










堅牢なデータアーキテクチャを設計するには、単にテーブルをつなぐこと以上が必要である。構造と整合性に対する厳格なアプローチが求められる。データアーキテクトにとって、正規化は教科書に書かれている理論的な演習以上のものであり、保守可能でスケーラブルかつ信頼性の高いデータベースシステムの基盤である。エンティティ関係図(ERD)を作成する際、スキーマ設計段階での決定がアプリケーションの長期的な健全性を左右する。適切な正規化により、データの重複を最小限に抑え、論理的な一貫性を確保し、将来にわたって連鎖的なエラーを防ぐことができる。
このガイドでは、すべてのデータアーキテクトが適用すべき基本的な正規化ルールを概説する。基本的な原子性から複雑な依存関係に至るまでの進化を検討し、各ルールがストレージ、クエリパフォーマンス、データ品質にどのように影響するかを分析する。これらの原則に従うことで、時代を超えて耐えうるシステムを構築できる。
スキーマ設計における構造の重要性とは? 📐
特定の形式に突入する前に、正規化の目的を理解することが不可欠である。主な目的は、変更、削除、挿入操作が異常を引き起こさないようデータを分離することにある。構造的なアプローチがなければ、データベースは以下の3つの特定の異常のリスクにさらされる。
-
挿入異常:関係のない別のエンティティに関するデータを追加せずに、あるエンティティに関するデータを追加できない状態。
-
更新異常:同じ値を複数の行に更新する必要があり、1行を誤って更新しなかった場合、整合性の欠如が生じるリスクがある。
-
削除異常:別のエンティティのデータを削除する際に、あるエンティティに関するデータを失ってしまう状態。
正規化は、依存関係のルールに基づいて属性をテーブルに整理することで、これらの問題に対処する。この分離により、データベースは単一の真実のソースとして機能する。プロセスは面倒に思えるかもしれないが、保守の負担とデータ破損のリスクが大幅に削減されるため、重要な投資となる。
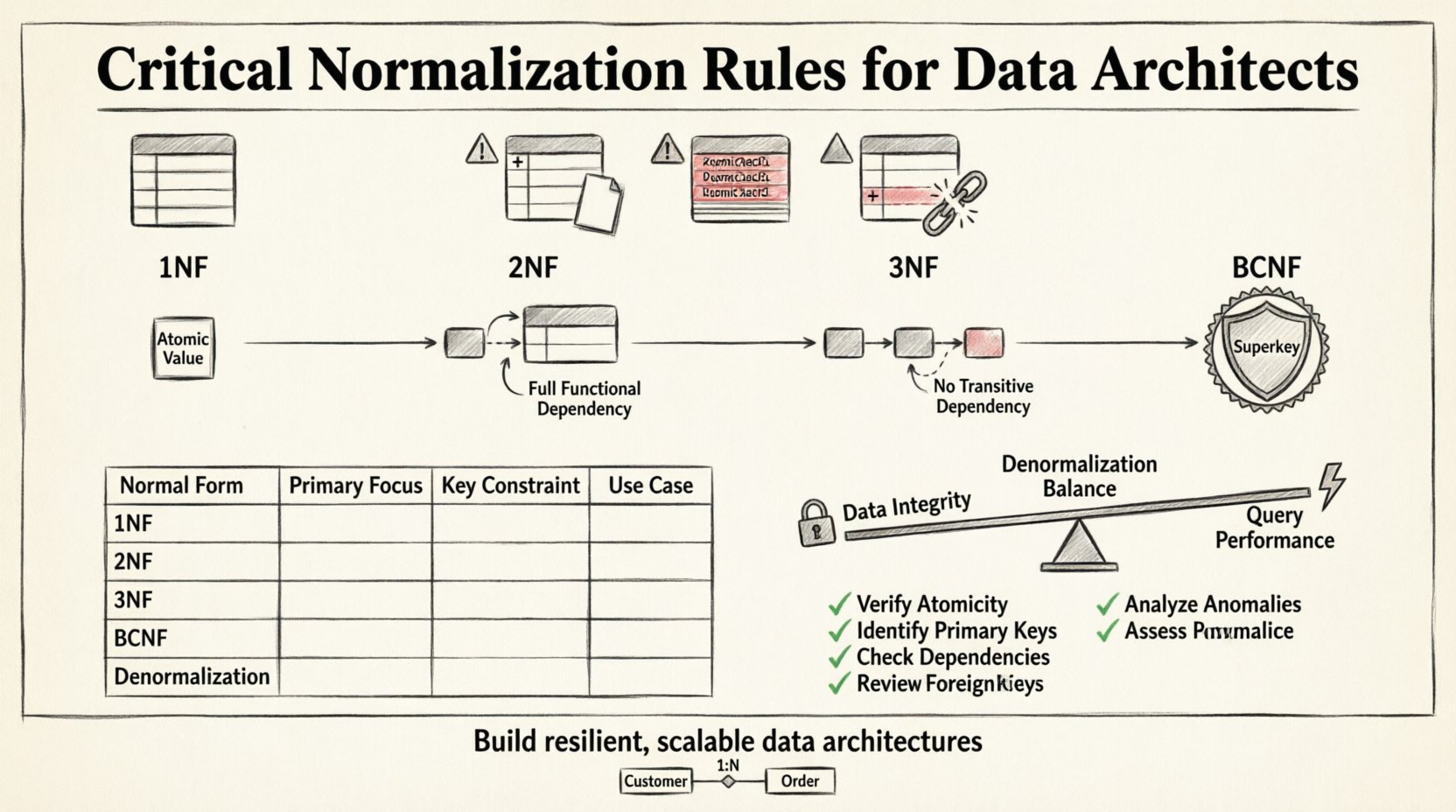
基礎:第一正規形(1NF) 🧱
正規化の第一歩は第一正規形(1NF)を達成することである。これはあらゆるリレーショナルデータベースの基本要件である。テーブルが1NFにあるとは、以下の2つの条件を満たす場合を指す:すべての値が原子的(分解不能)であり、各行の各列には1つの値しか含まれない。単一のセル内に繰り返しグループや配列があってはならない。
1NFの違反は、開発者が1つの列にリストを格納しようとする場合に頻発する。たとえば、複数の電話番号をコンマで区切って1つのフィールドに格納するような場合である。このアプローチはクエリやインデックスの処理を複雑にする。代わりに、各データは個別の行に存在すべきである。
-
原子性: 各列が単一で分解不能な値を保持していることを確認する。
-
一意の行: 各行は一意でなければならない。通常、主キーによって強制される。
-
列の順序: 列の順序がデータの意味に影響を与えてはならない。
顧客テーブルを例に考える。顧客が3つのメールアドレスを持つ場合、メールアドレス用の列を3つ作るべきではない。代わりに、外部キーでリンクされた別々の「Email」テーブルを作成する。この構造により、4つ目のメールアドレスを追加する際にも、テーブルスキーマの変更が不要になる。
部分的依存関係の排除(2NF) ⚖️
テーブルが1NFに達した後、次に部分的依存関係の有無を確認する。テーブルが2NFにあるとは、すでに1NFにあり、すべての非キー属性が主キーに完全に依存している場合を指す。このルールは、複合主キーを扱う場合に特に重要となる。
複合主キーとは、2つ以上の列から構成される主キーである。この状況下で、非キー属性が複合キーの一部にのみ依存する場合、部分的依存関係が生じる。たとえば、主キーが(注文ID、製品ID)である注文アイテムを追跡するテーブルにおいて、「製品名」の列が「製品ID」にのみ依存し、両者の組み合わせに依存しない場合がある。
-
完全依存: すべての非キー項目が、主キー全体に依存していることを確認する。
-
責任の分離: キーの部分集合に依存する属性を、新しいテーブルに移動する。
-
整合性チェック:完全なキーなしでは、どの属性も推論できないことを確認してください。
「ProductName」を「ProductID」でリンクされる独自のテーブルに移動することで、ある注文では名前が変更されても別の注文では変更されないリスクを排除できます。これにより必要なストレージが削減され、すべての注文レコード間で一貫性が保たれます。
推移的依存関係の除去(3NF) 🔗
第三正規形は、推移的依存関係に対処することで、構造をさらに一歩進めるものです。テーブルが3NFにあるのは、2NFにあり、かつすべての非キー属性が主キーに対して推移的に依存しない場合です。本質的に、これは非キー列が他の非キー列に依存してはならないことを意味します。
EmployeeID、EmployeeName、DepartmentID、DepartmentNameを持つテーブルを想像してください。EmployeeNameがDepartmentNameを決定する場合、推移的依存関係が生じます。従業員が部署を変更した場合、従業員テーブル内のDepartmentNameが正しく更新されない限り、古くなってしまう可能性があります。これを修正するには、Departmentテーブルを分離する必要があります。
-
直接の依存関係のみ:属性は他の属性ではなく、キーに対して直接依存すべきです。
-
論理的グループ化:共通の決定要因を持つ関連する属性を、独自のエンティティにグループ化する。
-
外部キー:分離されたテーブルをつなげるために外部キーを使用する。
この分離により、部門情報は一度だけ保存されます。部門名が変更された場合、一つの場所で更新され、すべての従業員レコードが関係を通じて自動的に変更を反映します。
3NFでは不十分な場合:BCNFおよびそれ以上の段階 🚀
3NFはほとんどの標準的な設計シナリオをカバーしていますが、厳密な3NFが不十分な特殊なケースもあります。ボイス・コッド正規形(BCNF)は、複数の候補キーがある場合に対処できる、より厳格な3NFのバージョンです。BCNFでは、すべての関数的依存関係X → Yについて、Xがスーパーキーでなければならないと要求します。
生徒が複数の教師を持つことができ、教師が複数の科目を担当できる状況を考えてみましょう。主キーが(生徒、科目)であり、教師が科目に基づいて割り当てられる場合、依存関係の論理が複雑に重複する状況に直面する可能性があります。BCNFは、候補キーでない列の集合によって決定される列が存在しないことを保証します。
-
スーパーキー要件:どの依存関係においても、決定要因はスーパーキーでなければならない。
-
複雑な関係:中間テーブルを使用して、多対多の関係を処理する。
-
オーバーヘッドの考慮:より高い正規形は、結合の複雑性を増加させる可能性がある。
第四正規形(4NF)および第五正規形(5NF)は、多値依存関係および結合依存関係を取り扱います。これらは一般的なビジネスアプリケーションでは稀ですが、専門的なデータウェアハウスや科学的データモデリングにおいては不可欠です。
戦略的非正規化の芸術 ⚡
正規化が常に最終目標であるとは限りません。一部の高性能環境では、厳格な正規化がクエリ速度を低下させる過剰な結合を引き起こすことがあります。このような状況で戦略的非正規化が役立ちます。非正規化とは、読み取りパフォーマンスを最適化するためにデータベースに冗長なデータを追加することを意味します。
しかし、これは任意に行うべきではありません。読み取り速度と書き込みの複雑さのトレードオフを明確に理解する必要があります。読み取り操作が書き込み操作をはるかに上回る場合、冗長性の導入は正当化される可能性があります。
-
読み取り中心のワークロード:レポート作成が主な機能である場合、非正規化によりクエリ時間を短縮できます。
-
キャッシュレイヤー:スキーマを変更する前に、アプリケーションレベルのキャッシュを使用する。
-
データ一貫性のリスク: 冗長なデータが同期からずれる可能性があることに注意してください。
-
書き込みペナルティ: すべての書き込み操作は、データのすべての冗長コピーを更新しなければなりません。
一般的なパターンとして、レポートダッシュボード用の要約テーブルを非正規化する一方で、コアのトランザクションデータは3NFの状態に保つことが挙げられます。このハイブリッドアプローチは、整合性とパフォーマンスのバランスを取っています。
正規形の比較
|
正規形 |
主な焦点 |
キー制約 |
典型的な使用ケース |
|---|---|---|---|
|
1NF |
原子値 |
繰り返しグループなし |
初期スキーマ設計 |
|
2NF |
完全依存 |
複合キーに対する部分依存なし |
複雑なキー |
|
3NF |
推移的依存 |
非キー属性はキーにのみ依存する |
一般的なビジネスロジック |
|
BCNF |
スーパーキー |
決定要因はスーパーキーでなければならない |
複雑な候補キー |
データアーキテクト向け実用チェックリスト ✅
ERDが業界標準を満たすことを確認するため、設計段階でこのチェックリストを確認してください。このプロセスにより、コードが書かれる前に潜在的な問題を特定できます。
-
原子性の確認: どの列にも複数の異なる値が含まれていないことを確認してください。
-
主キーの特定: すべてのテーブルが一意の識別子を持っていることを確認する。
-
依存関係を確認する: 各列が主キーとどのように関係しているかを明確にする。
-
外部キーを確認する: 関係性が明確に定義されていることを確認する。
-
異常を分析する: 挿入、更新、削除操作を頭の中でシミュレートする。
-
パフォーマンスを評価する: 3NFで十分か、またはパフォーマンス向上のための非正規化が必要かを判断する。
-
制約を文書化する: データ入力と検証のルールを明確に定義する。
-
成長を見据えた計画を立てる: スキーマがデータ量の増加に対応できるかを検討する。
これらのステップに従うことで、変化に強いスキーマを作成できます。データアーキテクチャは静的ではなく、ビジネスニーズとともに進化します。適切に正規化された基盤があることで、システムの一部に変更があっても他の部分に予期せぬ影響が波及するのを防ぎ、進化をスムーズにします。
正規化は法則ではなくツールであることを思い出してください。3NFはトランザクションシステムの標準ですが、アプリケーションの具体的なニーズによっては例外を設ける必要がある場合もあります。常にデータの整合性とシステムの効率性を最優先にします。これらの2つの要素を慎重にバランスさせれば、ERDはアプリケーションエコシステム全体の堅固な基盤となります。
これらの重要な正規化ルールを採用することで、今日機能するだけでなく、将来にも対応できるシステムを構築できる力が得られます。データポイント間の関係性に注目すれば、構造は自然と整います。