











Diseñar una base de datos robusta comienza mucho antes de que se ejecute la primera consulta. Comienza con el plano: el Diagrama de Entidad-Relación (ERD). 📐 Mientras muchos desarrolladores se enfocan en la creación de tablas y tipos de columnas, el verdadero motor de rendimiento reside en cómo los índices se alinean con su modelo de datos. Indexar no es meramente una configuración; es una manifestación física de sus relaciones lógicas.
Cuando estructuras tu ERD, defines la cardinalidad y conectividad de tus datos. Estas decisiones estructurales determinan las estrategias de indexación más eficientes. Una relación uno-a-uno requiere un enfoque diferente al de una unión muchos-a-muchos. Ignorar estas sutilezas con frecuencia conduce a uniones lentas, I/O excesivo y almacenamiento fragmentado. Esta guía explora cómo traducir tu ERD en patrones de indexación de alto rendimiento sin depender de herramientas específicas de proveedores.
🔑 Comprendiendo la base: ERD e indexación
Un ERD es más que una ayuda visual; es un contrato entre la lógica de su aplicación y el motor de almacenamiento. Cada línea trazada entre entidades representa una restricción que la base de datos debe cumplir. Los índices sirven para acelerar el cumplimiento de estas restricciones y la recuperación de datos a través de ellas.
Considere la capa de almacenamiento como una biblioteca. Sin un índice, encontrar un libro requiere escanear cada estante (una búsqueda completa de la tabla). Un índice es la ficha del catálogo. Sin embargo, colocar las fichas del catálogo incorrectamente—por ejemplo, por género en lugar de por autor cuando los autores son la clave de búsqueda principal—hace que el sistema sea ineficiente. Su ERD le indica quiénes son los autores y géneros, y qué relaciones son más importantes.
Las consideraciones clave incluyen:
- Cardinalidad:Las columnas de alta cardinalidad (valores únicos) se benefician más con los índices.
- Frecuencia de unión:Las tablas que se unen con frecuencia requieren indexación específica en las claves foráneas.
- Volumen de escritura:Cada índice añade sobrecarga a las operaciones de inserción y actualización.
- Patrones de consulta:¿Cómo filtra? ¿Cómo ordena? El ERD da pistas sobre la respuesta.
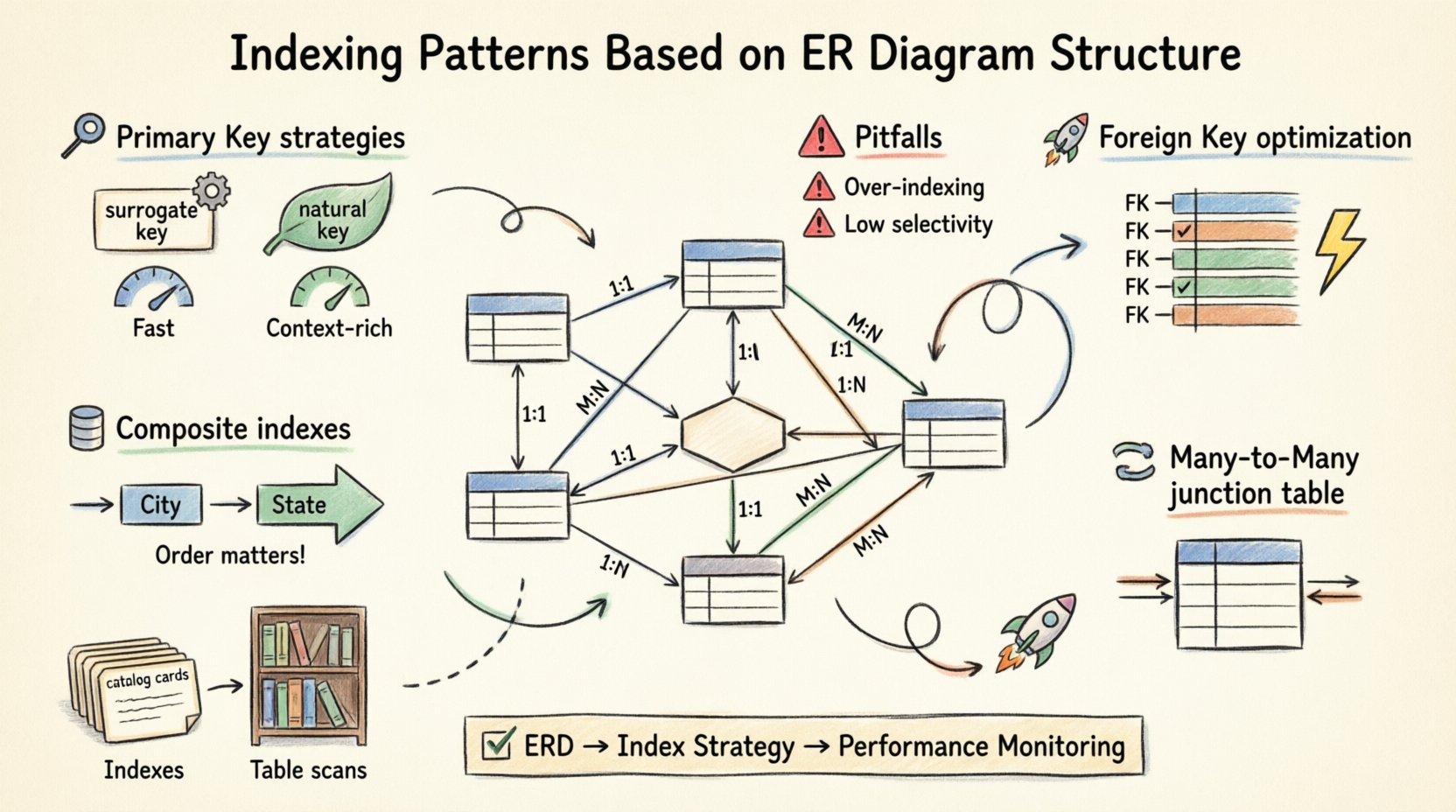
🏗️ Estrategias de indexación de claves primarias
La clave primaria (PK) es la columna principal de cada tabla. Garantiza la unicidad y proporciona el mecanismo de agrupación para el almacenamiento de datos en muchos sistemas. Alinear su indexación con la definición de la PK es el primer paso.
1. Claves sustitutas frente a claves naturales
Elegir entre una clave sustituta (un ID autoincremental) y una clave natural (como un correo electrónico o número de seguro social) afecta significativamente el rendimiento del índice.
- Claves sustitutas:Son ideales para agrupación. Son cortas, crecientes monótonamente y secuenciales. Esto minimiza los fragmentos de páginas y la fragmentación durante las escrituras. 📈
- Claves naturales:Aunque son semanticamente significativas, pueden ser largas, de longitud variable o propensas a cambiar. Indexarlas puede provocar tamaños de índice más grandes y búsquedas más lentas en comparación con claves basadas en enteros.
2. Implicaciones del índice agrupado
En la mayoría de las arquitecturas, la clave primaria define el índice agrupado. Esto significa que las filas de datos reales se almacenan físicamente en el orden de la clave. Si su ERD sugiere que las consultas filtran con frecuencia por un atributo natural específico, podría necesitar reconsiderar la definición de la PK o aceptar que el índice agrupado estará optimizado para un tipo de consulta, mientras que los índices secundarios manejan los demás.
🔗 Optimización de claves foráneas
Las claves foráneas (FK) definen relaciones entre tablas. Son la fuente más común de cuellos de botella de rendimiento si no se indexan. Cuando une dos tablas, el motor de base de datos debe emparejar filas según la columna FK. Sin un índice, esta operación se degrada a un escaneo de bucle anidado, lo cual es computacionalmente costoso para conjuntos de datos grandes.
1. Indexación de la columna de clave foránea
Siempre cree un índice en la columna de clave foránea en la tabla hija. Esto permite al motor localizar rápidamente las filas relacionadas sin escanear toda la tabla.
| Escenario | Requisito de indexación | Impacto en el rendimiento |
|---|---|---|
| Uno a muchos (hijo) | Indexar la clave foránea en la tabla hija | Permite búsquedas rápidas para datos del padre |
| Muchos a uno (padre) | Indexar la clave primaria en la tabla padre (por defecto generalmente) | Comportamiento estándar de clave primaria |
| Eliminaciones en cascada | Indexar FK + PK del padre | Evita bloquear toda la tabla durante la eliminación |
2. Claves foráneas compuestas
A veces, una relación depende de múltiples columnas (por ejemplo, una clave compuesta de la tabla padre). En este caso, debe crear un índice compuesto en la tabla hija que coincida con el orden y las columnas de la clave del padre. Un desajuste en el orden de las columnas en el índice puede hacerlo inútil para operaciones de unión.
🔀 Manejo de relaciones muchos a muchos
Las relaciones muchos a muchos (M:N) se resuelven mediante una tabla de unión. Esta tabla contiene claves foráneas que apuntan a ambas tablas padres. La estrategia de indexación aquí es crítica para el rendimiento.
Considere un escenario en el queEstudiantes se matriculan en Cursos. La tabla de unión los enlaza. Para encontrar todos los cursos de un estudiante, debe consultar la tabla de unión de manera eficiente.
- Indexación bidireccional: Debería indexar ambas columnas de clave foránea de forma independiente. Esto le permite consultar la relación desde cualquiera de los dos lados (Estudiante → Cursos o Curso → Estudiantes) sin realizar un escaneo completo.
- Indexación compuesta: Si sus consultas siempre recuperan los cursos de un estudiante específico, un índice compuesto en (Student_ID, Course_ID) es más eficiente que dos índices separados. Cubre los criterios de búsqueda en una única búsqueda.
📊 Índices compuestos y de cobertura
No todas las consultas filtran por una sola columna. Las consultas complejas a menudo implican múltiples condiciones. Es aquí donde los índices compuestos destacan. Un índice compuesto es un único índice construido sobre múltiples columnas.
1. El orden de las columnas importa
El orden de las columnas en un índice compuesto no es arbitrario. El motor de base de datos solo puede utilizar el índice hasta el punto en que las condiciones de igualdad terminan. Por ejemplo, si indexa (Ciudad, Estado), una consulta que filtre por Ciudad usará el índice. Una consulta que filtre solo por Estado probablemente lo ignore.
2. Índices de cobertura
Un índice de cobertura incluye todas las columnas necesarias para satisfacer una consulta, incluyendo la lista de selección. Esto permite al motor de base de datos recuperar los datos directamente desde el árbol del índice sin acceder a la tabla principal (heap). Esto representa una gran ventaja de rendimiento para operaciones intensivas de lectura.
⚠️ Errores comunes y mejores prácticas
Incluso con un ERD perfecto, los errores de implementación pueden degradar el rendimiento. A continuación se indican trampas comunes que deben evitarse al traducir la estructura al almacenamiento.
- Sobrindización:Cada índice consume espacio en disco y ralentiza las operaciones de escritura. Solo indexe las columnas que se consultan con frecuencia o se utilizan para restricciones.
- Baja selectividad:Indexar una columna con baja cardinalidad (por ejemplo, una bandera booleana “is_active”) suele ser ineficiente. El optimizador podría decidir que una escaneo completo de la tabla es más rápido que saltar a un índice.
- Ignorar valores nulos:Los índices manejan los valores nulos de forma diferente según el motor. Asegúrese de que la lógica de sus consultas tenga en cuenta cómo se indexan los valores nulos en su configuración específica.
- Fragmentación:Con el tiempo, los índices se fragmentan. Se requiere mantenimiento regular para mantener un rendimiento óptimo.
🛠️ Monitoreo y mantenimiento del rendimiento
Una vez que su estrategia de indexación esté en lugar, el monitoreo es esencial. No puede optimizar lo que no mide. Revise periódicamente los planes de ejecución de consultas para ver si sus índices se están utilizando de forma eficaz.
1. Analice los planes de ejecución
Busque operaciones como “Escaneo de índice” frente a “Búsqueda de índice”. Una búsqueda es eficiente; un escaneo no lo es. Si observa escaneos completos de tablas en tablas grandes, revise su estrategia de indexación según los patrones de consulta reales.
2. Monitoree el uso de índices
A veces, se crean índices pero nunca se utilizan. Son un peso muerto. Revise periódicamente las estadísticas de uso de índices para identificar los índices no utilizados que pueden eliminarse para mejorar el rendimiento de escritura.
3. Consideraciones sobre el crecimiento de datos
A medida que sus datos crecen, aumenta el costo del mantenimiento. Un índice que funciona bien con 10.000 filas podría convertirse en un cuello de botella con 10 millones de filas. Revalúe sus patrones de indexación derivados de su ERD a medida que el conjunto de datos crece. Las estrategias de partición también podrían volverse necesarias junto con la indexación.
🔄 Resumen de la alineación
Alinear su estrategia de indexación con la estructura de su ERD es un proceso continuo. Requiere comprender las relaciones entre datos definidas en su diseño y traducirlas en optimizaciones de almacenamiento físico.
- Claves primarias:Úselas para agrupación y unicidad.
- Claves foráneas:Indexe para mejorar el rendimiento de las uniones.
- Tablas de unión:Indexación bidireccional para relaciones M:N.
- Patrones de consulta:Ajuste los índices compuestos a órdenes específicas de filtro.
Al respetar la integridad estructural de su ERD, construye una base de datos que se escala de forma adecuada. Evita los errores comunes de indexación improvisada y garantiza que sus datos permanezcan accesibles y con buen rendimiento a medida que evoluciona su aplicación. Este enfoque disciplinado asegura que la base de datos apoye su lógica de negocio sin convertirse en un cuello de botella. 🚀