











データベーススキーマを設計することは、スピードと構造の二択であることはめったにありません。それは妥協の試みです。アーキテクトがエンティティ関係図(ERD)を構築する際、厳格なデータ整合性と大量のトラフィックを処理するアプリケーションに求められる原始的なスピードの間で、しばしば緊張を感じます。正規化は冗長性を最小限に抑え、データの一貫性を保証します。しかし、その一貫性を維持するコストは、しばしば読み取りパフォーマンスの低下として現れます。
この記事では、このバランスの技術的なニュアンスを探ります。正規化が結合に与える影響、読み取り負荷の高いワークロードがスキーマ変更をどう規定するか、そして良好に構造化されたデータベースとパフォーマンスの高いデータベースの間の境界がどこにあるかを検討します。
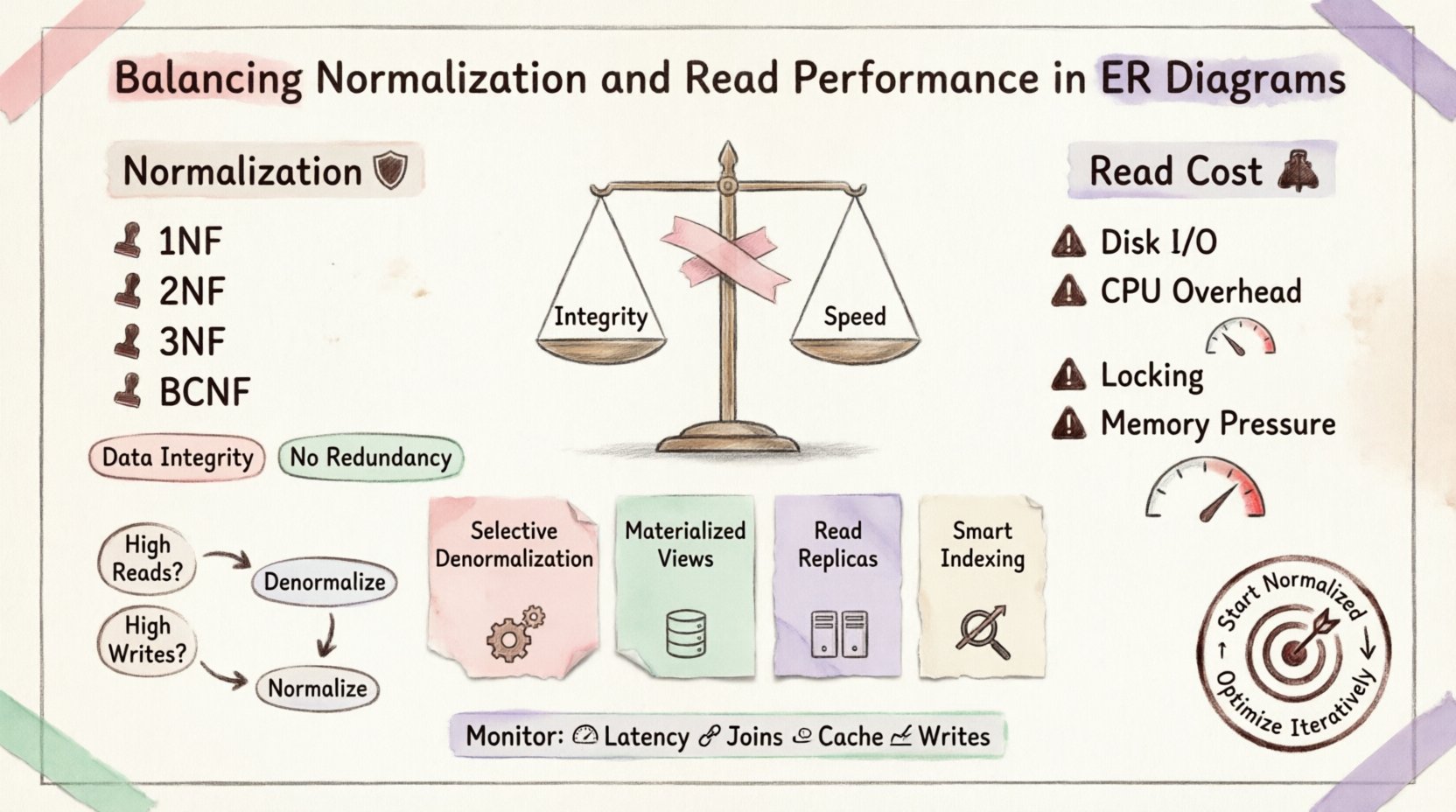
正規化の理解:基礎となる柱 🛡️
正規化とは、冗長性を減らし、データの整合性を高めるためにデータを整理するプロセスです。大きなテーブルをより小さな論理的なテーブルに分割し、それらの間の関係を定義します。その目的は、挿入、更新、削除の際に発生する異常を排除することです。
主要な正規形
-
第一正規形(1NF):原子性を保証します。各列には1つの値のみが含まれます。繰り返しグループは存在しません。
-
第二正規形(2NF):1NFを基盤としています。すべての非キー属性は主キーに完全に依存しなければなりません。部分的依存を排除します。
-
第三正規形(3NF):2NFを基盤としています。推移的依存を排除します。非キー属性は、キー、全体のキー、それ以外の何ものにも依存しません。
-
ボーイス・コッド正規形(BCNF):特定の依存異常を処理するための、3NFよりも厳格なバージョンです。
これらの正規形に従うことでクリーンなデータベースが保証されますが、クエリの複雑さが増します。ER図で定義されたすべての関係が、結合操作の可能性を持つようになります。
読み取りのコスト 💸
データを正規化すると、情報が複数のテーブルに分散されることがよくあります。完全なレコードを取得するには、データベースエンジンが結合操作を実行しなければなりません。結合は計算コストが高いです。
結合がクエリを遅くする理由
-
ディスクI/O:テーブルが完全にインデックス化されたりキャッシュされなかった場合、エンジンはディスク上の異なる物理的な場所にデータを検索しなければなりません。
-
CPUオーバーヘッド:データベースは、1つのテーブルのキーを別のテーブルのキーと照合しなければなりません。これには大きな処理能力が必要です。
-
ロック競合:複雑な結合はロックを長時間保持する可能性があり、他のトランザクションが関連データにアクセスすることをブロックします。
-
メモリ圧力:大規模な結合操作は、データのソートやハッシュ化に膨大なメモリバッファを必要とします。
読み取り負荷の高い環境、たとえばレポートダッシュボードや公開APIでは、この遅延は許容できません。ユーザーは即時フィードバックを期待しています。正規化されたデータを返すために100ミリ秒かかるクエリが、非正規化された場合、10ミリ秒で済むことがあります。
最適化の戦略 🚀
整合性とスピードのバランスを取るために、アーキテクトは特定のパターンを採用します。これらの戦略により、最も重要な場所ではデータベースを正規化したままにしつつ、読み取りに重要となる場所では最適化が可能になります。
1. 選択的非正規化
すべてのテーブルが完全に正規化される必要はありません。最も頻繁にアクセスされるデータを特定し、重複して保存してください。たとえば、ユーザー名と注文履歴を頻繁に同時に照会する場合、ユーザー名を注文テーブルに直接保存することで、結合を省略できます。
2. 物理ビュー
物理ビューは、クエリの結果をディスク上に物理的に保存します。本質的に事前に計算されたテーブルです。データが変更された場合、ビューを更新する必要があります。リアルタイムの正確性が不要な複雑な集計に最適です。
3. 読み取りレプリカ
読み取りワークロードと書き込みワークロードを分離します。すべての書き込み操作を、正規化されたままのプライマリデータベースに送信します。すべての読み取り操作をレプリカに送信します。これにより、レプリカを異なる方法で最適化でき、たとえばインデックスを増やしたり、正規化されていない構造を使用したりできますが、トランザクションの整合性には影響しません。
4. インデックス戦略
正規化されたデータベースであっても、適切なインデックスがあれば良好なパフォーマンスを発揮できます。カバーインデックスは、データベースがインデックスのみを使ってクエリを満たすことができ、テーブルの検索を回避できるようにします。複合インデックスは、一般的な外部キーでの結合を高速化できます。
デノーマライズするタイミング 📉
デノーマライズは、意図的な決定であり、デフォルトの状態ではありません。仮定ではなく、パフォーマンス監視からの証拠に基づいて行うべきです。
|
シナリオ |
アプローチ |
理由 |
|---|---|---|
|
書き込み頻度が高い |
正規化を維持する |
更新が速くなる。維持すべき重複データが少ない。 |
|
読み取り頻度が高い |
デノーマライズを検討する |
結合を減らす。検索時間が速くなる。 |
|
データの一貫性が重要 |
正規化を維持する |
単一の真実のソースがデータのずれを防ぐ。 |
|
レポート作成と分析 |
デノーマライズする |
集計が複雑なので、事前に計算すると役立つ。 |
|
スケーラビリティの要件 |
ハイブリッドアプローチ |
サービスを分割するか、キャッシュレイヤーを使用する。 |
トレードオフ:データ整合性 vs 速度 ⚙️
重複を導入するたびに、データの整合性のリスクが生じます。ユーザーがメールアドレスを変更したが、メールアドレスが両方の場所に保存されている場合、Users テーブルと通知 テーブルでは、更新が失敗するか見逃される可能性があります。これは更新異常と呼ばれます。
これを緩和するためには、アプリケーションロジックが堅牢でなければならない。トリガーは一貫性を強制できるが、複雑性を増加させる。あるいは、正規化されていないデータが導出され、変更不可となるようにスキーマを設計することで、乖離のリスクを低減できる。
一貫性の管理
-
アプリケーションレベルのロジック:すべての冗長コピーをアトミックに更新するコードを書く。
-
データベーストリガー: データベースがルールを自動的に強制する。これにより、ロジックをデータに近い位置に保つことができる。
-
最終的整合性: データが一時的に古くなる可能性を受け入れる。バックグラウンドジョブを使って冗長データを同期する。
モニタリングとメンテナンス 🔧
静的な設計は、変化する使用パターンを考慮していない。今日効果があることが、来年はボトルネックになる可能性がある。継続的なモニタリングは不可欠である。
追跡すべき重要な指標
-
クエリ遅延:重要な読み取りクエリにかかる時間をモニタリングする。
-
結合回数:複雑なクエリあたりの結合回数を追跡する。
-
キャッシュヒット率: キャッシュを使用している場合、データベース負荷を効果的に軽減しているか確認する。
-
書き込み遅延: 正規化されていない状態が書き込みをあまり遅くしていないか確認する。
結論:文脈に基づいた意思決定 🎯
データベース設計には万能の基準はない。最適なER図とは、あなたの特定のワークロードに合ったものである。正規化は安全を提供し、非正規化は速度を提供する。目標は、均衡点を見つけることである。
データ整合性を確保するために、正規化された設計から始める。パフォーマンスのボトルネックが現れたら、遅延を引き起こしている特定のクエリを特定する。非正規化やキャッシュは、そのような領域にのみ適用する。この反復的なアプローチにより、早期の最適化を避け、システムが長期間にわたり保守可能であることを保証できる。
技術は進化することを忘れないでください。新しいストレージエンジンやクエリ最適化器は、結合のコストを継続的に低下させています。常に現在の能力と照らし合わせてスキーマを見直す。バランスは変化するため、設計もそれに合わせて変化しなければならない。
正規化のメカニズムと読み取りパフォーマンスの現実を理解することで、堅牢かつ応答性の高いシステムを構築できる。コードだけでなく、データに注目する。