことで、ロック競合とCPU使用率を最小限に抑える。
この実装を行う際は、冗長データの更新に明確なプロセスを設ける必要がある。本質的なデータが変更されたにもかかわらずコピーが更新されない場合、不整合が生じる。正確性を維持するためには、自動トリガーまたはアプリケーションロジックで同期を処理しなければならない。
🔗 カーディナリティと関係の管理
カーディナリティはエンティティ間の数的関係を定義する。外部キーの実装方法やデータのリンク方法を決定する。これらのパターンを理解することは、孤立レコードの防止と参照整合性の確保に不可欠である。
- 1対1:一般的なシステムでは稀であるが、セキュリティや拡張テーブルに使用されることが多い。Table Aの1行が、Table Bの正確に1行にリンクする。
- 1対多:最も一般的な関係。1つの親レコードが複数の子レコードに関連する。外部キーは子テーブルに存在する。
- 多対多:関係を解消するために中間テーブル(ジョイントテーブル)が必要となる。この中間テーブルが両エンティティの主キーをリンクする。
誤ったカーディナリティの仮定は、非効率なストレージや無効なデータ状態を引き起こす。たとえば、多対多関係を単純なカラムとして扱うと、複数の関連付けが不可能になる。これらのリンクを適切にモデル化することで、データベースが図に定義されたビジネスルールを強制できるようになる。
📉 構造解析に基づくインデックス戦略
インデックスは、データベースエンジンがデータを迅速に検索できるようにする仕組みである。ERDの構造が、どのカラムをインデックス化すべきかを直接示す。無謀にインデックスを追加するとディスク容量を消費し、書き込み操作の速度を低下させる。
インデックス設計における重要な考慮事項には以下が含まれる:
- 主キー:デフォルトで常にインデックス化される。各行の固有の識別子を定義する。
- 外部キー:結合操作や制約チェックの高速化のために、頻繁にインデックス化が必要となる。
- 複合キー:複数のカラムでフィルタリングを行うクエリで使用される。インデックス内のカラムの順序はパフォーマンスに影響する。
- 選択的なカラム:高基数のカラムにインデックスを設定する。低選択性(例:性別)のカラムはインデックスを設けることでほとんど利益を得られない。
スキーマ設計に対してクエリパターンを分析する。特定の結合が頻繁に実行される場合は、外部キーのカラムにインデックスを設定することを確認する。これにより、データベースがテーブル全体をスキャンする時間の短縮が可能になる。
🛡️ データ整合性と参照制約
整合性制約はデータの正確性と一貫性を保護する。無効な入力や誤った削除から守るガードレールの役割を果たす。一部の制約はアプリケーションで強制されるが、データベースレベルの制約の方が信頼性が高い。
一般的な制約タイプには以下が含まれる:
- NOT NULL:カラムが常に値を含むことを保証する。重要なデータフィールドに空白が生じるのを防ぐ。
- UNIQUE:特定のカラムで、2行以上が同じ値を共有しないことを保証する。メールアドレスやユーザー名などに有用。
- CASCADE:親レコードが削除されたときに子レコードに何が起こるかを定義する。選択肢には制限(restrict)、連鎖削除(cascade)、NULL設定(set null)がある。
- CHECK:日付範囲や数値制限など、データ値に特定の条件を強制する。
これらのルールをデータベースレベルで実装することで、アプリケーションが個々のデータポイントを検証する必要がなくなる。データの有効性に関するロジックを集中管理し、コードの重複と潜在的なエラーを削減できる。
🔄 反復的改善とスキーマの進化
スキーマ設計は一度きりの作業ではない。ビジネス要件は変化し、データモデルも進化しなければならない。ERDと物理スキーマの定期的なレビューにより、改善すべき領域を特定できる。クエリのパフォーマンスを監視することで、構造が苦戦している箇所を把握できる。
改善の過程で以下のステップを検討する:
- インデックスの使用状況を確認する:使用されていないインデックスを削除して、書き込みのオーバーヘッドを削減する。
- パーティショニングを確認する:大規模なテーブルは、範囲やキーに基づいてデータを分割することで恩恵を受ける可能性がある。
- 基数の更新:ビジネスロジックが変化すると、関係性が1対多から多対多に変化する可能性がある。
- バージョン管理:スキーマの変更をコードとして扱う。必要に応じてロールバックできるように変更履歴を追跡する。
この反復的なアプローチにより、データベースが時間の経過とともにアプリケーションのニーズと整合した状態を維持できる。将来の開発を遅らせる技術的負債の蓄積を防ぐ。
✅ 最適化チェックリスト
デプロイ前にスキーマ設計を検証するために、このリストを使用する:
- すべてのテーブルが最低でも第三正規形(3NF)を満たしていることを確認する。
- 結合が頻繁に行われる場所では、外部キーがインデックス化されていることを確認する。
- 関係性に循環依存がないか確認する。
- すべてのテーブルに主キーが定義されていることを確認する。
- データの一貫性ルールが適用されていることを確認するために、制約を確認する。
- クエリパターンを分析して、正規化されていない状態になる可能性のある機会を特定する。
- データの基数と量に関するすべての仮定を文書化する。
これらの手順を踏むことで、データ保存の堅牢な基盤が構築される。システムが完全な再構築なしに成長に対応できる。適切に最適化されたスキーマは、遅いアプリケーションと反応の良いアプリケーションの違いを生み出す。