











L’architecture des bases de données est rarement statique. Au fur et à mesure que les applications grandissent et que les exigences évoluent, les structures de données sous-jacentes doivent s’adapter. Ce processus est connu sous le nom d’évolution du schéma. Toutefois, introduire des modifications dans une base de données de production comporte des risques importants. Une seule contrainte incorrecte ou une colonne supprimée peut bloquer la fonctionnalité de l’application ou corrompre des données critiques. Pour atténuer ces risques, les ingénieurs s’appuient sur une stratégie de validation solide fondée sur les modèles Entité-Relation (MER). 🛡️
Valider l’évolution du schéma avant le déploiement garantit que les modifications logiques s’alignent avec les contraintes physiques. Cela comble l’écart entre l’intention de conception et la réalité d’exécution. En utilisant les modèles ER comme source de vérité, les équipes peuvent simuler des modifications, vérifier les dépendances et confirmer la compatibilité sans toucher aux données en production. Cette approche réduit les temps d’indisponibilité et évite le chaos souvent lié aux scripts de migration manuels.
Pourquoi l’évolution du schéma est-elle importante 📉
Dans les cycles de développement modernes, les données sont le pilier de chaque fonctionnalité. Lorsqu’une exigence métier change, la base de données doit souvent refléter ce changement. Cela peut signifier ajouter un nouveau champ, diviser une table ou modifier un type de données. Sans un processus de validation structuré, ces modifications deviennent une loterie.
Les défis courants lors de l’évolution incluent :
- Modifications destructrices :La suppression d’une colonne dont dépendent les applications provoque immédiatement des erreurs.
- Détérioration des performances :L’ajout d’index ou le changement de moteur de stockage peut ralentir inopinément les requêtes.
- Perte d’intégrité des données :Des contraintes mal définies peuvent permettre à des données invalides d’entrer dans le système.
- Temps d’indisponibilité :Verrouiller les tables pendant la migration peut rendre l’application indisponible pour les utilisateurs.
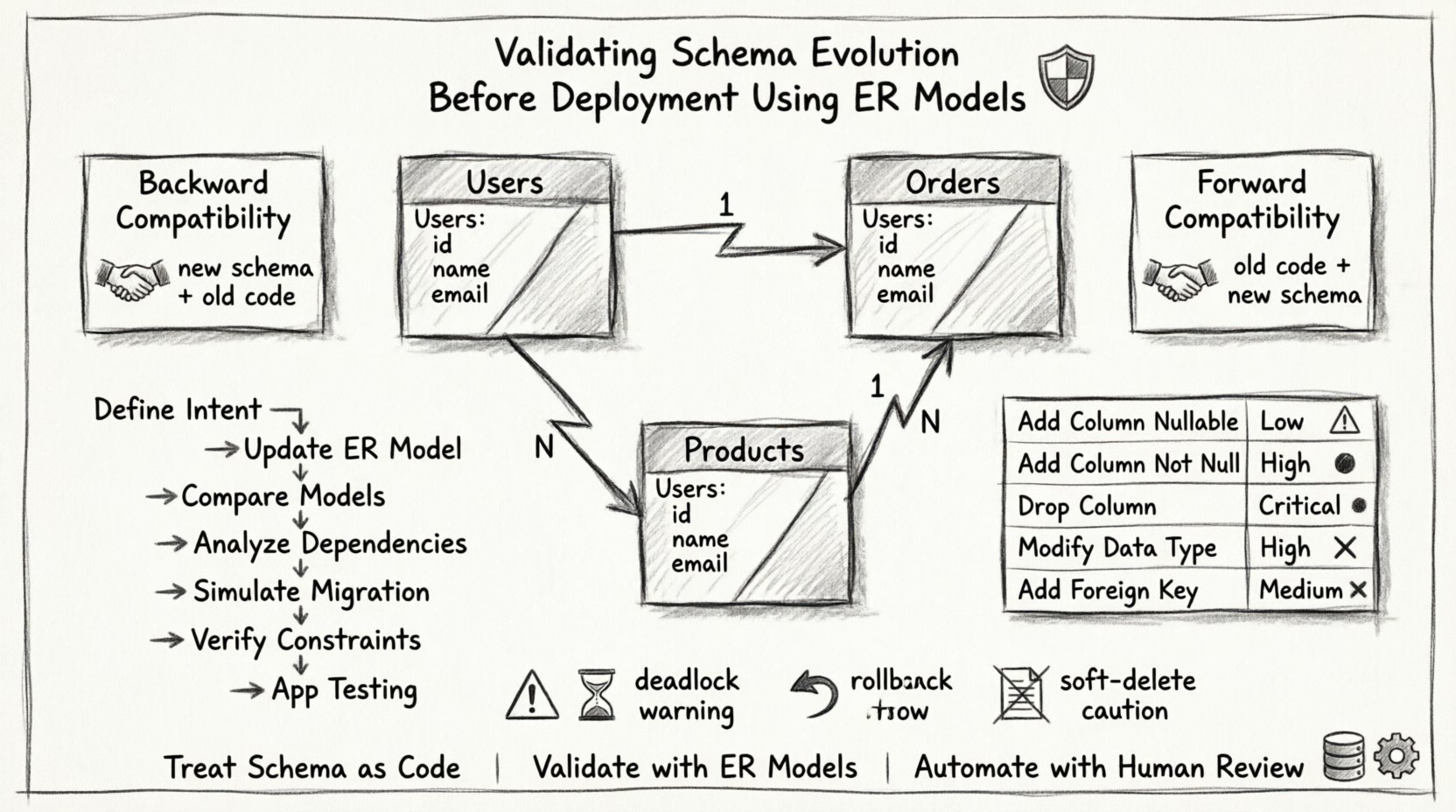
Utiliser un modèle ER permet aux architectes de visualiser ces risques avant qu’ils ne surviennent. Le modèle sert de plan, montrant clairement les relations, la cardinalité et les contraintes. 📐
Le rôle des modèles ER dans la validation 🧩
Un modèle Entité-Relation représente la structure logique d’une base de données. Il définit les entités (tables), les attributs (colonnes) et les relations (clés étrangères). Lors de la validation de l’évolution, le modèle ER sert de référence de comparaison.
Voici comment le modèle aide à la validation :
- Cartographie des dépendances :Il montre quelles tables dépendent d’autres. Si une table parente change, la table enfant doit être vérifiée.
- Vérification des contraintes :Les clés primaires et les contraintes uniques sont visibles d’un coup d’œil, garantissant qu’elles ne soient pas violées lors des mises à jour.
- Vérifications de normalisation :Il aide à vérifier que les nouvelles structures respectent encore les règles de normalisation, évitant ainsi la redondance.
- Contexte historique :Comparer le diagramme ER actuel avec celui proposé met précisément en évidence ce qui a changé.
En traitant le diagramme ER comme un artefact contrôlé en version, les équipes peuvent suivre l’évolution au fil du temps. Cela crée une traçabilité pour expliquer pourquoi des décisions spécifiques ont été prises concernant le schéma.
Identification des types de changement 🔍
Tous les changements de schéma ne sont pas équivalents. Certains sont sans risque, tandis que d’autres exigent des stratégies de migration complexes. Catégoriser les changements aide à déterminer le niveau de validation nécessaire.
| Type de changement | Niveau de risque | Objectif de validation |
|---|---|---|
| Ajouter une colonne (peut être nulle) | Faible | Vérifiez les valeurs par défaut et la taille de stockage. |
| Ajouter une colonne (non nulle) | Élevé | Assurez-vous que les données existantes satisfont la contrainte ou fournissez une valeur par défaut. |
| Supprimer une colonne | Critique | Vérifiez qu’aucun code d’application ne fait référence à la colonne. |
| Modifier le type de données | Élevé | Vérifiez la troncature des données ou la perte de précision. |
| Ajouter une clé étrangère | Moyen | Assurez-vous que l’intégrité référentielle est maintenue sur toutes les lignes existantes. |
Comprendre ces catégories permet aux ingénieurs de prioriser leurs efforts de test. Les modifications critiques nécessitent une revue manuelle, tandis que les modifications à faible risque pourraient être automatisées.
Stratégies de compatibilité 🔄
Lors du déploiement de modifications du schéma, maintenir la compatibilité avec l’application est crucial. Deux stratégies principales doivent être prises en compte : la compatibilité descendante et la compatibilité montante.
Compatibilité descendante
Cela garantit que le nouveau schéma fonctionne avec le code d’application ancien. C’est essentiel lors du déploiement de modifications de base de données avant les mises à jour de l’application. Par exemple, si vous ajoutez une colonne, le code ancien ne doit pas planter s’il ignore la nouvelle colonne. Si vous supprimez une colonne, le code ancien doit continuer à fonctionner ou être mis à jour simultanément.
Compatibilité montante
Cela garantit que l’application ancienne peut toujours lire le nouveau schéma. Cela est utile lorsque la base de données est mise à jour avant l’application. Par exemple, ajouter une colonne permet aux anciennes requêtes de s’exécuter sans erreur, même si elles n’utilisent pas les nouvelles données.
Un processus de validation robuste vérifie les deux directions. Le modèle MER aide à visualiser si un changement rompt le contrat entre l’application et la base de données. 🤝
Le processus de validation étape par étape 🚀
L’exécution d’un changement de schéma nécessite un workflow discipliné. Faire confiance à la mémoire ou à des scripts rapides est dangereux. Suivez cette approche structurée pour valider l’évolution en toute sécurité.
- Définir l’intention :Documentez clairement ce qui doit être modifié et pourquoi. Cela évite le dérapage de portée.
- Mettre à jour le modèle MER :Créez l’état proposé du diagramme. N’appliquez pas encore les modifications à la base de données physique.
- Comparer les modèles :Générez un diff entre les diagrammes ER actuels et proposés. Identifiez les entités ajoutées, supprimées ou modifiées.
- Analyser les dépendances :Suivez les clés étrangères et les index. Assurez-vous qu’aucune relation orpheline ne résulte de ce changement.
- Simuler la migration :Exécutez le script de migration dans un environnement de préproduction qui reflète le volume de données de production.
- Vérifier les contraintes :Assurez-vous que les déclencheurs, les vérifications et les contraintes sont correctement appliqués.
- Tests de l’application :Exécutez l’application contre le nouveau schéma pour vous assurer que les requêtes renvoient les résultats attendus.
Les outils d’automatisation peuvent aider aux étapes 3, 5 et 6, mais une revue humaine reste essentielle pour les logiques complexes.
Intégrité des données et contraintes 🛑
Le point le plus critique de l’évolution du schéma est l’intégrité des données. Un changement qui semble correct sur papier peut échouer lorsqu’il est appliqué à des millions de lignes. Les modèles ER aident à visualiser les contraintes, mais la validation nécessite de les tester sur des données réelles.
Les domaines clés à examiner incluent :
- Clés primaires :Assurez-vous que l’unicité n’est pas compromise.
- Clés étrangères :Vérifiez les dépendances circulaires qui pourraient entraîner un blocage.
- Contraintes de vérification :Validez que les règles métier (par exemple, l’âge doit être positif) sont respectées pour les données existantes.
- Index :Confirmez que les nouveaux index ne sont pas en conflit avec les index existants ni ne causent une latence d’écriture excessive.
Par exemple, modifier une colonne de INT à VARCHARcela pourrait sembler sûr, mais si l’application attend des opérations numériques, des erreurs se produiront. Le modèle ER doit refléter le type logique, mais l’implémentation physique doit correspondre.
Péchés courants à éviter ⚠️
Même les équipes expérimentées commettent des erreurs. Être conscient des pièges courants aide à créer un processus de validation plus résilient.
- Ignorer les blocages : Les migrations longues peuvent verrouiller des tables, entraînant des délais d’attente de l’application. Validez la durée des verrous.
- Supposer une absence d’indisponibilité : Certaines modifications nécessitent intrinsèquement une indisponibilité. Prévoyez-la explicitement plutôt que d’espérer le meilleur.
- Sauter les plans de retour arrière : Si la validation réussit mais que la production échoue, un script de retour arrière est obligatoire. Testez le retour arrière aussi rigoureusement que la migration.
- Passer sous silence les suppressions douces : Modifier la logique pour les enregistrements supprimés de manière douce peut entraîner une perte de données si cela n’est pas traité avec soin.
Automatiser le flux de travail ⚙️
Bien que la validation manuelle soit approfondie, elle ne se généralise pas. Les outils d’automatisation peuvent analyser les modèles ER et générer des scripts de migration. Ils peuvent également exécuter des vérifications de style pour détecter les erreurs courantes avant le déploiement.
Les avantages de l’automatisation incluent :
- Conformité : Toute modification suit les mêmes règles.
- Vitesse : Les scripts s’exécutent plus rapidement que les revues manuelles.
- Documentation : Les rapports générés servent de preuve de validation pour les audits de conformité.
- Intégration : Les vérifications automatisées peuvent faire partie du pipeline CI/CD, bloquant les déploiements si la validation échoue.
Cependant, l’automatisation ne doit pas remplacer le jugement humain. La logique métier complexe nécessite souvent une revue par un ingénieur senior qui comprend le contexte des données.
Pensées finales sur la gestion du schéma 🌱
L’évolution du schéma est un processus continu qui exige une vigilance constante. Traiter le schéma de base de données comme du code est la première étape vers la fiabilité. En utilisant des modèles ER pour valider les modifications, les équipes peuvent maintenir une haute disponibilité et une précision des données.
L’objectif n’est pas seulement de réaliser des modifications, mais de le faire en toute sécurité. Un schéma bien validé garantit que l’application reste stable même au fur et à mesure que les exigences évoluent. Cette discipline renforce la confiance entre l’équipe de développement et l’infrastructure. 🏗️
Investissez du temps dans la phase de conception. Créez des diagrammes clairs. Documentez chaque contrainte. Testez chaque migration. Ces pratiques forment la base d’un écosystème de données sain. Lorsque la base de données est stable, l’application peut prospérer.
Souvenez-vous que la validation du schéma n’est pas un événement ponctuel. C’est une culture. Au fur et à mesure que le système grandit, le processus de validation doit évoluer avec lui. Les revues régulières du modèle ER garantissent que l’architecture reste alignée sur les objectifs métiers. Cette approche proactive empêche la dette technique de s’accumuler au fil du temps.