











現代のデータアーキテクチャにおいて、情報がどれだけ速く取得できるかは、アプリケーションの使いやすさを左右することが多い。ハードウェアのアップグレードやキャッシュ戦略も重要な役割を果たすが、パフォーマンスの基盤はデータ構造そのものにある。特に、エンティティ関係モデル(ERMs)の設計が、データベースエンジンがデータを効率的に走査・結合・集計できるかどうかを決定する。最適化されたスキーマは単に情報を整理するだけでなく、クエリオプティマイザがより高速な実行経路を選びやすくする。 📉
このガイドでは、スキーマ設計の技術的メカニズムとクエリパフォーマンスとの直接的な関連性を検討する。正規化レベル、関係の基数、インデックス戦略がクエリ実行計画内でどのように相互作用するかを検証する。これらのダイナミクスを理解することで、整合性や速度を損なうことなくスケーラブルなシステムを構築できるようになる。
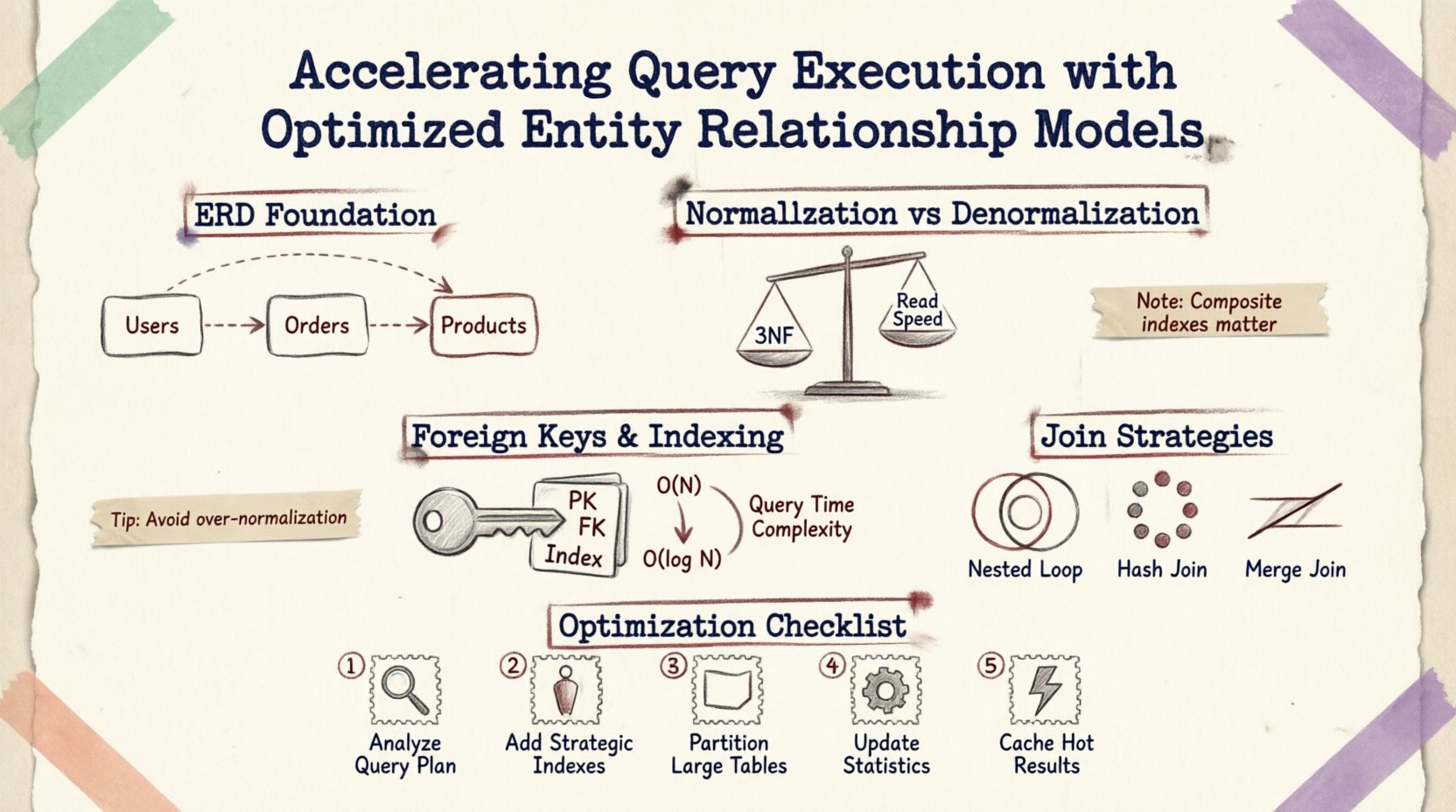
基盤を理解する:ERDとパフォーマンス 🗃️
エンティティ関係図(ERD)は、ドキュメント作成のための視覚的補助以上のものである。それは物理的なストレージとリトリーブのロジックの設計図である。テーブル間を結ぶすべての線は、外部キー制約、結合操作、またはデータ整合性ルールを表している。クエリが送信されると、データベースエンジンはこれらの関係を解釈して実行計画を構築する。
ユーザーの注文と製品詳細を要求するシンプルなクエリを考えてみよう。エンジンは次のようにする必要がある:
- 次のテーブルを検索する:
Usersテーブル。 - 外部キーに従って
Ordersテーブル。 - 次のテーブルを結合する:
OrderItemsテーブル。 - 次のテーブルに到達する:
Products別の関係を通じて
各ステップにはI/O操作とCPUサイクルが伴う。関係が適切に定義されていない場合、エンジンはフルテーブルスキャンやネストされたループ結合に頼る可能性があり、パフォーマンスは指数的に低下する。ERDの最適化により、データがディスクからメモリまで移動する距離が短縮される。
正規化 vs. 非正規化:バランスを見つける ⚖️
正規化とは、データの重複を減らし、整合性を高めるためにデータを整理するプロセスである。一貫性を保つ上で不可欠であるが、過剰な正規化はデータを多数の小さなテーブルに分散させ、読み込みが重い操作では複雑な結合を必要とし、パフォーマンスを低下させる。
深すぎる正規化のコスト
スキーマが第三正規形(3NF)まで正規化されると、データは最も原子的な状態で保存される。これによりストレージ領域を最小限に抑え、更新異常を抑えることができる。しかし、関連データを取得するには複数の外部キーをたどる必要があることが多くなる。
- 結合のオーバーヘッド:結合チェーンに追加されるテーブルごとに、クエリプランの複雑さが増す。
- ロック競合:複数のテーブルにアクセスすると、行レベルのロック競合が発生する可能性が高まる。
- CPU使用率:データベースエンジンは、異なるテーブルからの結果セットをマージしなければならない。
非正規化を行うタイミング
正規化の解除は、読み取りパフォーマンスを最適化するために冗長性を導入します。これは、分析処理や高トラフィックのレポート環境においてしばしば必要です。
- 読み取り中心のワークロード:書き込みが読み取りに比べて頻繁でない場合、正規化されていない列を追加することで、結合操作を節約できます。
- 事前計算された集計: 合計値(例:
total_order_value)をユーザー表に保存することで、毎回のリクエストで合計を計算する必要がなくなります。 - 水平パーティショニング:頻繁にアクセスされるデータを一緒に保持することで、キャッシュの局所性が向上します。
しかし、正規化の解除には、データの不整合を防ぐために注意深い管理が必要です。アプリケーションロジックは、元データが変更された際に冗長なデータも更新されることを保証しなければなりません。
外部キーとインデックス戦略 🔑
外部キー制約は参照整合性を保証しますが、パフォーマンスコストが伴います。データベースは、挿入や更新を許可する前に、あるテーブルの値が別のテーブルに存在することを確認しなければなりません。これらのキーのインデックス化方法を最適化することは非常に重要です。
外部キーのインデックス化
デフォルトでは、主キーは自動的にインデックス化されます。しかし外部キーは、結合操作を高速化するために明示的なインデックスが必要なことがよくあります。外部キー列にインデックスがない場合:
- データベースは、一致する行を見つけるために子テーブル全体をフルスキャンしなければなりません。
- 結合操作は著しく遅くなり、特にテーブルサイズが数百万行に達するにつれて顕著になります。
- 削除時の参照整合性チェックが高コストになります。
適切にインデックス化された外部キーにより、データベースはスキャンではなくインデックスシークを使用でき、計算量をO(N)からO(log N)に削減できます。
関係性に対する複合インデックス
複数の列が関係性を定義する場合、個別のインデックスよりも複合インデックスの方が効果的であることがあります。たとえば、注文テーブル内で user_id および created_at をフィルタリングするクエリがある場合、両方の列に複合インデックスを設けることで、エンジンが関係のないレコードをスキャンすることなくデータを検索できるようになります。
結合戦略と実行計画 🔍
ERDの構造が、クエリオプティマイザが選択する結合アルゴリズムに影響を与えます。これらのメカニズムを理解することで、効率的な結合タイプを優先するスキーマ設計が可能になります。
| 結合タイプ | 最も適している状況 | パフォーマンスへの影響 |
|---|---|---|
| ネストループ結合 | 小さな結果セット、または非常に選択的な述語 | 小規模なデータに対しては高速だが、大規模なスキャンでは遅い |
| ハッシュ結合 | インデックスのない大規模なテーブル | メモリを多く消費するが、ソートされていないデータに適している |
| マージ結合 | 結合キーでのソート済み入力 | データがすでにソートされていれば非常に高速 |
ソートされた入力やインデックス付きの検索をサポートするようにERDを設計することで、最適化エンジンがより高速な結合方法を選択するよう促すことができる。例えば、結合キーをクラスタ化インデックスの一部として定義することで、マージ結合を容易にすることができる。
スキーマ設計における一般的な落とし穴 🚫
経験豊富なアーキテクトですら、クエリの実行速度に影響を与えるミスを犯すことがある。これらのパターンを早期に特定することで、後々の高コストな再設計を防ぐことができる。
- 連鎖する外部キー:テーブルAがBに、BがCに、CがDにリンクする関係の連鎖を作成する。この4つのテーブルを結合するクエリは深くネストされ、遅くなる。
- 可変長文字列:使用する
VARCHAR常に固定長であるキーにVARCHARを使用すると、スペースの無駄になり、行比較が遅くなる。 - 中間テーブルなしの多対多:複数のIDを1つのカラムに格納しようとする(例:カンマ区切りの値)と、適切なインデックス化や正規化が不可能になる。
- 暗黙の型変換:親テーブルと子テーブルの間でデータ型が一致しないように定義すると、エンジンが実行時に値を変換しなければならず、インデックスの使用が妨げられる。
最適化の実践的なステップ 🛠️
システム全体を再設計せずにクエリ実行を改善するためには、以下の構造的なステップに従う。
- クエリパターンの分析:最も頻繁に発生する読み取り操作を確認する。どのテーブルが最も頻繁に結合されているかを特定する。
- インデックスの使用状況の確認:外部キーまたは頻繁にフィルタリングされるカラムにインデックスが欠けているかを確認する。
- 基数の見直し:関係性が正確にモデル化されているかを確認する(1対1 vs. 1対多)。不正確な基数は不要な結合を引き起こす可能性がある。
- 大規模なテーブルのパーティショニング: テーブルの行数が数百万行を超える場合は、クエリごとのスキャン対象データを制限するために、日付または地域でパーティショニングを検討してください。
- ロックの監視: 長時間実行されるロックを保持するクエリを特定するために、モニタリングツールを使用してください。これは、効率の悪いスキーマ走査によって引き起こされることがよくあります。
ストレージとメモリの考慮事項 💾
データの物理的な配置も重要な役割を果たします。データベースエンジンはデータをページ単位で保存します。関連する行が物理的に近くに格納されている場合、データセットを読み込むために必要なディスク読み取り回数が少なくなります。
- クラスタリング:共通のキーでデータを整理することで、範囲検索のパフォーマンスが向上します。
- カラムストア対行ストア:分析系のクエリでは、カラムストアは従来の行ベースのモデルよりも優れた圧縮性能と高速な集計処理を提供する可能性があります。
- キャッシュ:個々の行ではなく、全体の結果セットを効果的にキャッシュできるようにスキーマを設計してください。
スキーマ進化についてのまとめ 🔄
スキーマ設計は一度きりの作業ではありません。アプリケーション要件が変化するにつれて、データモデルも進化しなければなりません。データベース構造を定期的に監査することで、パフォーマンスが一貫して維持されます。エンティティ関係モデルのドキュメントは、コードベースと共に維持され、変更がシステムに与える影響を追跡する必要があります。
データ内の構造的整合性と論理的な関係性に注目することで、高速なクエリ実行を支える基盤が築かれます。目標は静的なシステムを構築することではなく、ユーザーが期待する速度を損なうことなく負荷に適応できる柔軟なアーキテクチャを構築することです。 📊
エンティティ関係モデルの最適化は、データベース理論と実践的なエンジニアリングを融合した技術的分野です。忍耐力、分析力、および下位のエンジンがリクエストを処理する仕組みを明確に理解することが求められます。適切なアプローチを取れば、パフォーマンスの問題は管理可能になり、データの取得がスムーズになります。