











Concevoir une structure de base de données robuste exige précision et vision d’ensemble. Le diagramme Entité-Relation (ERD) sert de plan fondamental pour cette architecture. Sans une carte claire, la redondance des données et les goulets d’étranglement des requêtes apparaissent rapidement, entraînant une dégradation des performances au fil du temps. Ce guide explore comment dériver directement des techniques d’optimisation à partir de ces modèles visuels. Nous nous concentrons sur l’intégrité structurelle et le réglage des performances sans dépendre de fonctionnalités spécifiques à une plateforme ou d’outils propriétaires. En comprenant les relations sous-jacentes, vous pouvez construire des systèmes qui évoluent efficacement.
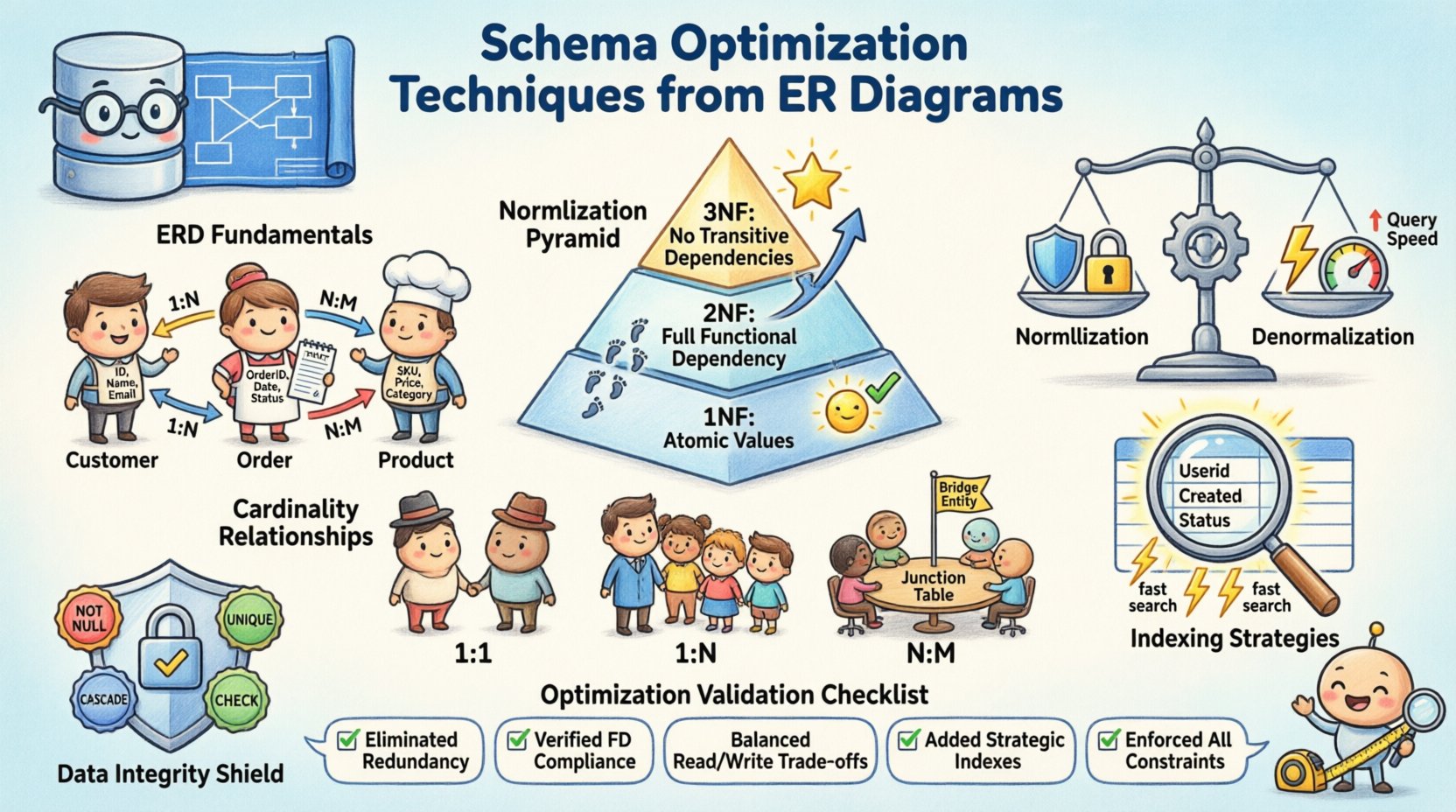
📐 Comprendre les fondamentaux des ERD
Avant de commencer l’optimisation, les composants essentiels doivent être clairement définis. Un diagramme ER traduit les exigences métiers en un modèle de données logique. Il définit la manière dont les informations sont stockées et accessibles. Une fondation solide évite la dette structurelle ultérieurement dans le cycle de développement. Considérez les éléments suivants :
- Entités : Représentent des objets ou des concepts, tels que les clients, les commandes ou les produits. Chaque entité devient une table dans le schéma physique.
- Attributs : Définissent les propriétés des entités, comme le nom, l’ID ou l’horodatage. Ceux-ci deviennent des colonnes au sein des tables.
- Relations : Montrent comment les entités interagissent. Elles déterminent l’utilisation des clés étrangères et des contraintes.
Visualiser ces composants vous permet d’identifier des problèmes potentiels avant d’écrire une seule ligne de code. Cela garantit que le flux logique correspond aux exigences de stockage physique. Cette alignement est crucial pour maintenir la cohérence des données dans des applications complexes.
🔨 Stratégies de normalisation pour l’intégrité des données
La normalisation est le processus d’organisation des données afin de réduire la redondance et d’améliorer l’intégrité. Elle consiste à diviser les grandes tables en unités logiques plus petites. Bien qu’une normalisation excessive puisse ralentir les lectures, son omission totale entraîne des anomalies de mise à jour. L’objectif est de trouver un équilibre adapté à votre charge de travail spécifique.
Première forme normale (1NF)
La première règle exige que chaque colonne contienne des valeurs atomiques. Aucun groupe répétitif ou tableau n’est autorisé dans une seule cellule. Cela garantit que chaque élément de données est distinct et consultable. Par exemple, une liste de numéros de téléphone doit être divisée en lignes distinctes ou dans une table associée, et non stockée sous forme de chaîne séparée par des virgules.
Deuxième forme normale (2NF)
Une fois la 1NF respectée, la 2NF traite les dépendances partielles. Tous les attributs non clés doivent dépendre de la clé primaire entière. Dans les clés composées, cela évite la duplication de données lorsque seule une partie de la clé détermine un attribut. Cette étape affine la structure pour garantir que chaque élément d’information est correctement lié à son parent.
Troisième forme normale (3NF)
La troisième forme élimine les dépendances transitives. Les attributs non clés ne doivent pas dépendre d’autres attributs non clés. Cela signifie que si l’attribut A dépend de l’attribut B, et que B dépend de la clé, alors A ne doit pas exister dans la même table. Déplacer de telles données vers une table séparée améliore la maintenabilité et réduit le gaspillage de stockage.
Le tableau ci-dessous résume l’évolution de la normalisation :
| Forme normale | Objectif principal | Contrainte clé |
|---|---|---|
| 1NF | Valeurs atomiques | Pas de groupes répétitifs |
| 2NF | Dépendance complète | Supprimer les dépendances partielles |
| 3NF | Indépendance | Supprimer les dépendances transitives |
⚡ Dénormalisation pour des performances
Alors que la normalisation assure l’intégrité, elle nécessite souvent des jointures complexes lors des requêtes. Dans les systèmes à forte charge de lecture, le surcoût de la jointure de plusieurs tables peut devenir un goulot d’étranglement. La dénormalisation introduit intentionnellement de la redondance afin d’améliorer la vitesse de récupération. Il s’agit d’un compromis entre l’efficacité du stockage et les performances des requêtes.
Pensez aux scénarios suivants où la dénormalisation est appropriée :
- Tableaux de bord de reporting :Les données agrégées peuvent être prédéterminées et stockées afin d’éviter les calculs en temps réel.
- Couches de mise en cache :Les données fréquemment consultées peuvent être dupliquées dans un magasin optimisé pour la lecture.
- Transactions à haut débit :Réduire la profondeur des jointures minimise la contention de verrous et l’utilisation du CPU.
Lors de la mise en œuvre de cette approche, établissez un processus clair de mise à jour des données redondantes. Les incohérences apparaissent si la source de vérité change sans mettre à jour les copies. Des déclencheurs automatiques ou une logique d’application doivent gérer la synchronisation afin de maintenir l’exactitude.
🔗 Gestion de la cardinalité et des relations
La cardinalité définit la relation numérique entre les entités. Elle détermine la manière dont les clés étrangères sont implémentées et comment les données sont liées. Comprendre ces modèles est essentiel pour éviter les enregistrements orphelins et garantir l’intégrité référentielle.
- Un à un :Rare dans les systèmes généraux, souvent utilisé pour des tables de sécurité ou d’extension. Une seule ligne dans la table A est liée à exactement une ligne dans la table B.
- Un à plusieurs :La relation la plus courante. Un enregistrement parent est lié à plusieurs enregistrements enfants. La clé étrangère se trouve dans la table enfant.
- Plusieurs à plusieurs :Nécessite une table de jonction pour résoudre la relation. Cette table intermédiaire relie les clés primaires des deux entités.
Des hypothèses incorrectes sur la cardinalité entraînent un stockage inefficace ou des états de données invalides. Par exemple, traiter une relation plusieurs à plusieurs comme une colonne simple empêchera les multiples associations. Modéliser correctement ces liens garantit que la base de données peut appliquer les règles métier définies dans le schéma.
📉 Stratégies d’indexation basées sur une analyse structurelle
Les index sont le mécanisme qui permet au moteur de base de données de trouver rapidement les données. La structure du schéma ERD indique directement quelles colonnes doivent être indexées. L’ajout aveugle d’index consomme de l’espace disque et ralentit les opérations d’écriture.
Les considérations clés en matière d’indexation incluent :
- Clés primaires :Toujours indexées par défaut. Elles définissent l’identité unique de chaque ligne.
- Clés étrangères :Souvent nécessitent un index pour accélérer les opérations de jointure et les vérifications de contraintes.
- Clés composées :Utilisées lorsque les requêtes filtrent par plusieurs colonnes. L’ordre des colonnes dans l’index est important pour les performances.
- Colonnes sélectives :Indexez les colonnes à forte cardinalité. Une faible sélectivité (par exemple, le sexe) bénéficie rarement d’un index.
Analysez vos modèles de requêtes par rapport à la conception du schéma. Si un jointure spécifique est exécutée fréquemment, assurez-vous que la colonne clé étrangère est indexée. Cela réduit le temps que la base de données passe à scanner des tables entières.
🛡️ Intégrité des données et contraintes référentielles
Les contraintes d’intégrité protègent l’exactitude et la cohérence des données. Elles agissent comme une barrière de sécurité contre les entrées non valides ou les suppressions accidentelles. Bien que certaines contraintes soient appliquées par l’application, les contraintes au niveau de la base de données sont plus fiables.
Les types de contraintes courants incluent :
- NOT NULL :Assure qu’une colonne contient toujours une valeur. Empêche les lacunes dans les champs de données critiques.
- UNIQUE :Assure qu’aucune paire de lignes ne partage la même valeur dans une colonne spécifique. Utile pour les courriels ou les noms d’utilisateur.
- CASCADE :Définit ce qui se passe avec les enregistrements enfants lorsqu’un parent est supprimé. Les options incluent restreindre, propager ou définir comme nul.
- CHECK :Impose des conditions spécifiques sur les valeurs des données, telles que des plages de dates ou des limites numériques.
Mettre en œuvre ces règles au niveau de la base de données empêche l’application de devoir valider chaque point de données. Cela centralise la logique de validité des données, réduisant ainsi la duplication de code et les erreurs potentielles.
🔄 Affinement itératif et évolution du schéma
La conception du schéma n’est pas une tâche unique. Les exigences métier évoluent, et le modèle de données doit évoluer. Les revues régulières du MCD et du schéma physique aident à identifier les domaines d’amélioration. Le suivi des performances des requêtes fournit des indices sur les points où la structure peine.
Pendant l’affinement, considérez les étapes suivantes :
- Revoyez l’utilisation des index :Supprimez les index inutilisés pour réduire la charge d’écriture.
- Vérifiez le partitionnement :Les grandes tables peuvent bénéficier du fractionnement des données selon des plages ou des clés.
- Mettez à jour la cardinalité :Au fur et à mesure que la logique métier évolue, les relations peuvent passer d’un-to-many à many-to-many.
- Contrôle de version :Traitez les modifications du schéma comme du code. Suivez les modifications pour permettre un retour en arrière si nécessaire.
Cette approche itérative garantit que la base de données reste en phase avec les besoins de l’application au fil du temps. Elle empêche l’accumulation de dette technique qui ralentit le développement futur.
✅ Liste de contrôle d’optimisation
Utilisez cette liste pour valider votre conception de schéma avant le déploiement :
- Vérifiez que toutes les tables respectent au moins la Troisième Forme Normale (3NF).
- Assurez-vous que les clés étrangères sont indexées là où les jointures sont fréquentes.
- Vérifiez les dépendances circulaires dans les relations.
- Confirmez que les clés primaires sont définies pour chaque table.
- Revoyez les contraintes pour vous assurer que les règles de cohérence des données sont appliquées.
- Analysez les modèles de requêtes pour identifier des opportunités potentielles de dénormalisation.
- Documentez toutes les hypothèses concernant la cardinalité et le volume des données.
Suivre ces étapes crée une base solide pour le stockage des données. Cela permet au système de gérer la croissance sans nécessiter une reconstruction complète. Un schéma bien optimisé fait la différence entre une application lente et une application réactive.