











Concevoir des schémas de bases de données robustes exige une compréhension approfondie de la manière dont les entités de données interagissent. Parmi les structures les plus complexes à gérer figurent les relations many-to-many. Ces scénarios surviennent lorsque plusieurs instances d’une entité sont associées à une seule instance d’une autre entité, et inversement. Sans une planification adéquate, ces connexions peuvent entraîner une redondance de données, des problèmes d’intégrité et des goulets d’étranglement significatifs en performance. Ce guide explore les mécanismes d’optimisation de ces relations au sein des modèles d’entités et de relations (ERMs) afin de garantir des systèmes évolutifs et maintenables.
Comprendre le défi fondamental 🔍
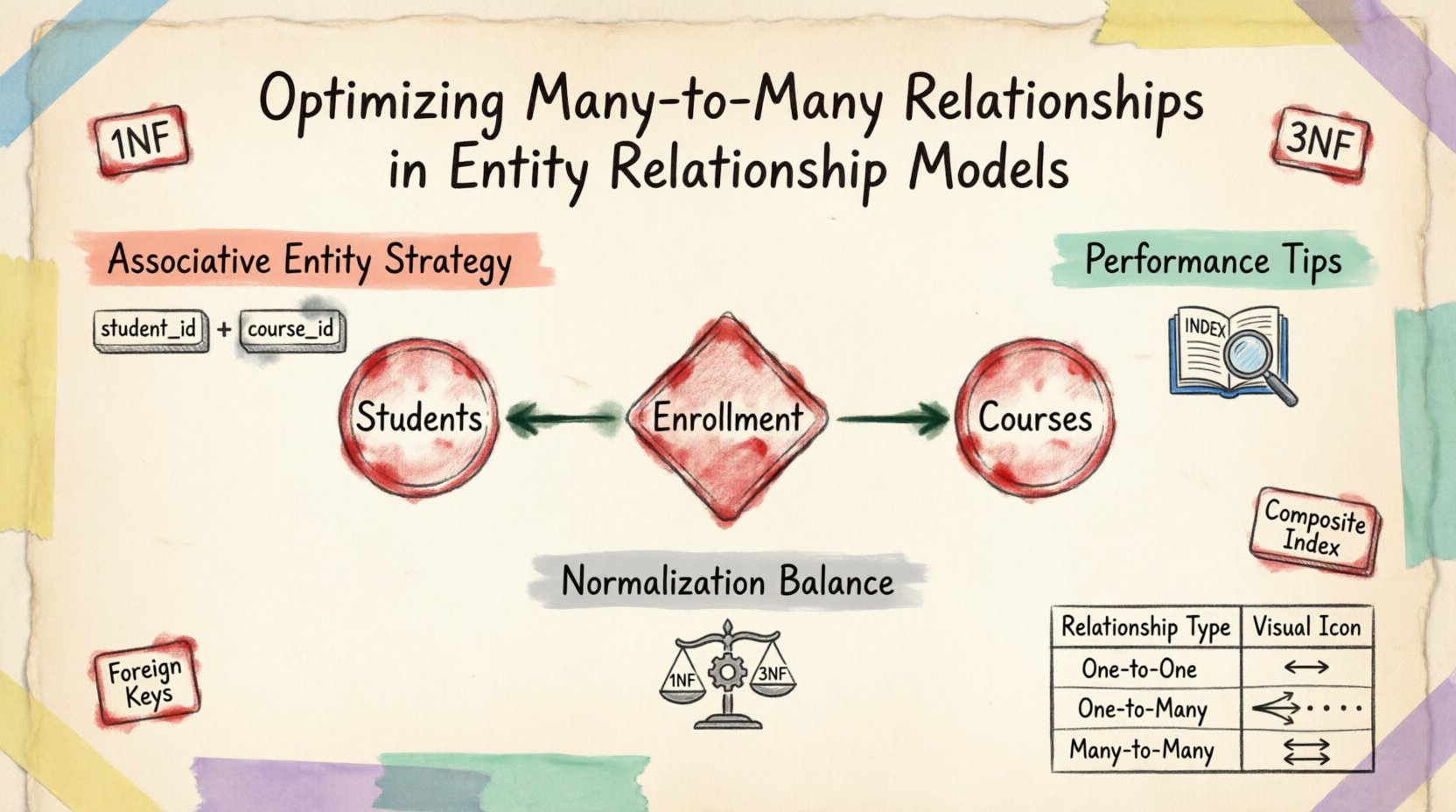
Dans un modèle conceptuel, une relation many-to-many est intuitive. Pensez aux étudiants et aux cours. Un étudiant s’inscrit à plusieurs cours, et chaque cours compte plusieurs étudiants. Représenter cela directement dans une structure physique de base de données pose problème. Les tables relationnelles standards supportent nativement les relations one-to-many et one-to-one grâce aux clés étrangères. Une relation many-to-many nécessite une structure intermédiaire pour fonctionner correctement.
Tenter de stocker plusieurs identifiants dans une seule colonne (par exemple, une liste séparée par des virgules) viole la Première Forme Normale (1NF). Cette approche rend presque impossible la requête, l’indexation et le maintien de l’intégrité des données. La solution réside dans la fragmentation de la relation en deux relations one-to-many via une entité associative, souvent appelée table d’association ou table de pont.
La stratégie de l’entité associative 🧩
La technique fondamentale pour résoudre les relations many-to-many consiste à introduire une entité associative. Cette entité agit comme un pont entre les deux tables parentes. Elle contient les clés primaires des deux entités parentes sous forme de clés étrangères, créant ainsi une clé primaire composée qui garantit l’unicité pour chaque instance de relation.
- Structure : La table contient des clés étrangères faisant référence aux clés primaires des entités associées.
- Unicité : Une clé composée empêche les relations en double entre les mêmes deux enregistrements.
- Attributs : Cette table peut stocker des données spécifiques concernant la relation elle-même, et non seulement les entités.
Prenons un scénario liant les employés et les projets. Un employé travaille sur plusieurs projets, et un projet compte plusieurs employés. La table de relation pourrait stocker la date d’affectation, le rôle de l’employé sur ce projet ou les heures attribuées. Ces attributs appartiennent à la relation, et non à l’employé ou au projet individuellement.
Étapes d’implémentation
- Identifier les entités : Définir les deux entités distinctes impliquées dans la relation.
- Créer la table d’association : Générer une nouvelle table avec un nom descriptif, tel que
Employe_Projet_Affectations. - Ajouter les clés étrangères : Insérer des colonnes pour les clés primaires des deux entités parentes.
- Définir les contraintes : Mettre en place des contraintes de clé étrangère pour assurer l’intégrité référentielle.
- Indexation : Appliquer des index aux colonnes de clés étrangères pour accélérer les opérations de jointure.
Normalisation et intégrité des données 🛡️
L’optimisation implique souvent un compromis entre la normalisation et les performances. Bien que la normalisation réduise la redondance, des structures trop normalisées peuvent nécessiter des jointures complexes qui ralentissent les requêtes. Lors de l’optimisation des relations many-to-many, il est crucial de trouver un équilibre entre ces facteurs.
La Troisième Forme Normale (3NF) est généralement l’objectif pour les bases de données opérationnelles. Dans cet état, la table d’association ne doit pas contenir de dépendances transitives. Chaque attribut non clé doit dépendre de la clé primaire. Si une table d’association contient des données qui dépendent uniquement d’une des clés étrangères, elle doit être déplacée dans la table parente correspondante.
Péchés courants de la normalisation
- Clés étrangères redondantes :Inclure la même clé étrangère dans plusieurs tables de jonction sans hiérarchie claire.
- Contraintes manquantes :Ne pas appliquer de contraintes uniques sur la combinaison des clés étrangères.
- Suppressions douces :Ne pas tenir compte des enregistrements supprimés dans la table de relation, ce qui entraîne des données orphelines.
Stratégies d’optimisation des performances ⚡
À mesure que le volume de données augmente, le nombre de lignes dans une table de jonction peut croître de manière exponentielle. Cela affecte directement les temps d’exécution des requêtes. Plusieurs stratégies peuvent atténuer la dégradation des performances.
1. Indexation stratégique
Les index sont essentiels pour les performances des jointures. Un index composite sur les colonnes de clés étrangères est souvent plus efficace que des index individuels. Cela permet au moteur de base de données de localiser plus rapidement les lignes associées sans scanner toute la table.
- Index clusterisés :Dans certains systèmes, le regroupement de la table par la clé composite peut améliorer les requêtes sur plage.
- Index couvrants :Inclure les colonnes fréquemment interrogées dans l’index peut éliminer la nécessité d’accéder au tas de la table.
2. Partitionnement
Lorsqu’une table de jonction devient trop grande pour être gérée efficacement, le partitionnement par date ou région peut répartir la charge. Cela est particulièrement utile pour les données historiques où les relations récentes sont plus fréquemment consultées que les anciennes.
3. Optimisation des requêtes
Les requêtes complexes impliquant plusieurs jointures peuvent surcharger les ressources. Utiliser des indications de requête ou restructurer le SQL pour minimiser les sous-requêtes peut aider. Il est également important d’analyser le plan d’exécution pour identifier les goulets d’étranglement.
| Stratégie | Avantage | Compromis |
|---|---|---|
| Indexation composite | Récupération de jointure plus rapide | Augmentation de l’espace de stockage et de la charge d’écriture |
| Partitionnement de table | Amélioration de la maintenance et de la vitesse de balayage | Complexité dans la logique des requêtes |
| Mise en cache | Réduction de la charge de la base de données | Risques de cohérence des données |
Gestion des attributs de relation 📝
L’un des plus grands avantages de l’entité associative est la capacité à stocker des attributs spécifiques à la relation. Par exemple, dans un système de gestion de contrats, un Fournisseur et un Produit ont une relation many-to-many. Les attributs pourraient inclure le prix unitaire, la date de début du contrat et la quantité convenue.
Si vous tentez de stocker ces attributs dans la table Fournisseur ou Produit, vous créez une redondance. Si le prix change, vous devrez mettre à jour plusieurs lignes dans la table produit. En les plaçant dans la table de jonction, vous maintenez une source unique de vérité pour cette instance de relation spécifique.
Scénarios avancés et cas limites 🌐
La modélisation de données dans le monde réel présente souvent des défis uniques que les modèles standards ne couvrent pas immédiatement.
- Relations auto-référentielles : Une entité liée à elle-même (par exemple, un Employé gérant d’autres Employés). Cela nécessite une clé étrangère pointant vers la clé primaire de la même table.
- Suppressions en cascade : Déterminer si la suppression d’une entité parente doit supprimer automatiquement ses enregistrements de relation. Cela évite les clés étrangères orphelines, mais peut entraîner la perte de données historiques d’association.
- Relations récursives : Hiérarchies complexes où la table de jonction pointe vers elle-même.
Interrogation du schéma optimisé 🔎
Une fois le schéma optimisé, son interrogation nécessite une précision. Les développeurs doivent comprendre comment le moteur de base de données parcourt les chemins de jointure.
Lors de la récupération de données, telles que tous les projets pour un employé spécifique, la requête doit joindre la table Employé à la table de jonction, puis à la table Projet. Une écriture SQL efficace garantit que la base de données utilise correctement les index disponibles. Éviter les fonctions sur les colonnes indexées dans la clauseWHEREest une pratique standard pour maintenir l’utilisation des index.
Meilleures pratiques pour la logique de jointure
- Utilisez les jointures explicites :Préférez
INNER JOINouLEFT JOINaux tables implicites séparées par des virgules. - Limitez les colonnes :Sélectionnez uniquement les colonnes nécessaires pour réduire le transfert réseau et le temps de traitement.
- Filtrez tôt :Appliquez les filtres dans la clause
WHEREavant que la jointure ne se produise, si possible.
Comparaison des types de relations 📊
Comprendre où s’inscrit le type de relation plusieurs-à-plusieurs dans le contexte plus large de la modélisation des données aide à prendre de meilleures décisions de conception.
| Type de relation | Structure | Exemple de cas d’utilisation |
|---|---|---|
| Un-à-un | Clé étrangère unique | Profil utilisateur et paramètres utilisateur |
| Un-à-plusieurs | Clé étrangère unique | Commande et éléments de commande |
| Plusieurs-à-plusieurs | Table d’association | Étudiants et cours |
Maintien de la cohérence des données 🔄
Assurer que les données restent cohérentes entre les tables liées est primordial. Cela implique souvent la gestion des transactions. Une transaction doit englober l’insertion des données dans la table parente et dans la table d’association. Si l’une des étapes échoue, toute l’opération doit être annulée pour éviter des états partiels des données.
Les déclencheurs peuvent également être utilisés pour imposer la logique métier, bien qu’ils doivent être utilisés avec parcimonie afin d’éviter des coûts de performance cachés. Par exemple, un déclencheur pourrait empêcher un employé d’être affecté à un projet si son département ne correspond pas à celui du projet.
Surveillance et maintenance 📈
Une fois déployé, le système nécessite une surveillance continue. Une croissance de la table d’association est souvent le premier signe de problèmes d’évolutivité. Des audits réguliers des tailles des tables, de la fragmentation des index et des métriques de performance des requêtes sont nécessaires.
- Archivage : Déplacer les données historiques de relation vers un stockage froid si elles ne sont plus activement interrogées.
- Réindexation : Reconstruire ou réorganiser périodiquement les index pour maintenir des performances optimales.
- Examen des jointures : S’assurer que les modifications de l’application n’introduisent pas de modèles de requêtes inefficaces.
Réflexions finales sur la conception du schéma 🎯
Optimiser les relations plusieurs-à-plusieurs n’est pas une tâche ponctuelle, mais un processus continu d’amélioration. Cela exige un équilibre entre la correction théorique et les performances pratiques. En respectant les principes de normalisation, en utilisant des entités associatives et en appliquant un indexage stratégique, les architectes de bases de données peuvent concevoir des systèmes à la fois robustes et efficaces. L’objectif est de créer une structure qui soutient la logique métier sans imposer de contraintes inutiles à la récupération ou à la modification des données.