











Concevoir un schéma de base de données est rarement un choix binaire entre vitesse et structure. C’est un exercice de compromis. Lorsque les architectes conçoivent des diagrammes Entité-Relation (ERD), ils sont souvent confrontés à la tension entre une intégrité des données stricte et la vitesse brute nécessaire aux applications à fort volume. La normalisation minimise la redondance, garantissant que les données restent cohérentes. Toutefois, le coût de maintien de cette cohérence est souvent payé en performances de lecture.
Cet article explore les subtilités techniques de cet équilibre. Nous examinerons comment la normalisation affecte les jointures, comment les charges de travail intensives en lecture dictent les modifications du schéma, et où se situe la frontière entre une base de données bien structurée et une base performante.
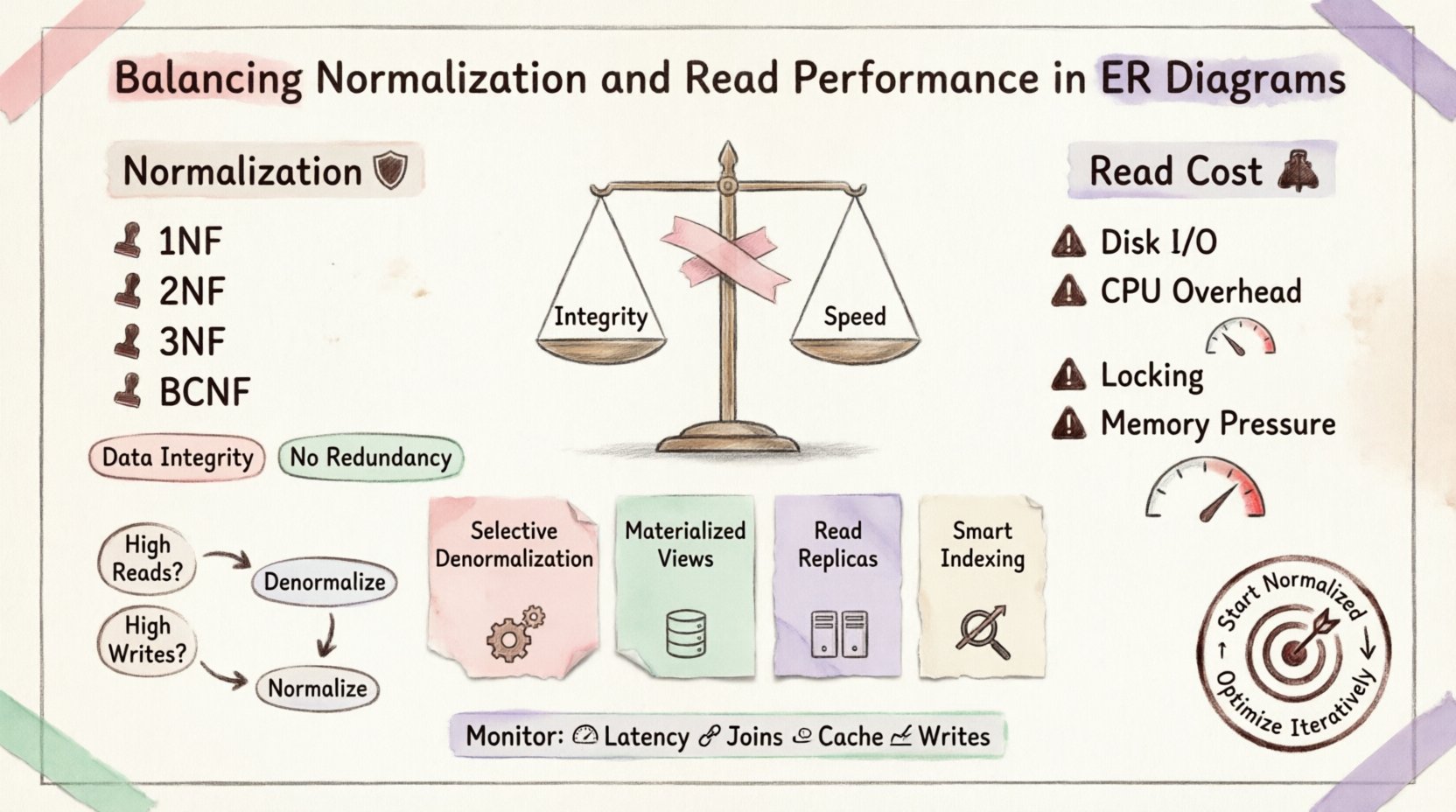
Comprendre la normalisation : la fondation 🛡️
La normalisation est le processus d’organisation des données afin de réduire la redondance et d’améliorer l’intégrité des données. Elle consiste à diviser de grandes tables en tables plus petites et logiques, et à définir des relations entre elles. L’objectif est d’éliminer les anomalies lors des opérations d’insertion, de mise à jour et de suppression.
Formes normales clés
-
Première forme normale (1NF) : Assure l’atomicité. Chaque colonne contient une seule valeur. Aucun groupe répétitif.
-
Deuxième forme normale (2NF) : S’appuie sur la 1NF. Toutes les attributs non clés doivent dépendre entièrement de la clé primaire. Élimine les dépendances partielles.
-
Troisième forme normale (3NF) : S’appuie sur la 2NF. Élimine les dépendances transitives. Les attributs non clés dépendent uniquement de la clé, de la clé entière, et rien d’autre que la clé.
-
Forme normale de Boyce-Codd (BCNF) : Une version plus stricte de la 3NF pour traiter des anomalies de dépendance spécifiques.
Bien que le respect de ces formes garantisse une base de données propre, il introduit une complexité dans les requêtes. Chaque relation définie dans le diagramme ER devient une opération de jointure potentielle.
Le coût des lectures 💸
Lorsque vous normalisez les données, vous divisez souvent l’information sur plusieurs tables. Pour récupérer un enregistrement complet, le moteur de base de données doit effectuer des opérations de jointure. Les jointures sont coûteuses en termes de calcul.
Pourquoi les jointures ralentissent les requêtes
-
E/S disque : Si les tables ne sont pas parfaitement indexées ou mises en cache, le moteur doit rechercher les données à travers différentes localisations physiques du disque.
-
Surcharge du CPU : La base de données doit correspondre les clés d’une table à celles d’une autre. Cela nécessite une puissance de traitement importante.
-
Contestation de verrouillage : Les jointures complexes peuvent maintenir les verrous plus longtemps, bloquant d’autres transactions dans l’accès aux données associées.
-
Pression mémoire : Les opérations de jointure importantes nécessitent des tampons mémoire importants pour trier et hacher les données.
Dans un environnement intensif en lectures, tel qu’un tableau de bord de reporting ou une API publique, cette latence est inacceptable. Les utilisateurs s’attendent à une réponse instantanée. Une requête qui prend 100 millisecondes pour retourner des données normalisées pourrait ne prendre que 10 millisecondes si les données étaient dénormalisées.
Stratégies d’optimisation 🚀
Pour équilibrer l’intégrité et la vitesse, les architectes utilisent des modèles spécifiques. Ces stratégies vous permettent de maintenir la base de données normalisée là où cela compte le plus, tout en optimisant les lectures là où cela fait la différence.
1. Dénormalisation sélective
Toutes les tables n’ont pas besoin d’être entièrement normalisées. Identifiez les données les plus fréquemment consultées et stockez-les de manière redondante. Par exemple, si vous interrogez fréquemment les noms d’utilisateurs accompagnés de leur historique de commandes, le stockage du nom d’utilisateur directement dans la table des commandes évite une jointure.
2. Vues matérialisées
Une vue matérialisée stocke physiquement sur le disque le résultat d’une requête. Elle est essentiellement un tableau prédéterminé. Lorsque les données changent, la vue doit être actualisée. Cela convient parfaitement aux agrégations complexes qui n’ont pas besoin d’une précision en temps réel.
3. Réplicas de lecture
Séparez la charge de lecture de la charge d’écriture. Dirigez toutes les opérations d’écriture vers la base de données principale, qui reste normalisée. Dirigez toutes les opérations de lecture vers une réplique. Cela permet à la réplique d’être optimisée différemment, par exemple avec plus d’index ou des structures dénormalisées, sans compromettre l’intégrité transactionnelle.
4. Stratégie d’indexation
Même les bases de données normalisées peuvent bien performer avec les bons index. Les index couvrants permettent à la base de données de satisfaire une requête en utilisant uniquement l’index, évitant ainsi les recherches dans les tables. Les index composés peuvent accélérer les jointures sur des clés étrangères fréquentes.
Quand dénormaliser 📉
La dénormalisation est une décision réfléchie, et non un état par défaut. Elle doit être prise sur la base de preuves provenant du suivi des performances, et non sur des hypothèses.
|
Scénario |
Approche |
Raisonnement |
|---|---|---|
|
Fréquence élevée d’écriture |
Garder normalisé |
Les mises à jour sont plus rapides. Moins de redondance à maintenir. |
|
Fréquence élevée de lecture |
Considérer la dénormalisation |
Réduit les jointures. Temps de récupération plus rapide. |
|
La cohérence des données est critique |
Garder normalisé |
Une seule source de vérité empêche le décalage des données. |
|
Reporting et analyse |
Dénormaliser |
Les agrégations sont complexes ; le calcul préalable aide. |
|
Besoin de scalabilité |
Approche hybride |
Séparez les services ou utilisez des couches de mise en cache. |
Le compromis : intégrité des données vs vitesse ⚙️
À chaque fois que vous introduisez une redondance, vous risquez une incohérence des données. Si un utilisateur change son adresse e-mail, mais que l’e-mail est stocké à la fois dans le Utilisateurs table et le Notifications table, une mise à jour pourrait échouer ou être manquée. Cela est connu comme un anomalie de mise à jour.
Pour atténuer cela, la logique d’application doit être robuste. Les déclencheurs peuvent assurer la cohérence, mais ils ajoutent de la complexité. En alternative, concevez le schéma de sorte que les données dénormalisées soient dérivées et immuables, réduisant ainsi le risque de divergence.
Gestion de la cohérence
-
Logique au niveau de l’application : Écrivez du code qui met à jour toutes les copies redondantes de manière atomique.
-
Déclencheurs de base de données : Laissez la base de données appliquer les règles automatiquement. Cela garde la logique proche des données.
-
Cohérence éventuelle : Acceptez que les données puissent être obsolètes pendant une courte période. Utilisez des tâches en arrière-plan pour synchroniser les données redondantes.
Surveillance et maintenance 🔧
Un design statique ne tient pas compte des évolutions des modèles d’utilisation. Ce qui fonctionne aujourd’hui pourrait devenir un goulot d’étranglement l’année prochaine. La surveillance continue est essentielle.
Indicateurs clés à surveiller
-
Latence des requêtes : Surveillez le temps nécessaire pour les requêtes de lecture critiques.
-
Nombre de jointures : Suivez le nombre de jointures par requête complexe.
-
Taux de succès du cache : Si vous utilisez le cache, vérifiez s’il réduit efficacement la charge de la base de données.
-
Latence des écritures : Assurez-vous que la dénormalisation n’a pas trop ralenti les écritures.
Conclusion : Une décision contextuelle 🎯
Il n’existe pas de standard universel pour la conception de base de données. Le meilleur schéma ER est celui qui correspond à votre charge de travail spécifique. La normalisation assure la sécurité ; la dénormalisation assure la vitesse. L’objectif est de trouver le point d’équilibre.
Commencez par un design normalisé pour garantir l’intégrité des données. Lorsque des goulets d’étranglement de performance apparaissent, identifiez les requêtes spécifiques causant des délais. Appliquez la dénormalisation ou le cache uniquement à ces zones. Cette approche itérative évite l’optimisation prématurée et garantit que le système reste maintenable dans le temps.
Souvenez-vous que la technologie évolue. De nouveaux moteurs de stockage et optimiseurs de requêtes continuent de réduire le coût des jointures. Revoyez régulièrement votre schéma à la lumière des capacités actuelles. L’équilibre évolue, et votre conception doit évoluer avec lui.
En comprenant les mécanismes de normalisation et les réalités de la performance de lecture, vous pouvez construire des systèmes à la fois robustes et réactifs. Concentrez-vous sur les données, et non seulement sur le code.