











データベースのパフォーマンスは、たいてい、素人には見えない要因に左右される。そのような重要な要因の一つがロック競合である。複数のユーザーまたはプロセスが同時に同じデータにアクセスしようとする場合、システムはデータの整合性を保つためにルールを適用しなければならない。これらのルールがロックを生じる。過度なロックはボトルネックを引き起こし、応答時間が遅くなり、最終ユーザーを不満にさせる。その根本原因は、ハードウェアにあるのではなく、データ構造を定義するエンティティ関係図(ERD)にあることが多い。
適切に設計されたスキーマは、高並行性の基盤となる。データがどのようにアクセスされ、変更されるかを予測することで、アーキテクトは衝突を最小限に抑えるようにテーブルを構造化できる。このアプローチには、トランザクションの分離レベル、インデックス戦略、ロックの物理的メカニズムについての深い理解が必要である。以下のガイドでは、外部ツールに頼らずにデータモデルを最適化し、パフォーマンスを向上させる方法を詳述する。
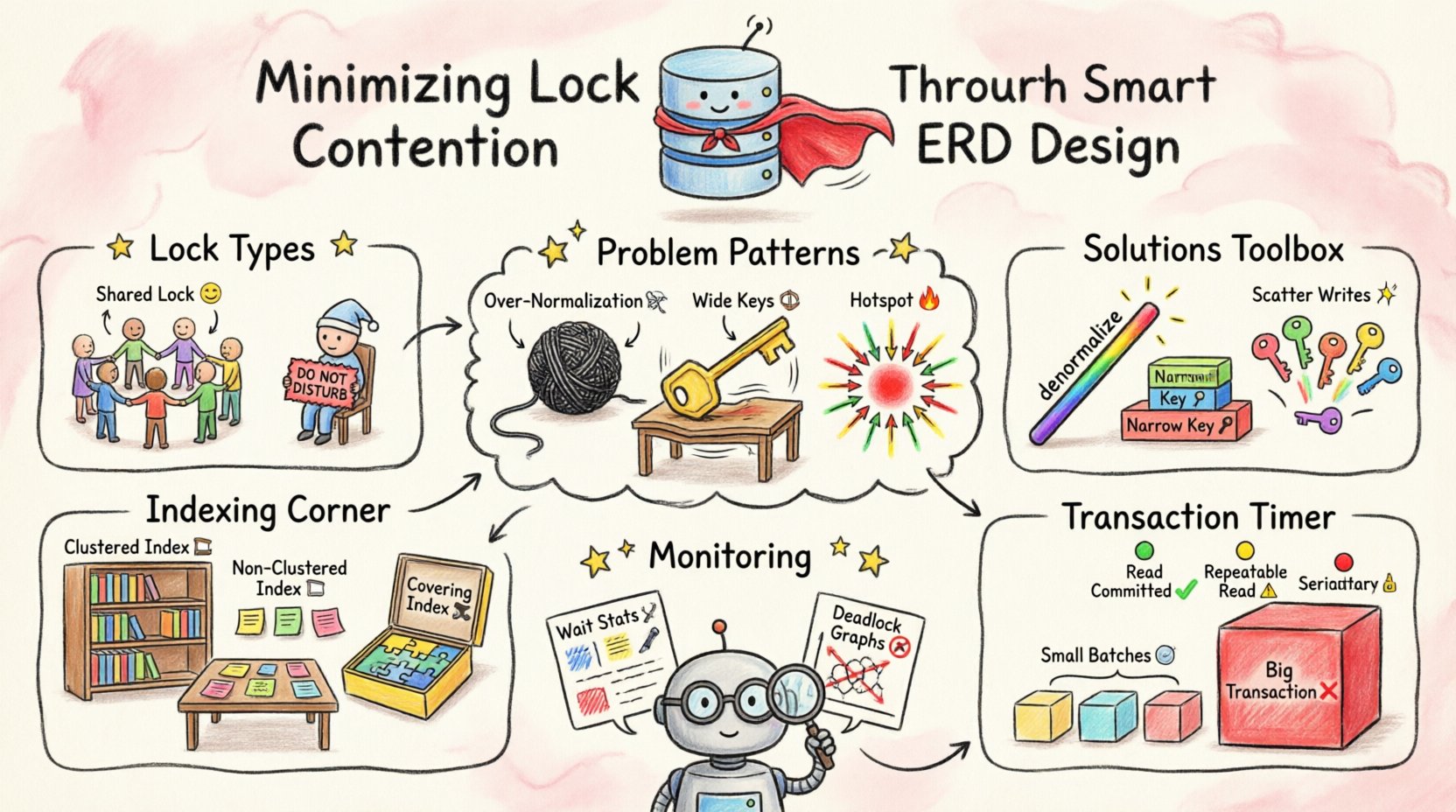
ロックメカニズムの理解 🛡️
設計を最適化する前に、ロックが実際に何をしているかを理解することが不可欠である。データベースは、一貫性の欠如を防ぐためにロックを使用する。もし2つのトランザクションが同じ行を正確に同じ瞬間に更新しようとするならば、衝突が発生する。システムは、どちらが先に進むかを決定しなければならない。
- 共有ロック(S):データの読み取りに使用される。複数のトランザクションが、同じリソースに対して同時に共有ロックを保持できる。
- 排他ロック(X):データの書き込みまたは変更に使用される。リソースに対して、一度に一つのトランザクションしか排他ロックを保持できない。
- 意図ロック:トランザクションが階層の下位レベル(たとえばテーブルやページ)にロックを設定しようとしていることを示す。
排他ロックの需要が共有アクセスの能力を上回ると、ロック競合が発生する。もしERDがデータを検索するためにデータベースにテーブルの大規模なスキャンを強いるならば、保持されるロックの範囲が広がる。これにより、並行処理間の衝突の可能性が高まる。
競合を引き起こすスキーマパターン 📉
特定の設計選択は、ロックの対象範囲を本質的に広げる。これらのパターンを認識することで、開発ライフサイクルの初期段階でリファクタリングが可能になる。
1. 過剰な正規化
正規化は冗長性を減らすが、過剰な正規化はパフォーマンスを損なう可能性がある。単一のレコードを取得するために多数のテーブルを結合するには、複数のテーブルにまたがる複数の行をロックする必要がある。トランザクションが5つの正規化されたテーブルからデータを読み取る必要がある場合、すべてのテーブルに対してロックを取得する。
- リスク:他のトランザクションがそのテーブルのいずれかを変更すると、最初のトランザクションは待機する可能性がある。
- 解決策:頻繁に結合される列を非正規化することを検討する。結合の数を減らすことで、1クエリあたりに必要なロックの数も減る。
2. 広い主キー
主キーは、行を一意に識別するために使用される。主キーが複数の列にまたがる複合キーである場合、インデックスの構築方法に影響を与える。広いキーはインデックスのサイズを増加させる。
- リスク:大きなインデックスは、検索時に読み込み・ロックが必要なページ数が増えることを意味する。主キーの更新は、関連テーブルに連鎖的な変更を引き起こす可能性がある。
- 解決策:可能な限り、シンプルで狭いサロゲートキー(整数など)を使用する。複合キーは論理的に必要不可欠な場合に限り、最小限に抑える。
3. シーケンシャルキーにおけるホットスポット
主キーに自動増分整数を使用することは一般的である。しかし、アプリケーションがデータを順次挿入する場合、すべての新しい書き込みがインデックスの末尾をターゲットにする。これにより、多くのトランザクションが同じリーフページを競合する「ホットスポット」が発生する。
- リスク:データベースエンジンは、すべての新しい挿入に対してインデックスの最後のページをロックしなければならない。
- 解決策:高書き込みシナリオでは、ランダム化されたキーまたはハッシュベースの分散を使用して、負荷を異なるページに分散させる。
スキーマ最適化の戦略 🛠️
ERDの最適化は、カラム、関係、制約に関する特定の選択をすることを含む。以下の表は、一般的な設計決定とそのロック動作への影響を概説している。
| 設計の決定 | ロックへの影響 | 推奨されるアプローチ |
|---|---|---|
| 外部キー制約 | 親テーブルに連鎖的なロックを引き起こす可能性がある。 | 高書き込みシステムでは、遅延制約またはアプリケーションレベルの検証を使用する。 |
| 大容量のBLOB/テキストカラム | 行サイズを増加させ、各行あたりのページ数を増やす必要がある。 | 大容量データを別途保存することで、メインテーブルを狭く保つ。 |
| 高基数カラム | 非効率なインデックス使用につながる可能性がある。 | テーブルスキャンを避けるために、選択的なカラムはインデックス化することを確認する。 |
| デフォルト値 | デフォルト値が適用された場合、不要な行の更新が発生する可能性がある。 | 適切な場所ではNULLを許可することで、書き込みトリガーを回避する。 |
書き込みモデルと読み込みモデルの分離
書き込みに使用するスキーマと読み込みに使用するスキーマを分離することで、競合を大幅に削減できる。書き込みモデルは整合性と正規化に注力する。読み込みモデルは速度と非正規化に注力する。
- トランザクション処理のために、データを高度に正規化された構造に保存する。
- レポートや表示用に、読み込み最適化された構造にデータをレプリケートする。
- これにより、重い読み込みクエリが書き込み操作をブロックすることを確実に回避できる。
インデックス化とキー選択 📊
インデックスはパフォーマンスにとって不可欠だが、無料ではない。すべてのインデックスは更新時に維持されなければならない。テーブルにインデックスが多すぎると、すべての挿入や更新で複数のインデックス構造をロックする必要がある。
クラスタ化インデックス vs. 非クラスタ化インデックス
- クラスタ化インデックス:データの物理的順序を決定する。通常、1テーブルあたり1つだけである。データの保存方法に影響するため、慎重に選択する必要がある。
- 非クラスタ化インデックス: データを指す別の構造。メインテーブルにアクセスせずにクエリをカバーするのに役立つ。
頻繁に更新される列にインデックスを作成しないようにする。列の値が変更されると、インデックスを再構築する必要がある。このプロセスは、インデックス構造に書き込みロックを発生させる。
カバーインデックス
カバーインデックスは、クエリに必要なすべての列を含む。これにより、データベースは実際のテーブルデータを参照せずにリクエストを満たすことができる。エンジンがベーステーブルの行をロックする必要がなくなるため、保持されるロックの範囲が小さくなる。
- 頻繁に読み込まれるクエリを特定する。
- 以下の列を含むインデックスを作成する:
SELECT列。 - これらのインデックスが使用されていることを確認するために、クエリ実行計画を監視する。
トランザクションのスコープと分離度 ⏱️
ERDはトランザクションの振る舞いに影響を与える。長時間実行されるトランザクションは、ロックを長期間保持する。適切に構造化されたスキーマは、トランザクションを短く保つのに役立つ。
バッチ処理
1つのトランザクションで数千行を処理するのではなく、作業を小さなバッチに分割する。これによりロックが早期に解放され、他のプロセスが進行できる。
- コミットごとの変更行数を制限する。
- カーソルまたはループを使用して、データをチャンク単位で処理する。
- 複数回のコミットによるオーバーヘッドと、ロック時間の短縮という利点のバランスを取る。
分離度
データベースシステムは異なる分離度を提供する。高い分離度(例:可視化)はより多くの異常を防ぐが、ロックを増加させる。低い分離度(例:読みコミット済み)はより多くの並行処理を許可する。
- 財務的正確性のために厳密に必要でない限り、可視化を避ける。
- ほとんどの運用タスクには、読みコミット済みまたは再実行可能読み取りを使用する。
- 分離度を、データの一貫性に関するビジネス要件に合わせる。
監視と反復 🔄
設計は一度きりの活動ではない。使用パターンが変化すると、ロック競合の問題も変化する。パフォーマンスを維持するには継続的な監視が必要である。
- 待機統計: トランザクションがロックを待つ時間の長さを追跡する。
- デッドロックグラフ: デッドロックを引き起こしたクエリを示す図を分析する。
- クエリパフォーマンス: 予想よりも長くロックを保持している可能性のある遅いクエリを特定する。
現在のパフォーマンスメトリクスと照らし合わせて、ERDを定期的に見直す。特定のテーブルが継続的に高い待機時間を示している場合、データをパーティション分割するか、スキーマを調整して負荷を軽減することを検討する。
データアーキテクチャについてのまとめ 🧩
ロック競合を最小限に抑えることは、データの整合性とシステムのスループットのバランスです。並行処理を考慮してスキーマを設計することで、データベースエンジンが競合を解決する必要を減らすことができます。これにより応答時間が速くなり、システムの安定性も向上します。
まず現在の関係性やキーを精査しましょう。結合を簡素化し、インデックスの肥大化を減らす機会を探ります。変更内容がロック動作に与える影響を確認するためにステージング環境でテストを行います。慎重な計画と細部への注意を払いながら、効果的にスケーラブルな堅牢なデータレイヤーを構築できます。