










Concevoir une architecture de données solide exige bien plus que de simples liaisons entre des tables ; cela exige une approche rigoureuse en matière de structure et d’intégrité. Pour les architectes de données, la normalisation n’est pas simplement un exercice théorique trouvé dans les manuels : elle constitue le pilier des systèmes de bases de données maintenables, évolutifs et fiables. Lors de la construction de diagrammes entité-association (ERD), les décisions prises pendant la phase de conception du schéma déterminent la santé à long terme de l’application. Une normalisation adéquate minimise la redondance des données et garantit la cohérence logique, empêchant ainsi des erreurs en chaîne plus tard.
Ce guide présente les règles essentielles de normalisation que chaque architecte de données doit appliquer. Nous explorerons la progression allant de l’atomicité fondamentale aux dépendances complexes, en examinant l’impact de chaque règle sur le stockage, les performances des requêtes et la qualité des données. En suivant ces principes, vous construisez des systèmes capables de résister à l’épreuve du temps.
Pourquoi la structure compte dans la conception du schéma 📐
Avant de plonger dans les formes spécifiques, il est essentiel de comprendre l’objectif de la normalisation. Le but principal est d’isoler les données afin que les modifications, suppressions et insertions n’entraînent pas d’anomalies. Sans une approche structurée, les bases de données deviennent sujettes à trois types spécifiques d’anomalies :
-
Anomalies d’insertion : Incapacité à ajouter des données concernant une entité sans ajouter des données concernant une autre entité non liée.
-
Anomalies de mise à jour : La nécessité de mettre à jour la même valeur dans plusieurs lignes, risquant une incohérence si une ligne est oubliée.
-
Anomalies de suppression : Perdre des données concernant une entité lors de la suppression de données concernant une autre.
La normalisation résout ces problèmes en organisant les attributs en tables selon des règles de dépendance. Cette séparation permet à la base de données de fonctionner comme source unique de vérité. Bien que le processus puisse sembler fastidieux, la réduction de la charge de maintenance et des risques de corruption des données en fait un investissement essentiel.
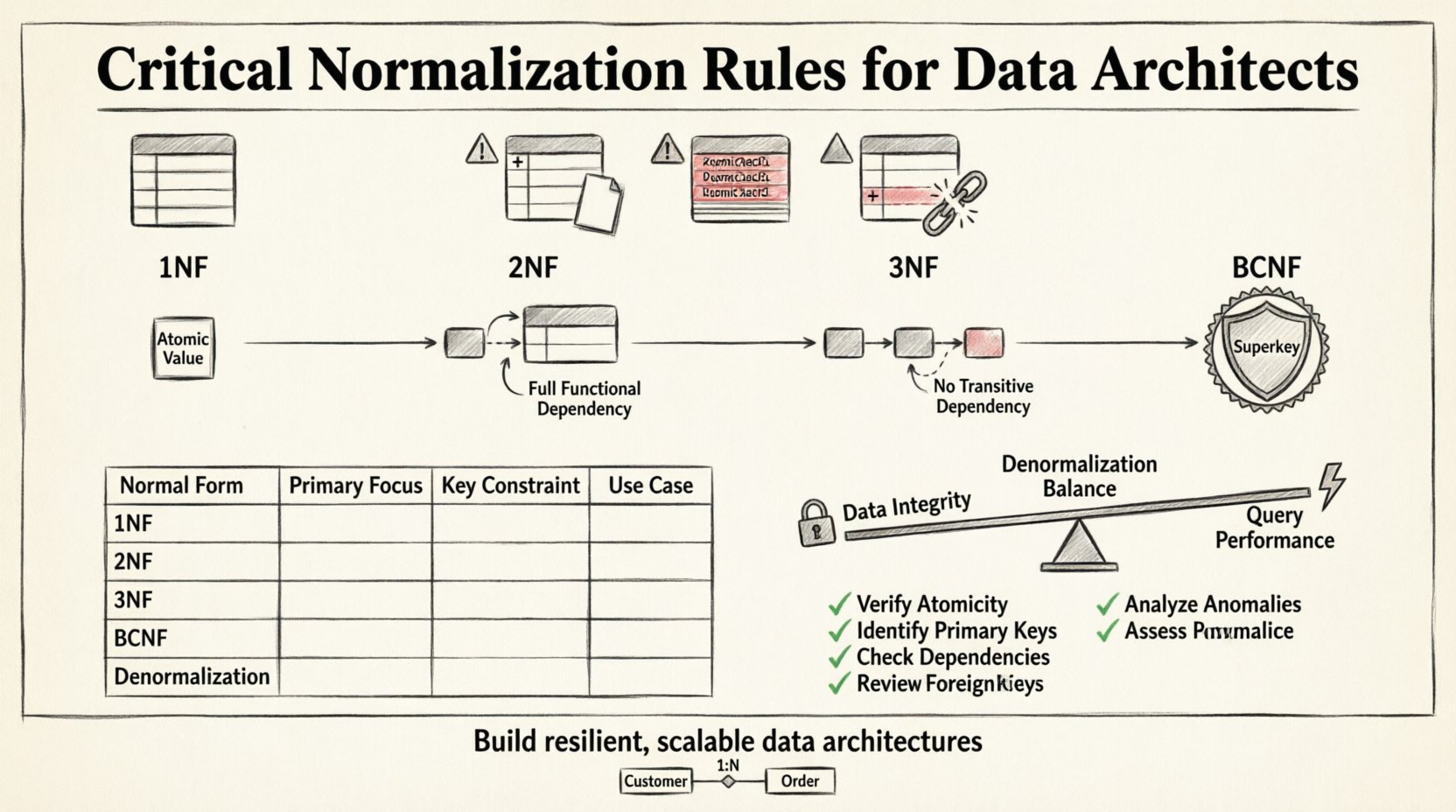
La fondation : Première forme normale (1NF) 🧱
La première étape de la normalisation consiste à atteindre la Première Forme Normale. Il s’agit du critère de base pour toute base de données relationnelle. Une table est en 1NF si elle satisfait deux conditions : elle ne contient que des valeurs atomiques, et chaque colonne ne contient qu’une seule valeur par ligne. Il ne doit pas y avoir de groupes répétés ou de tableaux dans une seule cellule.
Les violations de la 1NF surviennent souvent lorsque les développeurs tentent de stocker des listes dans une seule colonne, par exemple en stockant plusieurs numéros de téléphone dans un champ unique séparés par des virgules. Cette approche complique la requête et l’indexation. À la place, chaque élément de données doit exister dans sa propre ligne.
-
Atomicité : Assurez-vous que chaque colonne contient une seule valeur indivisible.
-
Lignes uniques : Chaque ligne doit être unique, souvent assurée par une clé primaire.
-
Ordre des colonnes : L’ordre des colonnes ne doit pas affecter le sens des données.
Prenons l’exemple d’une table client. Si un client possède trois adresses e-mail, ne créez pas trois colonnes e-mail. Créez une table distincte « Email » liée par une clé étrangère. Cette structure garantit qu’ajouter un quatrième e-mail ne nécessite pas de modifier le schéma de la table.
Élimination des dépendances partielles (2NF) ⚖️
Une fois qu’une table est en 1NF, la prochaine étape consiste à vérifier les dépendances partielles. Une table est en Deuxième Forme Normale si elle est déjà en 1NF et que chaque attribut non clé dépend entièrement de la clé primaire. Cette règle devient particulièrement pertinente lorsqu’on traite des clés primaires composées.
Une clé primaire composée est constituée de deux ou plusieurs colonnes. Dans ce cas, une dépendance partielle survient si un attribut non clé dépend uniquement d’une partie de la clé composée. Par exemple, dans une table suivant les articles de commande où la clé primaire est (OrderID, ProductID), une colonne pour « NomProduit » pourrait dépendre uniquement de « ProductID », et non de la combinaison des deux.
-
Dépendance complète : Assurez-vous que chaque champ non clé dépend de toute la clé primaire.
-
Séparation des préoccupations : Déplacez les attributs qui dépendent d’un sous-ensemble de la clé vers une nouvelle table.
-
Vérifications d’intégrité : Vérifiez qu’aucun attribut ne peut être déduit sans la clé complète.
En déplaçant « ProductName » dans sa propre table liée par « ProductID », vous éliminez le risque que le nom change dans une commande mais pas dans une autre. Cela réduit l’espace de stockage nécessaire et assure la cohérence dans toutes les lignes de commandes.
Suppression des dépendances transitives (3NF) 🔗
La Troisième Forme Normale approfondit la structure en traitant les dépendances transitives. Une table est en 3NF si elle est en 2NF et que tous les attributs non clés sont dépendants de manière non transitive de la clé primaire. En substance, cela signifie que les colonnes non clés ne doivent pas dépendre d’autres colonnes non clés.
Imaginez une table comportant EmployeeID, EmployeeName, DepartmentID et DepartmentName. Si EmployeeName détermine DepartmentName, vous avez une dépendance transitive. Si un employé change de département, le DepartmentName dans la table des employés pourrait devenir obsolète si la mise à jour n’est pas correcte. Pour corriger cela, la table Department doit être séparée.
-
Dépendances directes uniquement :Les attributs doivent dépendre directement de la clé, et non d’autres attributs.
-
Regroupement logique :Regroupez les attributs liés qui partagent un déterminant commun dans leurs propres entités.
-
Clés étrangères :Utilisez les clés étrangères pour relier les tables séparées.
Cette séparation garantit que les informations sur le département sont stockées une seule fois. Si le nom du département change, il est mis à jour à un seul endroit, et tous les enregistrements d’employés reflètent automatiquement ce changement grâce à la relation.
Quand la 3NF n’est pas suffisante : BCNF et au-delà 🚀
Bien que la 3NF couvre la plupart des scénarios standards de conception, il existe des cas limites où la 3NF stricte est insuffisante. La Forme Normale de Boyce-Codd (BCNF) est une version plus stricte de la 3NF, qui traite les cas où il existe plusieurs clés candidates. La BCNF exige que pour toute dépendance fonctionnelle X → Y, X soit une superclé.
Considérez un scénario où un étudiant peut avoir plusieurs enseignants, et un enseignant peut enseigner plusieurs matières. Si la clé primaire est (Étudiant, Matière), et qu’un enseignant est attribué en fonction de la matière, vous pouvez rencontrer des situations où la logique de dépendance se chevauche de manière complexe. La BCNF garantit qu’aucune colonne n’est déterminée par un ensemble de colonnes qui n’est pas une clé candidate.
-
Exigence de superclé : Le déterminant dans toute dépendance doit être une superclé.
-
Relations complexes :Gérez les relations many-to-many à l’aide de tables intermédiaires.
-
Considération du surcoût :Les formes normales supérieures peuvent augmenter la complexité des jointures.
La Quatrième Forme Normale (4NF) et la Cinquième Forme Normale (5NF) traitent des dépendances multivaluées et des dépendances de jointure. Ce sont des cas rares dans les applications commerciales générales, mais essentiels dans le stockage spécialisé de données ou la modélisation scientifique des données.
L’art de la dénormalisation stratégique ⚡
La normalisation n’est pas toujours l’objectif final. Dans certains environnements à haute performance, une normalisation stricte peut entraîner des jointures excessives qui ralentissent les requêtes. C’est là que la dénormalisation stratégique entre en jeu. La dénormalisation consiste à ajouter des données redondantes à une base de données afin d’optimiser les performances de lecture.
Toutefois, cela ne doit jamais être fait de manière arbitraire. Cela exige une compréhension claire des compromis entre la vitesse de lecture et la complexité des écritures. Lorsque les opérations de lecture dominent largement les opérations d’écriture, la redondance peut être justifiée.
-
Charge de travail orientée lecture :Si le reporting est la fonction principale, la dénormalisation peut réduire le temps de requête.
-
Niveaux de mise en cache :Utilisez la mise en cache au niveau de l’application avant de modifier le schéma.
-
Risques de cohérence des données : Soyez conscient que les données redondantes peuvent s’éloigner du synchronisme.
-
Pénalités d’écriture : Chaque opération d’écriture doit mettre à jour toutes les copies redondantes des données.
Un schéma courant consiste à dénormaliser les tables de synthèse pour les tableaux de bord de reporting tout en conservant les données transactionnelles principales en 3NF. Cette approche hybride équilibre l’intégrité et les performances.
Comparaison des formes normales
|
Forme normale |
Objectif principal |
Contrainte de clé |
Cas d’utilisation typique |
|---|---|---|---|
|
1FN |
Valeurs atomiques |
Pas de groupes répétés |
Conception initiale du schéma |
|
2FN |
Dépendance complète |
Pas de dépendances partielles sur les clés composées |
Clés complexes |
|
3FN |
Dépendance transitive |
Les attributs non clés dépendent uniquement de la clé |
Logique métier générale |
|
FNBC |
Superclés |
Le déterminant doit être une superclé |
Clés candidates complexes |
Une liste de contrôle pratique pour les architectes de données ✅
Pour vous assurer que votre MCD répond aux normes du secteur, passez en revue cette liste de contrôle pendant la phase de conception. Ce processus aide à identifier les problèmes potentiels avant l’écriture du code.
-
Vérifiez l’atomicité : Assurez-vous qu’aucune colonne ne contient plusieurs valeurs distinctes.
-
Identifiez les clés primaires : Confirmez que chaque table dispose d’un identifiant unique.
-
Vérifiez les dépendances : Établissez les relations entre chaque colonne et la clé primaire.
-
Revoyez les clés étrangères : Assurez-vous que les relations sont définies de manière explicite.
-
Analysez les anomalies : Simulez mentalement les opérations d’insertion, de mise à jour et de suppression.
-
Évaluez les performances : Déterminez si la 3NF est suffisante ou si une dénormalisation est nécessaire.
-
Documentez les contraintes : Définissez clairement les règles d’entrée et de validation des données.
-
Prévoyez la croissance : Pensez à la manière dont le schéma gérera une augmentation du volume de données.
En suivant ces étapes, vous créez un schéma résilient aux changements. L’architecture des données n’est pas statique ; elle évolue avec les besoins métiers. Une base bien normalisée facilite cette évolution, car les modifications apportées à une partie du système ne se propagent pas de manière imprévisible dans le reste.
Souvenez-vous que la normalisation est un outil, pas une loi. Bien que la 3NF soit la norme pour les systèmes transactionnels, les besoins spécifiques de votre application pourraient justifier des écarts. L’objectif est toujours l’intégrité des données et l’efficacité du système. Équilibrez soigneusement ces deux facteurs, et votre MCD servira de fondation solide à l’ensemble de l’écosystème applicatif.
Adopter ces règles fondamentales de normalisation vous permet de construire des systèmes qui sont non seulement fonctionnels aujourd’hui, mais aussi adaptables à l’avenir. Concentrez-vous sur les relations entre les points de données, et la structure suivra naturellement.