











リレーショナルデータベースは、テーブルと行の構造に基づいており、これはフラットデータ向けに設計されたものです。しかし、現実世界はそう単純に従わないことがほとんどです。組織、ファイルシステム、コメントスレッド、カテゴリツリーはすべて、階層構造に存在しています。これらの親子関係を標準のエンティティ関係図(ERD)で表現するには、データ整合性を保ちつつ効率的な取得を可能にする特定の設計パターンが必要です。
ツリー構造をフラットスキーマにマッピングしようとすると、正規化とパフォーマンスの間で古典的なジレンマに直面します。このガイドでは、階層データをモデリングするための主要な技術を検討し、各アプローチのトレードオフを評価することで、堅牢なシステム設計を支援します。
🧩 フラットスキーマの課題
エンティティ関係図は通常、エンティティをボックスで、関係を線で可視化します。標準的な関係では、1つのテーブルが外部キーを通じて別のテーブルにリンクします。これは、方向が固定された多対多または1対多のシナリオでは完璧に機能します。しかし、カテゴリがサブカテゴリを持ち、そのサブカテゴリがさらにサブサブカテゴリを持ち得る(無限にまで)場合、どうなるでしょうか?
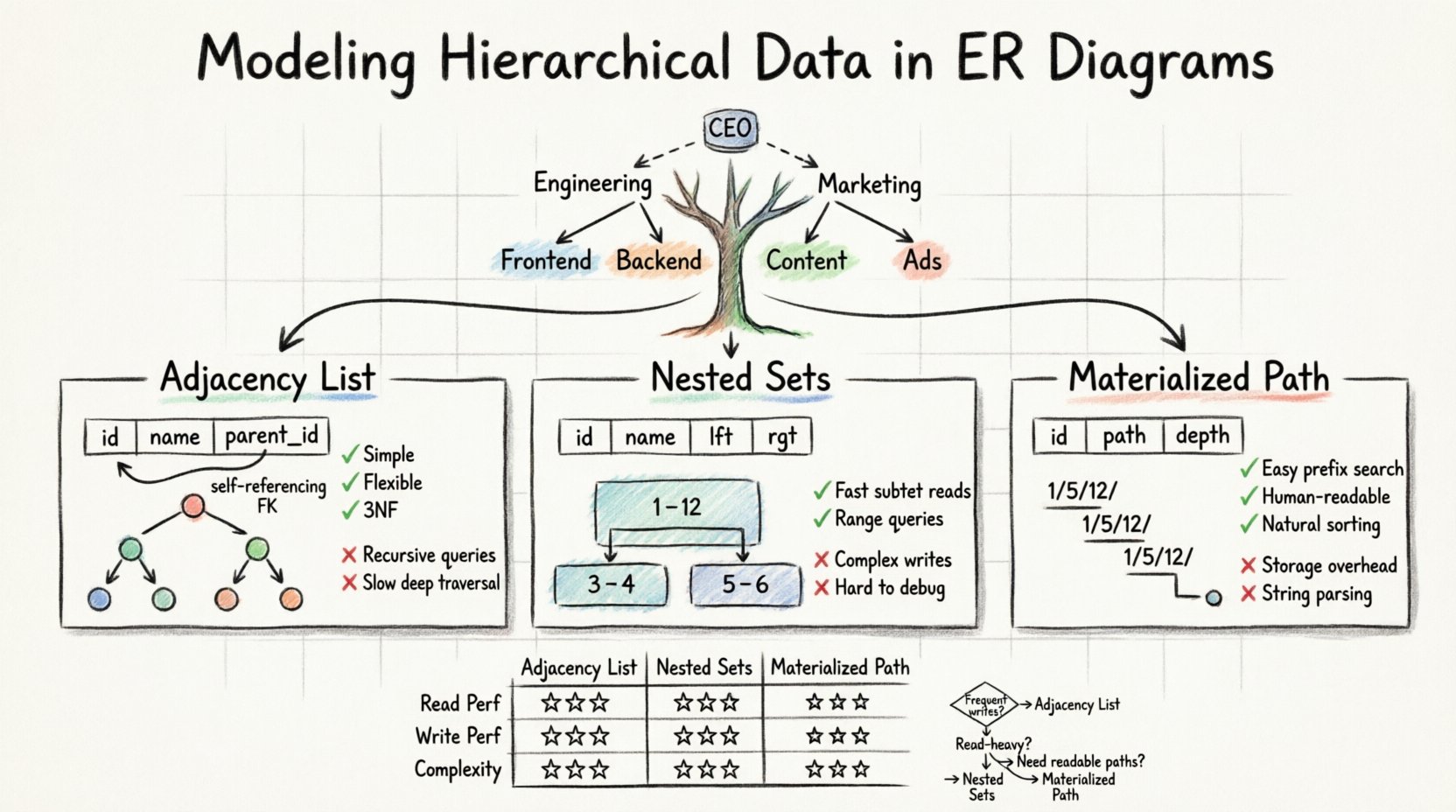
標準的なリレーショナルモデルは可変の深さに対応するのが困難です。フラットテーブルでは、任意の長さのパスを簡単に格納できません。これを解決するには、階層を明示的に格納するようにスキーマを調整する必要があります。データアーキテクトがこれを達成するために使用する主なパターンは3つあります:
- 隣接リスト: 子レコード内に親のIDを格納する。
- ネストセット: 範囲を定義するために左値と右値を割り当てる。
- パス列挙: ルートから現在のノードまでの完全なパスを格納する。
🔗 隣接リストモデル
隣接リストは、標準のERDで階層を表現する最も一般的で直感的な方法です。これは自己参照関係に依存しています。つまり、1つのテーブルに自身の主キーを参照するカラムが含まれます。
📐 スキーマ構造
このモデルでは、データを保持する1つのテーブルを作成します。各行はツリー内のノードを表します。重要な追加項目は、通常parent_idまたはancestor_idという名前のカラムで、親ノードの固有識別子を保持します。ノードが階層の最上位にある場合は、このカラムにはnull値が入ります。
以下のようなテーブルを考えてみましょう:部門:
- id: 部門の固有の主キー。
- name: 部門の表示名。
- parent_id: 上位部門のID(トップレベルではnull可)
✅ 優位点
- シンプルさ: スキーマは直感的で、開発者やデータベース管理者にとって理解しやすい。
- 柔軟性:部分木の移動は簡単です。ルートノードの
parent_idを更新すればよい。 - 正規化: データの重複がないため、第三正規形(3NF)を適切に遵守している。
❌ 劣位点
- クエリの複雑さ: すべての子孫を取得するには再帰クエリまたはアプリケーション側の処理が必要となる。
- パフォーマンス: 特定のインデックス戦略や再帰的共通テーブル式(CTE)がなければ、深い走査は遅くなる可能性がある。
- 参照整合性: 外部キーは役立つが、制約が厳密に適用されない場合、循環参照が発生する可能性がある。
🌲 ネストセットモデル
ネストセットモデルは木構造を区間の集合に変換する。親ポインタを追跡する代わりに、各ノードには2つの数値が割り当てられる。left および right。これらの値は、木の前順走査におけるノードの位置を表す。
📐 スキーマ構造
ルートノードが全体の集合である木を想像してほしい。木を走査する際、カウンタを1ずつ増加させる。ノードに入ると、現在のカウントをleftとして記録する。そのノードとすべての子ノードの処理が終了した時点で、カウントをrightとして記録する。right 値は常にそれより大きい左 値。
A カテゴリ テーブルは次のようになります:
- id: 一意の識別子。
- 名前: カテゴリ名。
- lft: 左境界値。
- rgt: 右境界値。
✅ 優位点
- 高速取得: サブツリーを取得するには、単純な範囲クエリを使用して
BETWEEN論理を使用する。 - 効率性: 隣接リストと比較して、大規模で深い木構造において読み取り性能が優れている。
❌ 劣位点
- 書き込みコスト: ノードの挿入や移動は高コストである。他の多くのノードの
lftおよびrgt値を更新しなければならない。区間の整合性を維持するためである。 - 複雑性: 専用のライブラリサポートがなければ、論理の実装やデバッグが困難である。
🛣️ パス列挙とマテリアライズドパス
パス列挙法は、ノードの祖先関係を文字列または区切りリストとして保存する。このアプローチはしばしばマテリアライズドパスパターンと呼ばれる。これは隣接リストのシンプルさとパスの可読性を組み合わせたものである。
📐 スキーマ構造
このモデルでは、各レコードがルートからの完全なパスを保存する。例えば、ファイルシステムモデルでは、ファイルが以下のようなパス文字列を持つことがある。/home/user/documents/report.txt。データベースでは、この情報はしばしばカラム内の区切り文字列として保存される。たとえば、1/5/12/.
テーブルには以下の項目が含まれる:
- id: 主キー。
- path: 祖先関係を表す文字列。
- depth: ノードの深さ(何段階下にあるか)を示す整数。
✅ 優位点
- 簡単な走査: パスの接頭辞と一致させることで、すべての子孫を検索できる。
- 可読性: データは人間が読みやすく、デバッグも容易である。
- 並べ替え: パス文字列に基づいて並べ替えると、自然に正しい木構造の順序が得られることが多い。
❌ 劣位点
- ストレージオーバーヘッド: 長いパスは、大きなストレージ容量を消費する可能性がある。
- 文字列解析: クエリはしばしば文字列操作関数を必要とし、整数比較よりも遅くなることがある。
📊 比較分析
適切なモデルを選ぶには、読み込み対書き込みの比率と階層の深さに大きく依存する。以下の表は各手法の特徴を概説している。
| 特徴 | 隣接リスト | ネストセット | マテリアライズドパス |
|---|---|---|---|
| 読み取りパフォーマンス | 低~中程度 | 高 | 中~高 |
| 書き込みパフォーマンス | 高 | 低 | 中 |
| 実装の複雑さ | 低 | 高 | 中 |
| 深い木構造をサポート | はい | はい | はい(制限付き) |
| クエリ論理 | 再帰的 | 範囲スキャン | プレフィックスマッチ |
⚙️ パフォーマンスに関する考慮事項
階層構造をモデル化する際には、データベースエンジンがデータをどのように扱うかを検討する必要があります。選択したモデルに関わらず、インデックス戦略は重要な役割を果たします。
- 隣接リスト: インデックスを
parent_id列を重点的にインデックス化してください。これにより、データベースは全テーブルをスキャンせずに特定のノードのすべての子を迅速に検索できます。 - ネストセット: 両方ともインデックスを貼る
lftとrgt. コンポジットインデックスは範囲クエリを大幅に最適化できます。 - マテリアライズドパス: インデックスを貼る
path列。データベースによっては、サブツリーのフィルタリングにプレフィックスインデックスが効果的である場合があります。
🛠️ メンテナンスと更新
データモデルは静的ではありません。組織が成長するにつれて、階層構造も変化します。ノードを1つの枝から別の枝に移動することは一般的な操作であり、各モデルに異なる影響を与えます。
🔄 ノードの移動
において、隣接リスト、ノードの移動は単一の更新ステートメントで行えます。ルートノードの parent_id を変更します。ただし、循環参照が作られないように確認する必要があります。
において、ネストセットモデルでは、ノードの移動は複雑です。移動先のサブツリー内のすべてのノードについて、lft と rgt の値を再計算して、移動ノードのためのスペースを確保する必要があります。これは通常、複数のテーブル更新を伴うトランザクション操作です。
において、マテリアライズドパスモデルでは、移動したノードおよびそのすべての子孫のパス文字列を更新します。これは各子孫のパスを更新する必要があるため、大きなツリーでは重い書き込み操作になることがあります。
🎯 データモデリングのベストプラクティス
ERDが保守可能でパフォーマンスに優れるようにするため、階層構造を実装する際は以下のガイドラインに従ってください。
- 明確な命名規則を使用する: 一般的な名前 such as
col1。使用parent_id,ancestor_id,lft、またはrgt明示的に。 - 制約を強制する: 円参照を防ぐためにデータベースの制約を使用する。ノードは自分自身の祖先になれない。
- 深さを制限する: 技術的には可能だが、極めて深い階層構造(例:10段以上)は設計上の欠陥を示すことが多い。可能な場合は構造を平坦化することを検討する。
- 選択を文書化する: これらのパターンは標準のSQL機能ではないため、スキーマドキュメントにどのパターンを使用しているかを文書化する。
- ハイブリッドアプローチを検討する: 一部のシステムでは、隣接リストとマテリアライズドパスを組み合わせて、読み取りと書き込みのパフォーマンスをバランスさせる。
🧠 適切な戦略の選択
すべてのシナリオに対して唯一の「正しい」答えがあるわけではない。決定はアプリケーションの具体的な要件にかかっている。
- 隣接リストを選択する場合: データの変更が頻繁であり、階層の深さが中程度である。これはほとんどの汎用アプリケーションにとって最も安全なデフォルトである。
- ネストセットを選択する場合: データの移動がほとんどない読み込み中心のアプリケーションであり、大規模な部分木を迅速に取得する必要がある。
- マテリアライズドパスを選択する場合: 人間が読みやすいパス(URLなど)が必要であり、階層の深さが比較的浅い。
これらの構造的なニュアンスを理解することで、スケーラブルなデータベース設計が可能になる。エンティティ関係図に適切なパターンを選択することで、システムのライフサイクルを通じてデータの整合性、アクセス性、効率性を確保できる。