











L’architecture de base de données évolue parallèlement à la complexité de l’application. Au début du développement, une seule base de données suffit souvent à gérer toutes les opérations sur les données. Cependant, au fur et à mesure que le système grandit, le schéma initial devient fréquemment un goulot d’étranglement. Ce phénomène est couramment appelé schéma monolithique. Il se caractérise par des tables étroitement couplées, des données redondantes et des contraintes rigides qui entravent l’évolutivité. Pour y remédier, les ingénieurs recourent à une refonte structurelle. La modélisation entité-association (MEA) fournit le cadre théorique pour visualiser et organiser efficacement ces changements. Ce guide explore le processus technique de refactoring des schémas monolithiques en appliquant les principes de la MEA afin d’obtenir une couche de données plus résiliente.
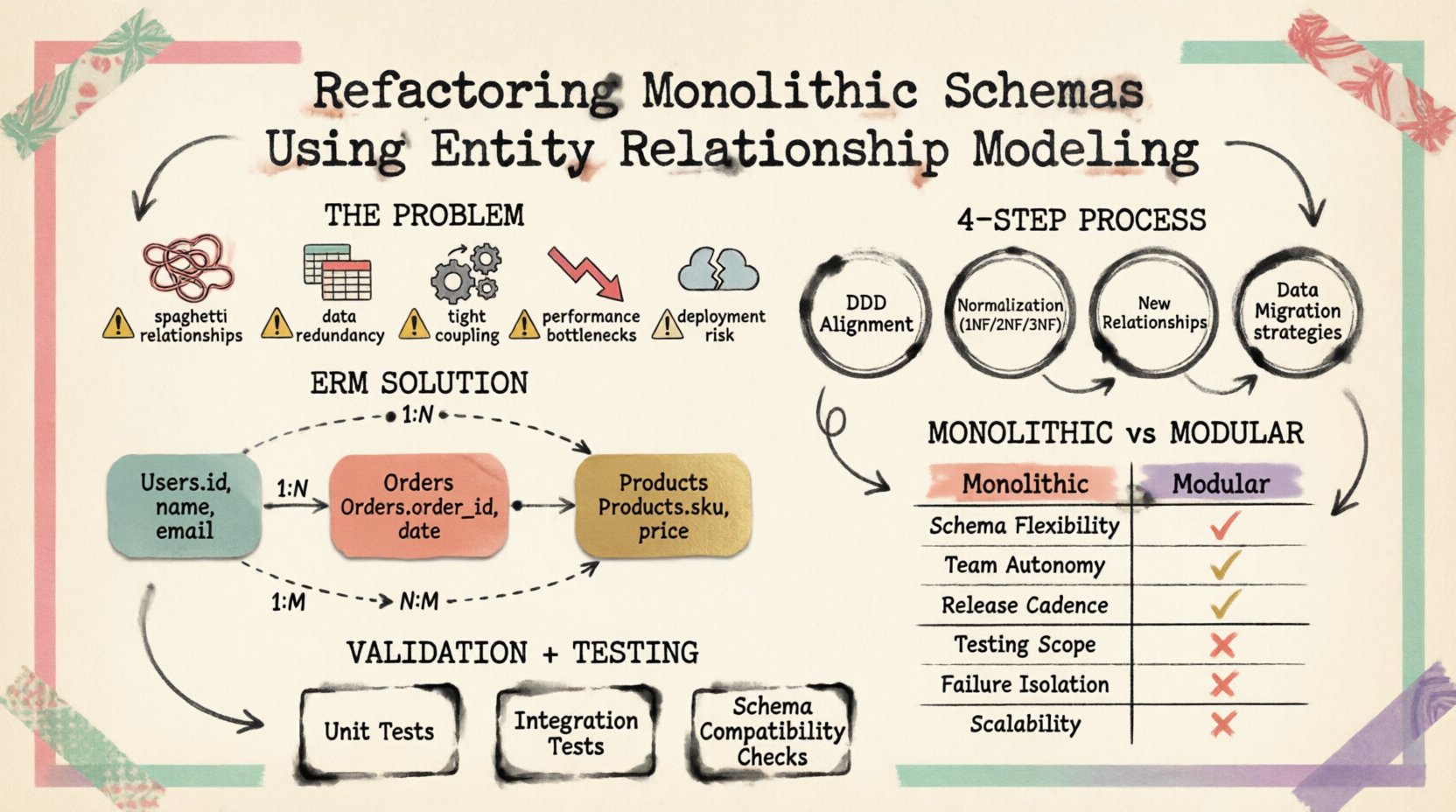
Comprendre le problème du schéma monolithique 📉
Un schéma monolithique émerge généralement d’une croissance organique plutôt que d’un plan préétabli. Les fonctionnalités sont ajoutées, et des tables sont créées pour répondre à des besoins immédiats sans tenir compte d’une séparation future. Au fil du temps, cela donne lieu à plusieurs indicateurs de dette technique :
- Relations en spaghetti :Les clés étrangères lient des entités sans rapport, créant des dépendances circulaires.
- Redondance des données :Les mêmes informations sont stockées dans plusieurs tables, entraînant des problèmes de cohérence lors des mises à jour.
- Couplage étroit :La logique d’application ne peut pas être déconnectée car la structure de la base de données l’impose.
- Goulots d’étranglement de performance :Les grandes tables contenant des types de données mixtes nécessitent des requêtes complexes qui ralentissent les opérations de lecture.
- Risque de déploiement :Modifier une seule table exige souvent la modification simultanée de plusieurs services d’application.
Reconnaître ces symptômes est la première étape vers la correction. L’objectif n’est pas simplement de réorganiser les tables, mais d’aligner la structure des données sur les domaines logiques de l’entreprise.
Le rôle de la modélisation entité-association 📐
La modélisation entité-association sert de plan directeur pour la conception de base de données. Elle définit les entités (tables), les attributs (colonnes) et les relations (clés étrangères) sous une forme visuelle et logique. Lors d’une refonte, la MEA agit comme un mécanisme de contrôle pour garantir que la nouvelle structure reste cohérente.
Composants fondamentaux de la MEA
- Entités : Représentent des objets ou des concepts distincts, tels que Utilisateurs ou Commandes. Dans un schéma, ces entités deviennent des tables.
- Attributs : Propriétés décrivant l’entité, telles que email ou prix. Ces attributs correspondent aux colonnes.
- Relations : Définir comment les entités interagissent, par exemple un à un ou un à plusieurs.
- Cardinalité : Spécifie le nombre minimum et maximum d’instances impliquées dans une relation.
Utiliser le MRE pendant la refonte permet aux équipes de simuler les modifications avant de les appliquer à l’environnement de production. Cela aide à identifier précocement les données orphelines, les contraintes manquantes et les problèmes de normalisation.
Phase d’évaluation préalable à la refonte 🔍
Avant de modifier des tables existantes, une vérification approfondie est nécessaire. Cette phase garantit que aucune logique métier ne sera perdue au cours de la transition.
- Inventaire des tables existantes : Documenter chaque table, colonne, index et contrainte actuellement présent dans le système.
- Analyser les modèles de requêtes : Identifier les requêtes les plus fréquemment exécutées et les tables les plus souvent lues.
- Cartographier les dépendances des données : Suivre le flux des données depuis la base de données jusqu’à l’application et inversement.
- Identifier les colonnes redondantes : Rechercher les colonnes qui stockent les mêmes informations dans plusieurs tables.
- Examiner les clés étrangères : Déterminer si les relations sont contraintes au niveau de la base de données ou gérées dans le code.
Cette évaluation établit une base de référence. Sans elle, la refonte peut introduire des bogues subtils difficiles à retracer ultérieurement.
Le processus de refonte : étape par étape 🔄
Transformer un schéma monolithique en une structure modulaire exige une approche méthodique. Les étapes suivantes décrivent le flux standard de refonte de schéma à l’aide du modèle d’entités et de relations.
1. Alignement sur la conception axée sur le domaine (DDD)
Commencez par regrouper les tables selon les domaines métiers. Cela est souvent appelé contexte borné. Au lieu d’organiser les tables par fonction (par exemple, toutes les tables pour le reporting), organisez-les par capacité (par exemple, les tables pour la facturation, les tables pour l’authentification). Cette séparation réduit le couplage entre les parties non liées du système.
2. Normalisation
La normalisation réduit la redondance des données et améliore l’intégrité. Ce processus consiste à diviser les grandes tables en tables plus petites et logiquement liées.
- Première forme normale (1NF) : Assurez-vous des valeurs atomiques. Chaque colonne ne doit contenir qu’une seule valeur.
- Deuxième forme normale (2NF) : Supprimez les dépendances partielles. Tous les attributs non clés doivent dépendre de la clé primaire entière.
- Troisième forme normale (3NF) : Supprimez les dépendances transitives. Les attributs non clés ne doivent pas dépendre d’autres attributs non clés.
Bien que la 3NF soit l’objectif standard, certains besoins de performance peuvent nécessiter une dénormalisation contrôlée. Cette décision doit être documentée.
3. Définition des nouvelles relations
Une fois que les tables sont séparées, les relations doivent être rétablies. Cela implique la création de nouvelles clés étrangères et de tables de jonction pour les relations plusieurs à plusieurs. Par exemple, si un Produit peut appartenir à plusieurs Catégories, une table de jonction est nécessaire pour les relier.
4. Stratégie de migration des données
Le déplacement des données du schéma ancien vers le nouveau est la phase la plus risquée. Les stratégies incluent :
- Migration par instantané :Arrêter les écritures, exporter les données, les transformer et les importer dans le nouveau schéma. Nécessite une interruption de service.
- Écriture double :Écrire simultanément dans les anciens et les nouveaux schémas pendant une période de transition.
- Réplication basée sur les journaux :Capturer les modifications à partir du journal des transactions de la base de données et les appliquer à la nouvelle structure.
Péchés courants à éviter 🛑
Le restructurage introduit de la complexité. Certaines erreurs peuvent compromettre l’intégrité du système.
- Ignorer les types de données : Modifier une colonne de Entier à Chaîne sans vérifier la logique en aval peut casser le code de l’application.
- Sur-normalisation : Créer trop de tables peut entraîner des jointures excessives, ce qui dégrade les performances des requêtes.
- Perte des contraintes : Déplacer les contraintes de la base de données vers la couche application peut entraîner une corruption des données si plusieurs services écrivent sur les mêmes données.
- Oubli des index : Les nouvelles tables nécessitent de nouveaux index. L’absence d’indexation des nouvelles clés étrangères ralentira les opérations de jointure.
Stratégies de validation et de test ✅
Après la refonte du schéma, la validation est essentielle. Les tests automatisés doivent vérifier que l’intégrité des données est maintenue à travers les nouvelles frontières.
- Vérifications de cohérence des données :Exécuter des requêtes pour garantir que l’intégrité référentielle est respectée dans toutes les nouvelles relations.
- Benchmark de performance :Comparer les temps d’exécution des requêtes avant et après la refonte.
- Vérification du nombre de lignes :Assurer que le nombre total d’enregistrements reste constant (en excluant les doublons créés pendant la migration).
- Tests de régression de l’application :Exécuter l’ensemble complet des tests d’application contre la nouvelle structure de base de données.
Comparaison : Schéma monolithique vs. Schéma modulaire
Le tableau ci-dessous décrit les différences entre la structure monolithique héritée et l’approche modulaire révisée.
| Fonctionnalité | Schéma monolithique | Schéma révisé |
|---|---|---|
| Structure des tables | Grandes tables à usage mixte | Tables spécialisées, spécifiques au domaine |
| Redondance des données | Élevée | Minimisée par la normalisation |
| Évolutivité | Difficile à fractionner | Plus facile à partitionner par domaine |
| Déploiement | Modifications globales du schéma | Mises à jour locales du schéma |
| Complexité des requêtes | Jointures complexes sur de grandes tables | Jointures optimisées sur des tables plus petites |
Transition vers une architecture de microservices 🚀
Le restructurage du schéma est souvent une étape préalable à l’adoption des microservices. Un modèle relationnel d’entités propre rend plus facile l’affectation de la propriété de données spécifiques à des services spécifiques. Lorsque chaque service gère sa propre base de données, le schéma devient un contrat entre les services plutôt qu’une ressource partagée.
Ce changement exige une gestion soigneuse de la cohérence des données. Au lieu d’utiliser des transactions sur plusieurs bases de données, les systèmes peuvent s’appuyer sur des modèles de cohérence éventuelle. Le MRE aide à définir clairement ces limites, en s’assurant qu’aucun service n’assume la propriété de données qu’il ne gère pas.
Considérations finales pour la santé à long terme 🛡️
Maintenir un schéma sain exige une discipline continue. La documentation doit être mise à jour chaque fois qu’une table est ajoutée ou modifiée. Le contrôle de version doit être appliqué aux définitions de schéma, et non seulement au code de l’application. Des revues régulières doivent être planifiées pour identifier de nouveaux cas de couplage au fur et à mesure de l’ajout de fonctionnalités.
Le modélisation des relations entre entités n’est pas une tâche ponctuelle. C’est une pratique continue qui garantit que la base de données reste alignée sur les besoins métiers. En suivant ces étapes structurées, les organisations peuvent atténuer les risques liés aux structures de données héritées et construire une fondation capable de soutenir la croissance future.
La transition d’un schéma monolithique vers une conception modulaire est une entreprise importante. Elle exige de la patience, des tests rigoureux et une compréhension approfondie des relations entre les données. Toutefois, le résultat est un système plus facile à maintenir, plus rapide à échelle et plus résilient aux changements. L’effort investi dans la modélisation rapporte des bénéfices en stabilité opérationnelle et en vitesse de développement à long terme.