











La conception d’une base de données est un exercice d’équilibre. Elle exige de structurer les données afin de refléter les relations du monde réel tout en maintenant les performances et l’intégrité. Un piège courant dans ce processus est l’introduction de dépendances circulaires au sein des diagrammes Entité-Relation (ERD). Ces boucles se produisent lorsque chaîne de relations de clés étrangères pointe finalement vers l’entité d’origine. Bien qu’elles semblent logiques en isolation, de telles structures posent des défis importants pour la gestion des données, l’optimisation des requêtes et la stabilité du système.
La résolution de ces problèmes exige une compréhension approfondie de la théorie relationnelle et une planification architecturale soigneuse. Ce guide explore les mécanismes des dépendances circulaires, leur impact sur la santé de la base de données, et des stratégies éprouvées pour refactorer les schémas afin d’obtenir des performances optimales.
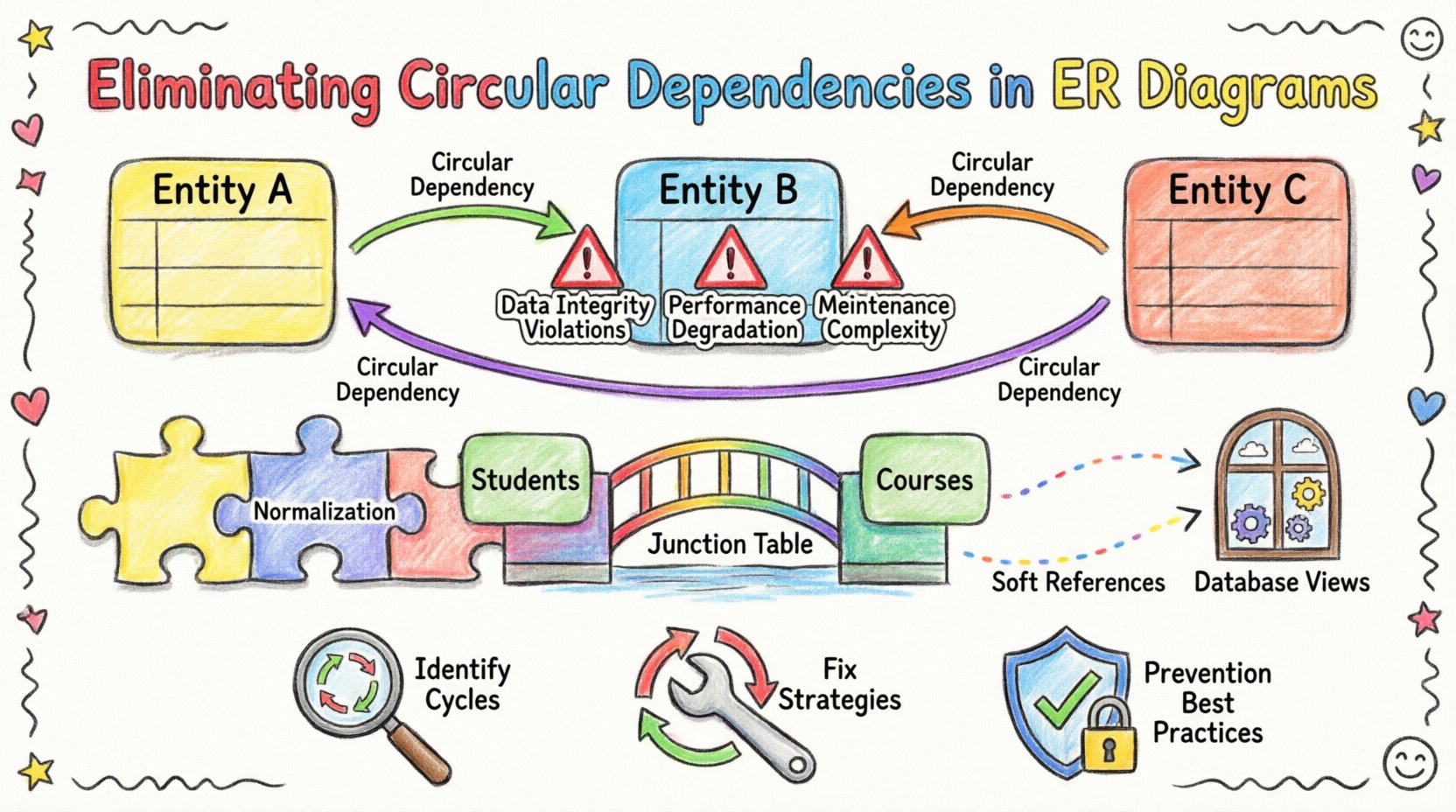
🧩 Comprendre les dépendances circulaires dans les ERD
Dans un modèle relationnel standard, une contrainte de clé étrangère établit un lien d’une table enfant vers une table parent. Ce lien garantit l’intégrité référentielle, en s’assurant que les données dans la table enfant correspondent à des entrées valides dans la table parent. Une dépendance circulaire apparaît lorsque cette chaîne ne se termine pas proprement. Au lieu de cela, l’entité A référence l’entité B, qui référence l’entité C, qui référence finalement l’entité A.
Considérons un scénario impliquant une structure hiérarchique. Si chaque nœud d’un arbre doit connaître son parent et ses enfants, des relations bidirectionnelles peuvent facilement former des boucles. Sans une gestion soigneuse, le moteur de base de données ne peut pas déterminer l’ordre des opérations lors de l’insertion ou de la suppression des données.
Types de références circulaires
- Cycles directs : L’entité A possède une clé étrangère vers l’entité B, et l’entité B possède une clé étrangère de retour vers l’entité A. Cela est souvent observé dans des relations bidirectionnelles où les deux côtés suivent l’autre.
- Cycles indirects : Une chaîne de trois entités ou plus forme une boucle. Par exemple, A → B → C → A. Ceux-ci sont plus difficiles à repérer visuellement dans des schémas complexes.
- Boucles auto-référentielles : Une entité se réfère à elle-même. Bien que courant dans les données hiérarchiques (comme une table des employés où un manager est aussi un employé), une mise en œuvre incorrecte peut entraîner une récursion infinie.
⚠️ L’impact des boucles non résolues
Laisser les dépendances circulaires non résolues n’est pas simplement un souci théorique. Cela introduit des risques concrets au niveau de la couche application et du moteur de base de données lui-même.
1. Violations de l’intégrité des données
Lorsque le moteur de base de données tente d’insérer des données dans une boucle, il doit déterminer l’ordre des opérations. Si A nécessite que B existe, et que B nécessite que A existe, aucun ne peut être créé en premier. Cela entraîne des violations de contraintes. Bien que certains systèmes de base de données permettent un contrôle de contrainte différé, compter sur cette fonctionnalité masque souvent des erreurs logiques.
2. Détérioration des performances
Les requêtes qui parcourent des chemins circulaires peuvent devenir inefficaces. Les opérations de jointure dans une boucle peuvent pousser l’optimiseur à choisir des plans d’exécution sous-optimaux. Dans les pires scénarios, les requêtes récursives destinées à parcourir une hiérarchie peuvent entrer dans des boucles infinies, consommant des ressources CPU et mémoire jusqu’à la fermeture de la connexion.
3. Complexité de maintenance
Modifier un schéma comportant des dépendances circulaires est risqué. Supprimer une table dans une boucle peut échouer si les clés étrangères sont actives. Les opérations de suppression en cascade peuvent déclencher des réactions en chaîne imprévues. Les développeurs se retrouvent souvent à écrire une logique au niveau de l’application pour contourner les contraintes de base de données, ce qui déplace la responsabilité de l’intégrité loin de la source de vérité.
🔍 Identification des dépendances circulaires
Avant de corriger le problème, vous devez le localiser. Dans les petits diagrammes, une inspection visuelle suffit. Dans les systèmes d’entreprise avec des centaines de tables, le traçage manuel est sujet à erreur. Utilisez les techniques suivantes pour auditer votre schéma.
- Analyse du graphe : Traitez l’ERD comme un graphe orienté. Les nœuds représentent les tables, et les arêtes représentent les clés étrangères. Une boucle existe si un chemin ramène au nœud de départ.
- Arbres de dépendance : Générez un arbre de dépendance pour chaque table. Si une table apparaît comme son propre ancêtre dans l’arbre, une boucle existe.
- Interrogation des tables système : La plupart des systèmes de gestion de base de données stockent les métadonnées des clés étrangères dans des catalogues système. Écrivez des requêtes pour parcourir ces relations de manière programmatique.
🛠️ Stratégies de résolution
Une fois identifiées, les dépendances circulaires doivent être rompues. L’objectif est de préserver la relation logique sans créer de boucle physique. Voici les principales méthodes pour y parvenir.
1. Normaliser le schéma
La normalisation est le processus d’organisation des données afin de réduire la redondance et d’améliorer l’intégrité. Souvent, les dépendances circulaires proviennent d’une tentative de modéliser des relations qui n’appartiennent pas à un seul niveau d’abstraction.
- Troisième forme normale (3FN) : Assurez-vous que les attributs non clés dépendent uniquement de la clé primaire. Si une table contient une clé étrangère vers elle-même pour représenter une hiérarchie, envisagez de séparer la logique de hiérarchie dans une table de relation distincte.
- Supprimer la redondance : Si l’entité A et l’entité B se référencent mutuellement, demandez-vous si l’une de ces références est redondante. Peut-on représenter la relation dans un seul sens ?
2. Introduire une table d’association
Les relations many-to-many sont une source fréquente de boucles circulaires. Au lieu de placer directement les clés étrangères dans les entités principales, utilisez une table intermédiaire.
Par exemple, si Étudiants et Cours ont une relation many-to-many, ne pas ajouter un id_cours à la table des Étudiants et un id_étudiant à la table des Cours table. À la place, créez une table Inscriptions qui contient les deux identifiants. Cela rompt le lien direct entre les deux entités principales.
3. Utiliser des vues pour les relations logiques
Parfois, le stockage physique n’a pas besoin de refléter la exigence logique. Si l’application doit voir une relation entre A et B, mais que le stockage direct crée un cycle, utilisez une vue de base de données.
- Modèle physique : Stockez A et B sans lien de clé étrangère direct.
- Modèle logique : Créez une vue qui joint A et B sur la base d’un attribut commun ou d’une table de relation séparée.
Cela déconnecte les contraintes de stockage de la logique d’application, permettant à la base de données d’assurer l’intégrité là où cela est important, sans créer de boucles physiques.
4. Mettre en œuvre des références souples
Dans certains cas, une intégrité référentielle stricte n’est pas nécessaire pour la relation. Vous pouvez stocker l’ID de l’entité associée comme colonne entière simple plutôt que comme contrainte de clé étrangère.
- Avantages : Supprime la vérification de la contrainte lors de l’insertion/suppression, permettant à la boucle d’exister physiquement sans bloquer les opérations.
- Inconvénients : La base de données n’assure plus la relation. La logique de l’application doit valider que l’ID référencé existe.
📊 Comparaison des approches de réfactoring
| Approche | Complexité | Application de l’intégrité | Meilleur cas d’utilisation |
|---|---|---|---|
| Normalisation | Élevée | Complète | Lorsque la redondance des données est la cause principale. |
| Table de jonction | Moyenne | Complète | Relations many-to-many. |
| Vues | Faible | Partielle (au niveau de la requête) | Reporting ou charges de travail fortement en lecture. |
| Références souples | Faible | Aucune (au niveau de l’application) | Systèmes hérités ou relations facultatives. |
🛡️ Prévention et bonnes pratiques
Une fois un schéma réfactorisé, l’attention se déplace vers la prévention des cycles futurs. Les modèles de conception et les processus de gouvernance peuvent atténuer le risque de réintroduire ces problèmes.
1. Définir la direction des relations
Établir une règle selon laquelle les clés étrangères doivent toujours s’orienter dans une direction spécifique. Par exemple, les tables enfants font toujours référence aux parents, jamais l’inverse. Si un parent doit accéder aux données enfants, utiliser une requête ou une vue plutôt qu’une clé étrangère.
2. Modéliser les hiérarchies avec soin
Les tables auto-référentielles sont courantes pour les organigrammes ou les fils de commentaires. Pour éviter les boucles :
- Uniquement parent : Stocker uniquement le
parent_id. Ne pas stockerchildren_idsdans la même ligne. - Énumération du chemin : Pour les hiérarchies profondes, stocker la chaîne complète du chemin (par exemple,
/1/5/9/) pour permettre des requêtes rapides sans jointures récursives.
3. Audits automatisés du schéma
Intégrer la détection de cycles dans le pipeline CI/CD. Les scripts peuvent analyser les fichiers de définition du schéma (tels que les scripts de migration SQL) et signaler toute nouvelle définition de clé étrangère qui crée une boucle avant le déploiement.
4. Documentation
Maintenir un schéma ER à jour. Lorsqu’un développeur ajoute une table, il doit mettre à jour le diagramme. Cet outil visuel aide à identifier les cycles potentiels avant l’écriture du code. Les outils qui génèrent automatiquement la documentation à partir du schéma de la base de données sont fortement recommandés pour les équipes importantes.
🔄 Gestion des systèmes hérités
Le refactoring d’une base de données en production n’est pas toujours réalisable en raison des coûts d’indisponibilité ou du volume de données. Dans ces cas, une approche progressive est nécessaire.
- Identifier les chemins critiques :Prioriser la rupture des cycles qui affectent les requêtes les plus fréquemment utilisées.
- Utiliser la logique d’application :Déplacer temporairement la gestion des relations au niveau de la couche application. Stocker les identifiants comme des colonnes simples et les valider dans le code.
- Planifier la migration :Planifier une fenêtre de maintenance pour convertir les références au niveau de l’application en contraintes physiques une fois que la nouvelle structure est stable.
📝 Considérations finales sur l’hygiène du schéma
Un schéma ER propre est la fondation d’une application robuste. Les dépendances circulaires sont un symptôme d’un design qui privilégie la commodité au détriment de la structure. En respectant les principes de normalisation et en utilisant des tables d’association là où cela est pertinent, vous pouvez garantir que vos données restent cohérentes et consultables.
Souvenez-vous que la conception de base de données est itérative. Au fur et à mesure que les besoins métiers évoluent, les relations changent. Revoyez régulièrement votre schéma pour vous assurer qu’il correspond toujours à vos objectifs. Une validation continue et une approche disciplinée des clés étrangères maintiendront votre architecture résiliente face à la complexité croissante des besoins en données.