











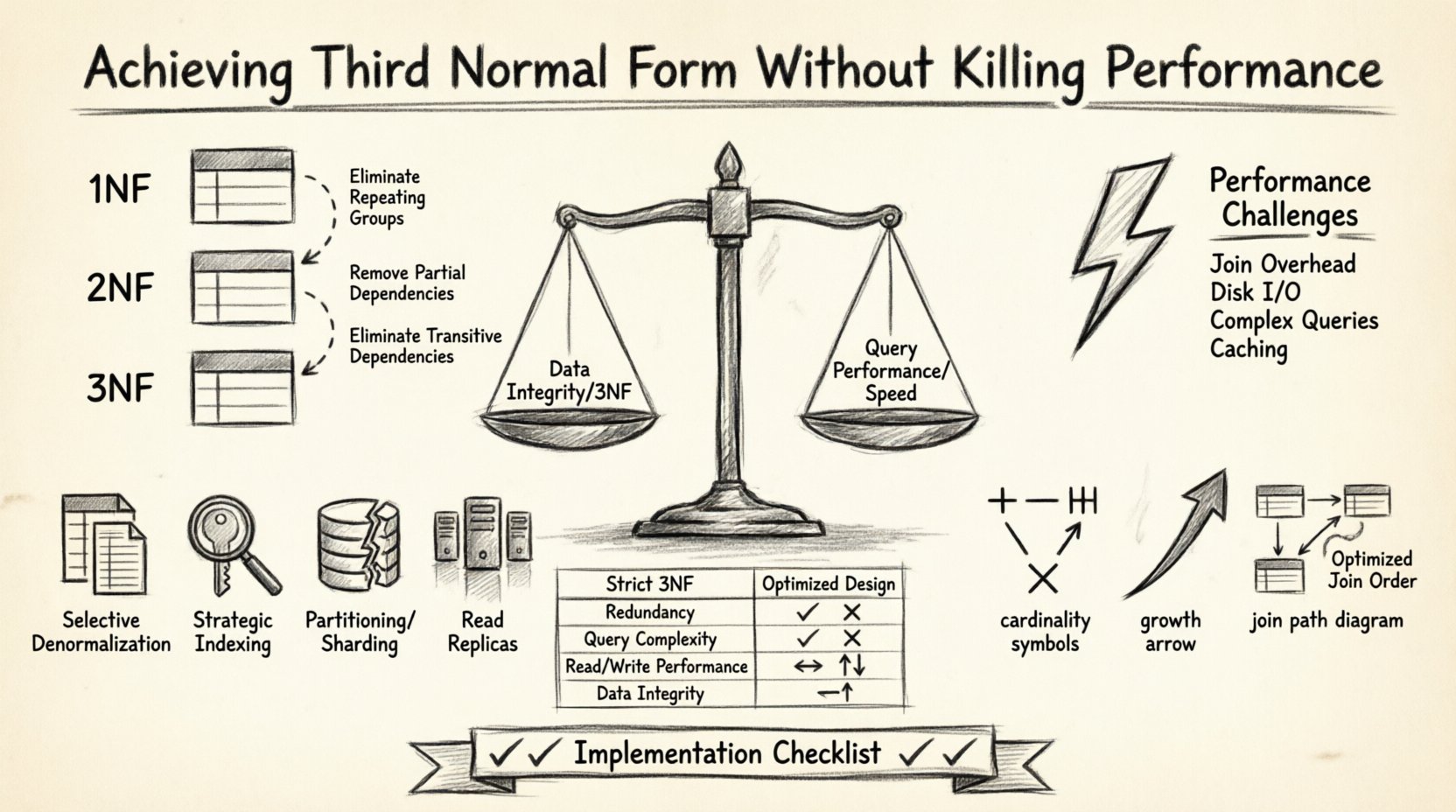
Concevoir une structure de base de données robuste est un exercice d’équilibre. D’un côté, on trouve l’intégrité des données et l’élimination de la redondance grâce à la normalisation. De l’autre, on a la vitesse des requêtes et la réactivité du système. De nombreux architectes de bases de données font face à un choix difficile : respecter strictement les règles de normalisation et risquer des requêtes lentes, ou dénormaliser de manière agressive et risquer des incohérences dans les données. L’objectif est de trouver un juste milieu où la base de données respecte la Troisième Forme Normale (3NF) tout en maintenant de hautes performances. Cet article explore comment structurer les diagrammes Entité-Relation (ERD) pour atteindre cet équilibre sans compromettre ni l’intégrité ni la vitesse.
Comprendre la Troisième Forme Normale 🧩
La Troisième Forme Normale est un niveau spécifique de normalisation des bases de données. Avant d’atteindre la 3NF, une table doit d’abord satisfaire la Première Forme Normale (1NF) et la Deuxième Forme Normale (2NF). Le principe fondamental de la 3NF est que tous les attributs doivent dépendre uniquement de la clé primaire. Il ne doit pas y avoir de dépendances transitives.
- Première Forme Normale : Élimine les groupes répétitifs et garantit des valeurs atomiques.
- Deuxième Forme Normale : Supprime les dépendances partielles où les attributs non clés dépendent uniquement d’une partie d’une clé composite.
- Troisième Forme Normale : Supprime les dépendances transitives. Si A détermine B, et que B détermine C, alors C ne doit pas dépendre directement de A dans la même table.
Lorsque vous atteignez la 3NF, vous minimisez les anomalies de mise à jour. Ce sont des erreurs qui surviennent lorsque les données sont modifiées en un endroit mais pas ailleurs, entraînant des incohérences. Par exemple, si l’adresse d’un client est stockée à la fois dans la table Commandes et dans la table Clients et dans la table Clients, modifier l’adresse dans une table mais pas dans l’autre crée une incohérence. La 3NF vous oblige à stocker cette adresse dans un seul endroit uniquement.
Le compromis de performance ⚡
Bien que la 3NF soit excellente pour l’intégrité des données, elle comporte souvent un coût en termes de performance. Les bases de données normalisées nécessitent généralement un plus grand nombre de tables. Pour récupérer un ensemble de données complet, le moteur de base de données doit effectuer plusieurs jointures. Chaque opération de jointure exige que le système lise les données depuis le disque ou la mémoire, corresponde les clés et combine les résultats.
Prenons une requête de reporting qui nécessite les noms des clients, les détails des commandes, les descriptions des produits et les adresses de livraison. Dans une conception 3NF entièrement normalisée, cela pourrait impliquer la jointure de cinq tables ou plus. Si le volume de données est important, ces jointures peuvent devenir un goulot d’étranglement.
Voici les défis spécifiques de performance associés à la 3NF :
- Surcharge accrue des jointures : Chaque relation nécessite une opération de jointure lors des requêtes de lecture.
- E/S disque :Répartir les données sur de nombreuses tables augmente le nombre de pages que le moteur de base de données doit accéder.
- Logique de requête complexe :Les applications doivent construire des instructions SQL plus complexes pour récupérer les données liées.
- Complexité du cache :Mettre en cache une seule ligne dénormalisée est plus simple que de mettre en cache plusieurs lignes liées.
Stratégies pour équilibrer intégrité et vitesse 🚀
Vous n’avez pas besoin d’abandonner la normalisation pour améliorer les performances. Il existe des techniques spécifiques pour optimiser une base de données 3NF tout en conservant sa structure intacte. Les stratégies suivantes aident à maintenir la qualité des données sans sacrifier la vitesse.
1. Dénormalisation sélective
Toutes les tables n’ont pas besoin d’être strictement en 3NF. Identifiez les tables fortement utilisées en lecture et les chemins critiques de données. Vous pouvez introduire une redondance contrôlée dans ces zones spécifiques. Par exemple, stockez directement le nom d’un client dans la Commandes table. Bien que cela duplique les données, l’amélioration des performances pour les recherches de commandes est significative. Vous devez ensuite mettre en place un déclencheur ou une logique d’application pour maintenir cette copie à jour lorsque le dossier client change.
2. Indexation stratégique
Les index sont l’outil principal pour accélérer les jointures. Sans index, une base de données effectue un balayage complet de la table pour chaque condition de jointure. Avec un indexage approprié, les recherches deviennent pratiquement instantanées.
- Index des clés étrangères : Indexez toujours les colonnes utilisées dans les relations de clés étrangères. Cela garantit que les jointures entre tables sont rapides.
- Index composés : Créez des index sur plusieurs colonnes si vos requêtes filtrent fréquemment par cette combinaison.
- Index couvrants : Concevez des index qui incluent toutes les colonnes nécessaires à une requête spécifique. Cela permet à la base de données de répondre à la requête en utilisant uniquement l’index, évitant ainsi une recherche dans les données principales de la table.
3. Partitionnement et fractionnement
Si l’ensemble de données devient trop volumineux, diviser les tables peut améliorer les performances. Le partitionnement divise une grande table en morceaux physiques plus petits et plus gérables, selon une clé, comme la date ou la région. Le fractionnement répartit les données sur plusieurs instances de base de données. Ces deux méthodes réduisent la quantité de données que le moteur doit scanner pour répondre à une requête spécifique.
4. Réplicas de lecture
Séparez vos opérations d’écriture de vos opérations de lecture. Utilisez une instance principale de base de données pour les transactions et les mises à jour. Répliquez ces données vers un ou plusieurs réplicas en lecture seule. Les requêtes complexes de reporting qui sollicitent le système peuvent s’exécuter sur les réplicas, maintenant le système principal rapide pour les interactions des utilisateurs.
Considérations pour la conception des diagrammes Entité-Relation 📐
Lors de la création d’un diagramme Entité-Relation, la représentation visuelle influence la manière dont les développeurs écrivent les requêtes. Un ERD clair aide à identifier les relations précocement. Toutefois, un diagramme qui semble parfait sur papier peut mal performer en production. Voici comment aborder la conception d’un ERD pour optimiser les performances.
- Identifiez clairement la cardinalité : Assurez-vous que chaque relation a une cardinalité définie (un à un, un à plusieurs, plusieurs à plusieurs). Les relations ambigües entraînent des jointures inefficaces.
- Prévoyez la croissance : Prévoyez le volume futur des données. Un design fonctionnant pour 10 000 lignes pourrait échouer avec 10 millions de lignes.
- Revoyez les chemins de jointure : Suivez les chemins que prend une requête courante à travers le diagramme. Si un chemin est trop long, envisagez d’ajouter une colonne dénormalisée.
- Documentez les contraintes : Documentez explicitement les contraintes qui sont gérées par la base de données et celles qui sont gérées par la couche application.
Comparaison : Conception normalisée vs. conception optimisée 📊
Le tableau ci-dessous illustre les différences entre une approche stricte en 3NF et une approche optimisée pour un scénario spécifique.
| Fonctionnalité | Conception stricte en 3NF | Conception optimisée |
|---|---|---|
| Redondance | Minimale | Contrôlée et limitée |
| Complexité des requêtes | Élevée (multiples jointures) | Modérée (moins de jointures) |
| Performance d’écriture | Rapide (moins de données) | Variable (déclencheurs de mise à jour) |
| Performance de lecture | Plus lente (E/S disque) | Plus rapide (données en cache) |
| Intégrité des données | Élevée | Élevée (avec validation) |
Quand briser les règles 🛑
Il existe des scénarios valides où la 3NF stricte doit être abandonnée. Comprendre quand s’écarter est crucial pour les architectes de bases de données.
- Reporting et analyse :Les entrepôts de données utilisent souvent un schéma en étoile plutôt que la 3NF. L’objectif ici est la vitesse de lecture pour l’analyse, et non l’intégrité transactionnelle.
- Systèmes transactionnels à haut débit : Si le système traite des millions d’écritures par seconde, des jointures complexes pourraient entraîner une contention de verrous. Simplifier le schéma peut réduire la charge liée aux verrous.
- Systèmes hérités : Si vous migrez depuis un ancien système, il peut être plus rapide de dénormaliser temporairement pendant la reconstruction de la couche application.
- Applications à forte charge de lecture : Si votre application lit des données 100 fois pour chaque écriture, le coût de maintien de la cohérence de la 3NF dépasse les avantages.
Liste de vérification de mise en œuvre ✅
Avant de déployer votre schéma de base de données, passez en revue cette liste de vérification pour vous assurer d’avoir équilibré performance et normalisation.
- Analysez les modèles de requêtes : Identifiez les requêtes de lecture les plus fréquentes. Ont-elles besoin de trop de jointures ?
- Mesurez les performances actuelles : Établissez une base pour votre système. Connaître la latence actuelle des requêtes critiques.
- Revoyez l’utilisation des index : Vérifiez si les index sont utilisés ou s’ils entraînent une surcharge lors des écritures.
- Testez la charge d’écriture : Assurez-vous qu’aucune stratégie de dénormalisation ne ralentisse trop les opérations d’écriture.
- Prévoyez la synchronisation des données : Si vous dupliquez des données, comment allez-vous les maintenir synchronisées ? Définissez le mécanisme.
- Surveillez les anomalies : Configurez des alertes pour les incohérences de données si vous utilisez une dénormalisation partielle.
Pensées finales sur l’architecture de base de données 🏗️
Atteindre la troisième forme normale sans compromettre les performances exige une approche nuancée. Ce n’est pas un choix binaire entre vitesse et intégrité. En comprenant le coût des jointures, en utilisant efficacement les index et en appliquant une dénormalisation sélective là où cela est pertinent, vous pouvez construire des systèmes à la fois fiables et rapides. La meilleure conception de base de données est celle qui s’aligne sur la charge de travail spécifique de l’application. Revoyez régulièrement votre MCD et la performance de vos requêtes au fur et à mesure de la croissance du système. L’adaptation est la clé du succès à long terme dans la gestion des données.