











Concevoir une architecture de données robuste exige bien plus que de dessiner des boîtes et des lignes. Il demande une compréhension approfondie de la manière dont les données circulent, croissent et interagissent au fil du temps. Lorsqu’un système évolue, le modèle de relation entre entités (ERD) sert de plan directeur pour la cohérence logique, tandis que les stratégies de partitionnement traitent de la performance physique. Aligner ces deux aspects est crucial pour maintenir la vitesse des requêtes, l’intégrité des données et l’efficacité opérationnelle. Ce guide explore comment harmoniser les techniques de partitionnement avec vos modèles de données existants sans introduire de complexité ou de risque inutiles.
🧩 La fondation : l’ERD comme plan directeur
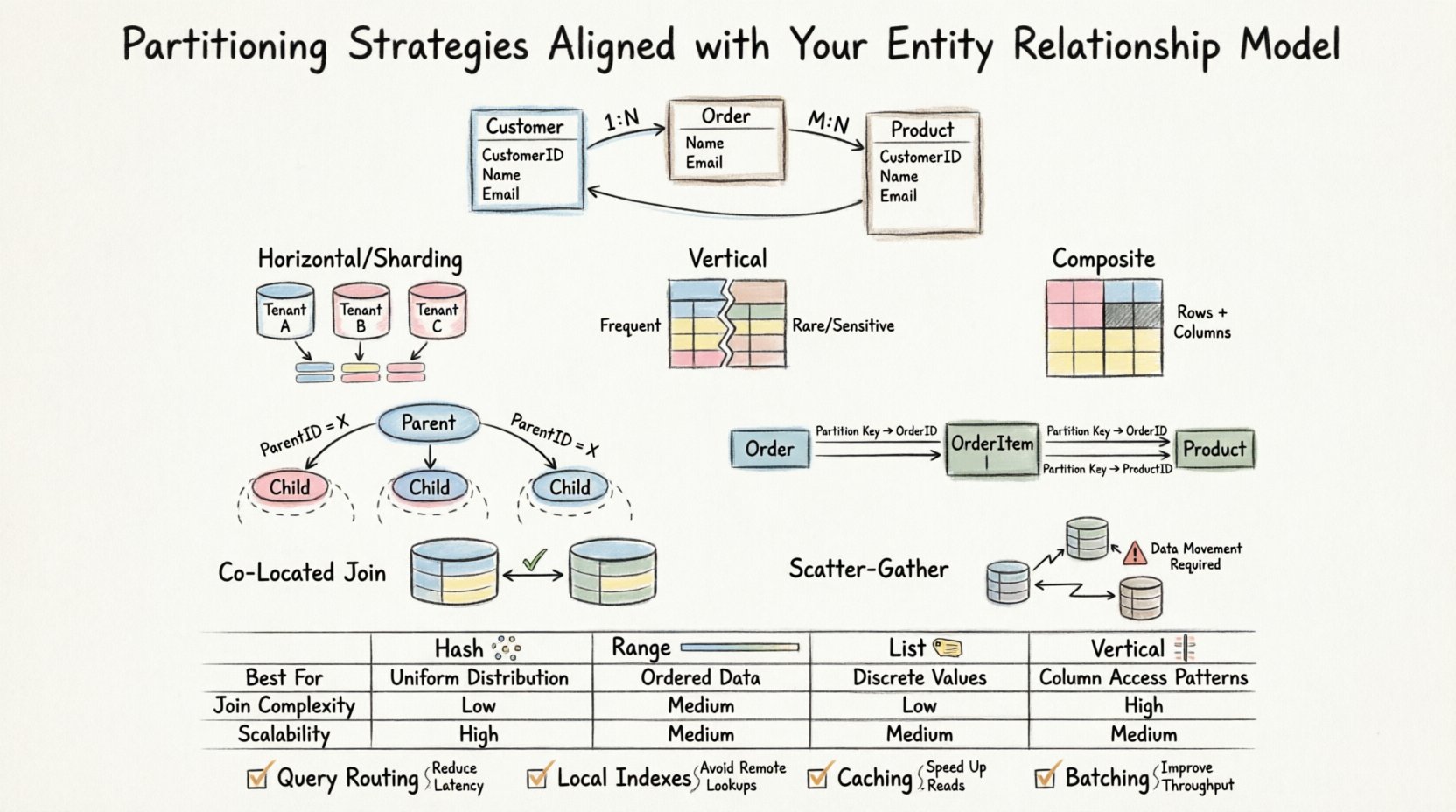
Avant de considérer la manière de diviser les données, il faut comprendre les relations qui les lient. Un ERD définit les entités, les attributs et la cardinalité entre eux. Ces relations déterminent la manière dont les données sont récupérées et jointes. Lorsque vous introduisez le partitionnement, vous répartissez essentiellement ces relations logiques sur des limites physiques de stockage.
Pensez aux implications suivantes du partitionnement sur votre schéma :
- Clés primaires : Doivent être soigneusement choisies pour assurer une répartition équitable sur les partitions.
- Clés étrangères :Joindre des tables situées dans des partitions différentes peut entraîner un surcroît important de charge.
- Index :Les index globaux peuvent devenir des goulets d’étranglement si leur conception ne tient pas compte de la clé de partitionnement.
- Localisation des données :Les données liées devraient idéalement résider sur le même nœud afin de minimiser la latence réseau.
Ignorer ces facteurs peut conduire à une situation où le modèle logique fonctionne parfaitement en théorie, mais où l’implémentation physique peine sous charge. L’objectif est de garder les données liées proches les unes des autres tout en permettant une croissance indépendante.
🔄 Types de partitionnement et adaptation au schéma
Différentes méthodes de partitionnement conviennent à différents schémas d’accès aux données. Le choix de la bonne méthode dépend fortement de la manière dont votre ERD définit les relations et des modèles de requêtes attendus. Ci-dessous, une analyse des stratégies courantes et de leur interaction avec les structures relationnelles.
Partitionnement horizontal (sharding)
Le partitionnement horizontal divise les lignes d’une table en groupes différents. Cela est souvent utilisé lorsque les tables deviennent trop grandes pour être gérées dans une seule instance. Dans le cadre d’un ERD, cette stratégie fonctionne le mieux lorsque la clé de partitionnement est corrélée au schéma d’accès naturel.
- Cas d’utilisation :Grandes tables transactionnelles avec des groupes d’utilisateurs ou de locataires distincts.
- Impact sur l’ERD :Les clés étrangères pointant vers une table parente doivent être gérées avec soin. Si la table parente est également partitionnée, les clés doivent être alignées.
- Avantage :Permet un agrandissement massif en ajoutant plus de nœuds.
- Défi :Les requêtes complexes qui s’étendent sur plusieurs partitions nécessitent une logique d’agrégation.
Partitionnement vertical
Le partitionnement vertical divise les colonnes d’une table en groupes différents. Cela est utile lorsque des colonnes spécifiques sont rarement accédées ensemble ou lorsque des données sensibles doivent être isolées.
- Cas d’utilisation :Tables avec des lignes larges où seul un sous-ensemble de colonnes est fréquemment interrogé.
- Impact sur le MCD : La clé primaire doit exister sur toutes les partitions verticales afin de permettre la reconstruction de la ligne complète.
- Avantage :Réduit les E/S en ne chargeant en mémoire que les colonnes nécessaires.
- Défi :Des jointures sont nécessaires pour reconstruire l’entité complète, ce qui ajoute de la complexité aux requêtes.
Partitionnement composé
Cette approche combine des stratégies horizontales et verticales. Elle est souvent nécessaire pour les systèmes à haute performance où le volume de lignes et la largeur des colonnes constituent des contraintes importantes.
- Cas d’utilisation :Entreposage de données ou journaux de trading à haute fréquence.
- Impact sur le MCD :Exige une définition rigide du schéma avant mise en œuvre.
🔑 Alignement des clés avec les relations
La étape la plus critique dans ce processus consiste à sélectionner la clé de partition. Cette clé détermine quelle ligne est affectée à quel unité de stockage physique. Dans un contexte relationnel, la clé de partition devrait idéalement correspondre aux relations de clé étrangère.
Relations parent-enfant
Lorsqu’on traite des relations un-à-plusieurs, la table enfant grandit souvent beaucoup plus vite que la table parente. Si vous partitionnez la table enfant par l’ID du parent, tous les enregistrements enfants associés se trouvent sur le même nœud.
- Avantage :Les requêtes récupérant le parent et tous les enfants n’exigent aucune communication entre nœuds.
- Avantage :Les suppressions en cascade s’effectuent efficacement au sein d’une seule partition.
- Attention : Si un parent possède nettement plus d’enfants que les autres, un déséquilibre des données peut survenir.
Relations plusieurs-à-plusieurs
Les relations plusieurs-à-plusieurs impliquent généralement une table de jonction. Cette table peut devenir un goulot d’étranglement des performances si elle n’est pas correctement partitionnée.
- Stratégie :Partitionner par l’une des clés étrangères impliquées.
- Stratégie :Assurez-vous que les requêtes filtrent toujours par la clé de partition afin d’éviter les analyses de table entière.
- Stratégie :Évitez de joindre les tables de jonction sur plusieurs partitions, sauf si absolument nécessaire.
⚖️ Gestion des opérations de jointure
Les jointures sont le sang des bases de données relationnelles, mais elles deviennent coûteuses lorsque les données sont divisées. Comprendre le comportement des jointures à travers les partitions est essentiel pour maintenir les performances.
Partitions co-localisées
Si la table A et la table B sont partitionnées par la même clé (par exemple, Tenant_ID), la jointure entre elles s’effectue localement. Le moteur de base de données n’a pas besoin de déplacer les données entre les nœuds.
- Exigence :Les deux tables doivent utiliser le même algorithme de partitionnement et la même clé.
- Exigence :Le MCD doit supporter cette alignement de manière logique.
Jointures en diffusion-récupération
Lorsque les tables sont partitionnées différemment, le système doit récupérer des données depuis plusieurs nœuds, agréger les résultats, puis renvoyer l’ensemble final. Cela est connu sous le nom d’opération de diffusion-récupération.
- Coût de performance : Surcharge réseau élevée.
- Coût de performance : Latence accrue.
- Recommandation :Minimisez ces jointures pendant la phase de conception du MCD.
🛡️ Maintien de l’intégrité à travers les partitions
Les contraintes d’intégrité des données sont plus difficiles à appliquer lorsque les données sont distribuées. Le MCD définit ces règles de manière logique, mais l’implémentation doit gérer la distribution physique.
- Intégrité référentielle :S’assurer qu’un enregistrement enfant existe avant d’insérer un enregistrement parent est complexe si ces derniers résident sur des nœuds différents.
- Contraintes uniques :L’unicité globale nécessite une coordination entre toutes les partitions.
- Déclencheurs :Les déclencheurs au niveau de l’application remplacent souvent les déclencheurs au niveau de la base de données dans les environnements distribués afin d’éviter les problèmes de verrouillage.
- Transactions :Les transactions distribuées peuvent impacter le débit. Gardez les transactions locales à une seule partition chaque fois que possible.
📊 Comparaison des stratégies de partitionnement
Le tableau suivant résume la manière dont différentes stratégies interagissent avec des scénarios courants du MCD.
| Stratégie | Meilleur pour le scénario MCD | Complexité des jointures | Scalabilité des écritures |
|---|---|---|---|
| Partitionnement par hachage | Distribution uniforme requise, pas de plage spécifique | Élevée (distribution aléatoire) | Élevée |
| Partitionnement par plage | Identifiants basés sur la date ou séquentiels | Faible (si alignée) | Moyenne |
| Partitionnement par liste | Catégories fixes (par exemple, Région, Statut) | Faible (si alignée) | Élevée |
| Partitionnement vertical | Lignes larges, colonnes peu fréquentes | Moyenne (nécessite une reconstruction) | Élevée |
🔄 Évolution et migration
L’évolution du schéma est inévitable. Les exigences métier évoluent, et de nouveaux attributs sont ajoutés. Lors de la modification d’un MCD, la stratégie de partitionnement doit être revue.
- Ajout de colonnes :Le partitionnement vertical facilite l’ajout de colonnes, car elles peuvent être placées sur un nouveau partitionnement.
- Changement de clés :Le répartitionnement des données existantes est une opération lourde. Prévoyez cela dès la conception initiale.
- Archivage :Le partitionnement permet un archivage facile des anciennes plages de données sans affecter les partitions actives.
- Surveillance :Vérifiez régulièrement la taille des partitions pour vous assurer qu’aucune partition ne devienne un point de surcharge.
🚀 Astuces d’optimisation des performances
Pour garantir que le système reste réactif, des optimisations spécifiques doivent être appliquées en parallèle de la stratégie de partitionnement.
- Acheminement des requêtes : Assurez-vous que les applications envoient les requêtes vers le nœud de partition correct en fonction de la clé de partition.
- Indexation : Les index locaux sont plus rapides que les index globaux. Concevez les index pour qu’ils correspondent à la clé de partition.
- Mise en mémoire tampon : Les tables de recherche fréquemment utilisées ne doivent pas être partitionnées si elles sont suffisamment petites pour tenir en mémoire sur tous les nœuds.
- Regroupement : Regroupez les insertions et les mises à jour pour réduire la surcharge des transactions à travers les partitions.
🔍 Considérations finales
Construire un système évolutif exige un équilibre entre la clarté logique et les contraintes physiques. Le modèle Entité-Relation fournit les règles pour la cohérence des données, tandis que la partition permet la croissance. Lorsque ces deux éléments sont alignés, le système reste performant même lorsque le volume de données augmente de manière exponentielle.
Concentrez-vous sur les relations définies dans votre modèle. Si les données sont naturellement regroupées par un attribut spécifique, utilisez cet attribut comme clé de partition. Si les jointures sont fréquentes, assurez-vous que les tables associées partagent la même logique de partitionnement. Évitez de compliquer inutilement le schéma avec des partitions qui ne servent pas un objectif de performance clair.
En suivant ces principes, vous créez une base solide qui soutient la stabilité à long terme. L’objectif n’est pas seulement de stocker des données, mais de les structurer de manière à permettre à système d’adapter aux besoins futurs sans nécessiter un remaniement complet. Une planification soigneuse pendant la phase de conception permet d’économiser une quantité significative d’efforts ingénierie pendant les opérations.