











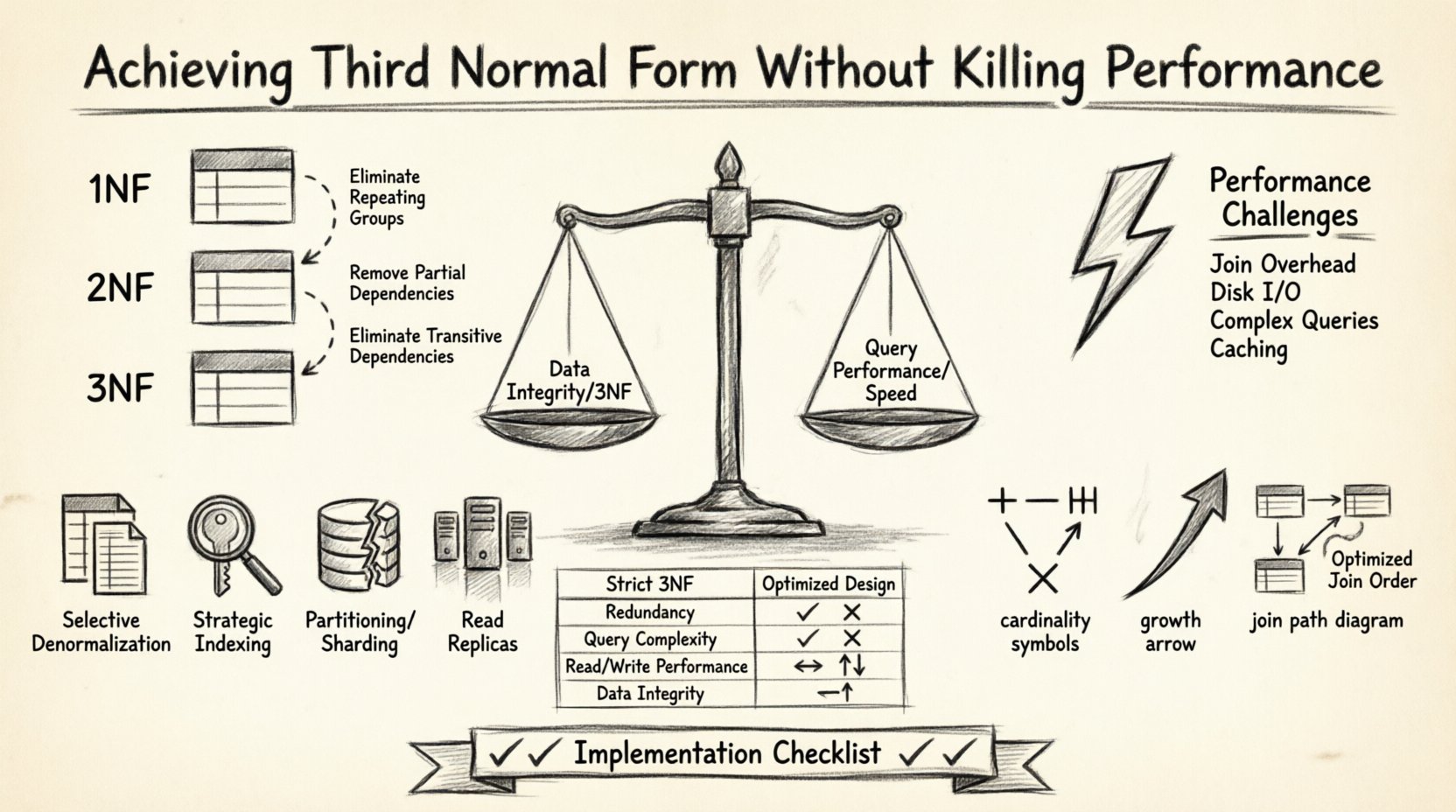
堅牢なデータベース構造を設計することは、バランスの取り合いである。一方では、正規化によってデータの整合性を保ち、冗長性を排除する。他方では、クエリの高速性とシステムの応答性が求められる。多くのデータベースアーキテクトは、厳しい正規化ルールを守ってクエリの遅延を招くか、非正規化を極端に進めてデータの不整合を招くかという難しい選択に直面する。目標は、第三正規形(3NF)に準拠しつつも、高いパフォーマンスを維持できる中間地点を見つけることである。この記事では、データの整合性と速度の両方を損なわずに、この均衡を達成するためのエンティティ関係図(ERD)の構造化方法について探求する。
第三正規形の理解 🧩
第三正規形は、データベースの正規化における特定の段階である。3NFに到達するには、まず第一正規形(1NF)と第二正規形(2NF)を満たしている必要がある。3NFの核心原則は、すべての属性が主キーにのみ依存しなければならないということである。推移的依存関係があってはならない。
- 第一正規形:繰り返しグループを排除し、原子的な値を保証する。
- 第二正規形:複合キーの一部にのみ依存する非キー属性による部分的依存関係を排除する。
- 第三正規形:推移的依存関係を排除する。AがBを決定し、BがCを決定する場合、Cは同じテーブル内でAに直接依存してはならない。
3NFに到達すると、更新異常を最小限に抑えることができる。更新異常とは、データが一つの場所で変更されたが他の場所では変更されていないために生じるエラーであり、結果として整合性の欠如が発生する。例えば、顧客の住所が「注文」テーブルと「顧客」テーブルの両方に保存されている場合、一方のテーブルで住所を変更しても他方で変更しなければ、不整合が生じる。3NFは、その住所を一つの場所にのみ保存することを強制する。注文テーブルと顧客もう一方のテーブルで変更しなければ、不整合が生じる。3NFは、その住所を一つの場所にのみ保存することを強制する。
パフォーマンスのトレードオフ ⚡
3NFはデータの整合性において優れているが、パフォーマンスのコストを伴うことが多い。正規化されたデータベースは通常、より多くのテーブルを必要とする。完全なデータセットを取得するには、データベースエンジンが複数の結合(JOIN)を実行しなければならない。各結合操作では、システムがディスクまたはメモリからデータを読み込み、キーを照合し、結果を統合する必要がある。
顧客名、注文詳細、製品説明、配送先住所を必要とするレポートクエリを考えてみよう。完全に正規化された3NF設計では、5つ以上のテーブルを結合する必要があるかもしれない。データ量が大きくなると、これらの結合がボトルネックになる可能性がある。
3NFに関連する具体的なパフォーマンス上の課題は以下の通りである:
- 結合のオーバーヘッドの増加:すべての関係において、読み取りクエリ時に結合操作が必要になる。
- ディスクI/O:データを多数のテーブルに分散させることで、データベースエンジンがアクセスしなければならないページ数が増加する。
- 複雑なクエリロジック:アプリケーションは、関連データを取得するためにより複雑なSQL文を構築しなければならない。
- キャッシュの複雑さ:非正規化された1行をキャッシュするほうが、複数の関連行をキャッシュするよりも簡単である。
整合性と速度のバランスを取るための戦略 🚀
パフォーマンスを向上させるために正規化を放棄する必要はない。3NFのデータベースを構造を維持したまま最適化するための特定の技術が存在する。以下の戦略は、速度を犠牲にすることなくデータ品質を維持するのに役立つ。
1. 選択的非正規化
すべてのテーブルが厳密に3NFである必要はありません。読み込みが重いテーブルと重要なデータパスを特定してください。これらの特定領域に制御された重複データを導入できます。例えば、顧客の名前を「注文」テーブルに直接格納するといった方法があります。注文テーブルに直接格納します。これによりデータが重複しますが、注文の検索性能は著しく向上します。顧客レコードが変更された際には、このコピーを更新するためのトリガーまたはアプリケーションロジックを実装しなければなりません。
2. 戦略的インデックス化
インデックスは結合を高速化するための主要なツールです。インデックスがなければ、データベースは各結合条件に対してテーブル全体をスキャンします。適切なインデックスを設定すれば、検索はほぼ瞬時に完了します。
- 外部キーインデックス:外部キー関係に使用される列は常にインデックスを付けるようにしてください。これにより、テーブルの結合が高速に行えるようになります。
- 複合インデックス:クエリで頻繁にその組み合わせでフィルタリングを行う場合は、複数の列にインデックスを作成してください。
- カバーインデックス:特定のクエリに必要なすべての列を含むインデックスを設計してください。これにより、データベースはメインテーブルデータへの参照を回避して、インデックスのみでクエリを満たすことができます。
3. パーティショニングとシャーディング
データセットが大きくなりすぎた場合、テーブルを分割することでパフォーマンスを向上させることができます。パーティショニングは、日付や地域などのキーに基づいて大きなテーブルを、より扱いやすい小さな物理的な部分に分割します。シャーディングはデータを複数のデータベースインスタンスに分散させます。両方の方法とも、特定のクエリに答えるためにエンジンがスキャンするデータ量を削減します。
4. 読み取りレプリカ
書き込み操作と読み取り操作を分離してください。トランザクションや更新に主データベースインスタンスを使用し、そのデータを1つ以上の読み取り専用レプリカにレプリケートします。システムに負荷をかける複雑なレポートクエリはレプリカ上で実行し、メインシステムをユーザーとのやり取りに迅速な状態に保ちます。
ERD設計上の考慮事項 📐
エンティティ関係図(ERD)を描く際、視覚的な表現は開発者がクエリを書く方法に影響を与えます。明確なERDは関係を早期に特定するのに役立ちます。しかし、紙面上では完璧に見える図でも、実際の運用環境ではパフォーマンスが悪くなることがあります。ここでは、パフォーマンスを考慮したERD設計のアプローチを説明します。
- カーディナリティを明確に特定する:すべての関係に明確なカーディナリティ(1対1、1対多、多対多)を定義してください。曖昧な関係は非効率な結合を引き起こします。
- 成長を見据えた設計:将来のデータ量を見越して設計してください。1万行で動作する設計でも、1000万行になると失敗する可能性があります。
- 結合パスを検討する:一般的なクエリが図を通じてたどるパスを確認してください。パスが長すぎる場合は、正規化されていない列を追加することを検討してください。
- 制約を文書化する:どの制約がデータベースで強制され、どの制約がアプリケーション層で処理されるかを明確に文書化してください。
比較:正規化設計 vs. 最適化設計 📊
以下の表は、特定のシナリオにおける厳格な3NFアプローチと最適化アプローチの違いを示しています。
| 機能 | 厳格な3NF設計 | 最適化設計 |
|---|---|---|
| 冗長性 | 最小限 | 制御され、限定的 |
| クエリの複雑さ | 高い(複数の結合) | 中程度(結合の数が少ない) |
| 書き込みパフォーマンス | 高速(データ量が少ない) | 変動する(更新トリガーあり) |
| 読み込みパフォーマンス | 遅い(ディスクI/O) | 高速(キャッシュされたデータ) |
| データ整合性 | 高い | 高い(検証あり) |
ルールを破るべき時 🛑
厳格な3NFを無視すべき正当な状況は存在する。何時どのように逸脱すべきかを理解することは、データベースアーキテクトにとって不可欠である。
- レポート作成および分析:データウェアハウスは通常、3NFではなくスターシステムを使用する。ここでの目的は分析用の高速読み込みであり、トランザクション整合性ではない。
- 高スループットのトランザクションシステム: システムが1秒間に数百万件の書き込みを処理する場合、複雑な結合はロック競合を引き起こす可能性がある。スキーマを簡略化することで、ロックのオーバーヘッドを削減できる。
- レガシーシステム: 古いシステムから移行する場合、アプリケーションレイヤーの再構築中に一時的に非正規化する方が速い場合がある。
- 読み込み中心のアプリケーション: アプリケーションが1回の書き込みに対して100回読み込みを行う場合、3NFの整合性を維持するコストはその利点を上回る。
実装チェックリスト ✅
データベーススキーマをデプロイする前に、このチェックリストを確認して、パフォーマンスと正規化のバランスが取れていることを確認してください。
- クエリパターンを分析する: 最も頻繁に実行される読み込みクエリを特定する。結合の数が多すぎるのではないか?
- 現在のパフォーマンスを測定する: システムのベースラインを設定してください。重要なクエリの現在のレイテンシを把握してください。
- インデックスの使用状況を確認する: インデックスが適切に利用されているか、書き込み時にオーバーヘッドを引き起こしていないか確認してください。
- 書き込み負荷のテスト: デノーマライゼーション戦略が書き込み操作をあまり遅くしないように確認してください。
- データ同期の計画: データを複製する場合、どのように同期を保ちますか?メカニズムを定義してください。
- 異常の監視: パーシャルなデノーマライゼーションを使用している場合、データの不整合に対してアラートを設定してください。
データベースアーキテクチャについての最終的な考察 🏗️
パフォーマンスを犠牲にせずに第三正規形を達成するには、繊細なアプローチが必要です。スピードと整合性の間で二元的な選択をする必要はありません。結合のコストを理解し、インデックスを効果的に活用し、適切な場面で選択的なデノーマライゼーションを適用することで、信頼性と高速性の両方を備えたシステムを構築できます。最良のデータベース設計とは、アプリケーションの特定のワークロードに合致するものです。システムが成長するにつれて、定期的にERDとクエリのパフォーマンスを確認してください。適応こそが、データ管理における長期的成功の鍵です。