










A medida que la acumulación de datos se acelera, la arquitectura de su esquema de base de datos se convierte en un determinante crítico de la estabilidad del sistema. Cuando una aplicación pasa de operaciones de lectura intensiva a cargas de trabajo de escritura intensiva, el diagrama de relaciones de entidad estándar (ERD) a menudo requiere ajustes significativos. Diseñar para un alto rendimiento no consiste únicamente en agregar índices; exige una reconsideración fundamental de cómo se estructura, vincula y almacena la información. Esta guía explora los cambios arquitectónicos necesarios para mantener el rendimiento bajo presión sin comprometer la integridad de los datos.
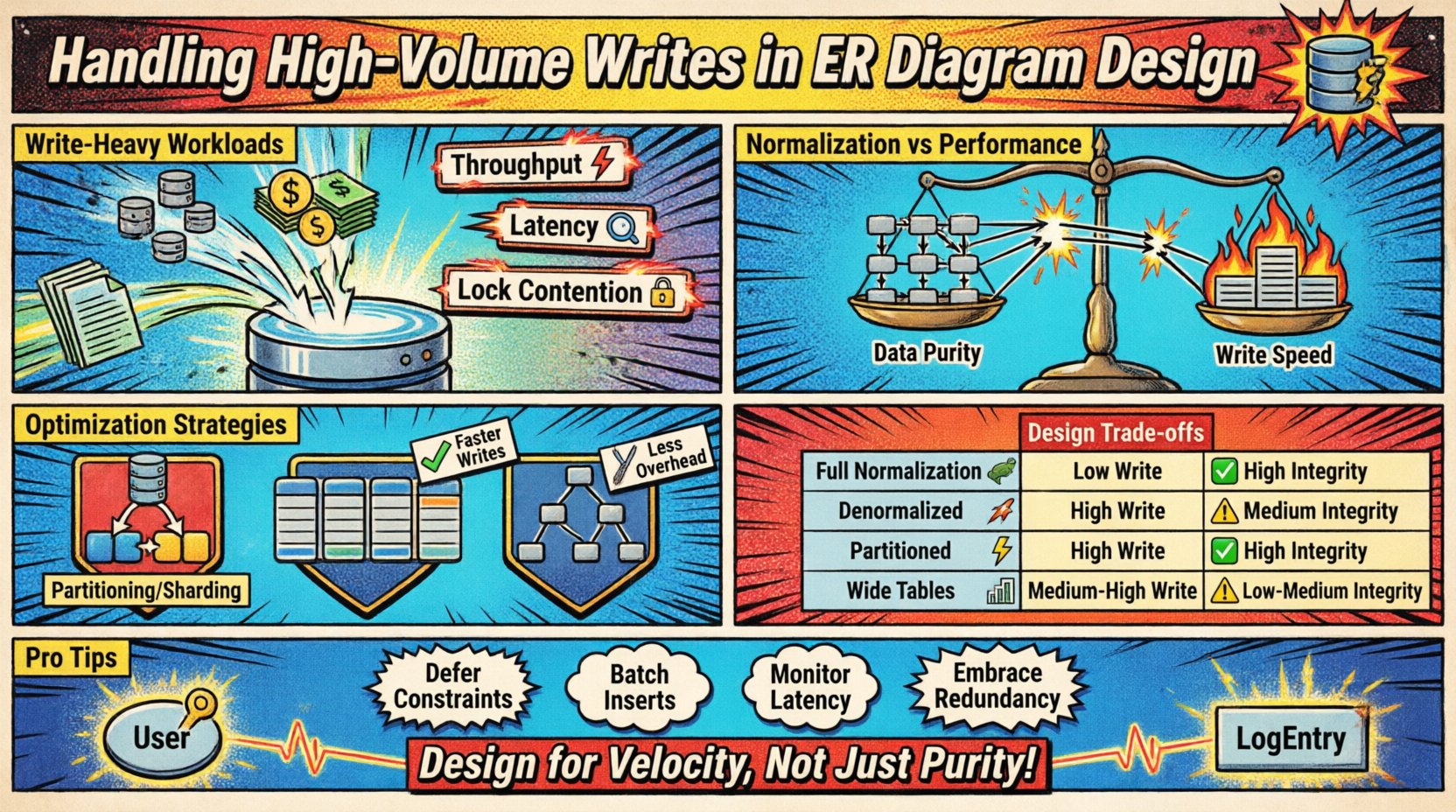
Comprender las cargas de trabajo de escritura intensiva 📈
Los escenarios de escritura de alto volumen ocurren cuando la tasa de datos entrantes supera la capacidad de las técnicas estándar de normalización. Esto suele ocurrir en sistemas de registro, flujos de sensores IoT, libros mayores de transacciones financieras o plataformas de análisis en tiempo real. El principal desafío radica en equilibrar la velocidad de inserción con los requisitos de consistencia del modelo.
- Rendimiento: El número de operaciones de escritura procesadas por segundo.
- Latencia: El tiempo necesario para guardar con éxito un registro.
- Contención de bloqueos: Competencia por recursos cuando múltiples procesos intentan modificar los mismos datos.
Cuando estas métricas empeoran, el esquema en sí mismo suele ser el cuello de botella. Un diseño rígido optimizado para consultas complejas puede desmoronarse bajo el peso de actualizaciones constantes. Por lo tanto, el ERD inicial debe tener en cuenta la velocidad de entrada de datos.
Normalización frente a compromisos de rendimiento ⚖️
El diseño tradicional de bases de datos fomenta la normalización (1FN, 2FN, 3FN) para reducir la redundancia. Aunque esto ahorra espacio de almacenamiento y garantiza la consistencia, introduce sobrecarga durante las operaciones de escritura. Cada relación de clave foránea requiere una búsqueda y una verificación de unión para mantener la integridad referencial.
En un entorno de alto volumen, estas verificaciones se vuelven costosas. Considere las implicaciones de una relación muchos a muchos durante un evento de escritura:
- La tabla principal debe actualizarse.
- La tabla de unión debe insertar una nueva fila.
- La segunda tabla debe verificar la relación.
- Los registros de transacciones deben registrar todos los cambios.
Cada paso añade E/S de disco y ciclos de CPU. Para manejar cargas pesadas de escritura, los diseñadores a menudo relajan las reglas de normalización. Este proceso implica aceptar redundancia de datos para reducir el número de operaciones de escritura necesarias para almacenar una unidad de información.
Estrategias para optimizar la velocidad de escritura ✍️
Existen varios patrones estructurales para mitigar la presión de escritura. Estas estrategias se centran en minimizar el tamaño de cada transacción y reducir la complejidad del trabajo del motor de almacenamiento.
1. Particionamiento y fragmentación
Dividir una tabla grande en fragmentos más pequeños y manejables permite que la base de datos distribuya la carga de escritura entre múltiples segmentos físicos o lógicos.
- Particionamiento horizontal: Dividir filas según una clave (por ejemplo, rangos de fechas, identificadores de usuario).
- Particionamiento vertical: Mover columnas poco accesibles a tablas separadas.
- Fragmentación: Distribuir datos entre múltiples instancias de base de datos.
Este enfoque reduce el tamaño de los índices que deben mantenerse y limita el alcance de los bloqueos durante una operación de escritura. Si una fragmentación se satura, las demás permanecen afectadas.
2. Estrategias de denormalización
Almacenar datos redundantes permite al sistema evitar las uniones durante las escrituras. Por ejemplo, en lugar de calcular la suma total a partir de filas relacionadas cada vez que llega una nueva transacción, el sistema puede actualizar directamente una columna de resumen previamente calculada.
- Columnas calculadas: Almacene valores derivados directamente en la fila.
- Vistas materializadas: Calcule de antemano los resultados para agregaciones frecuentes.
- Contadores en caché: Mantenga una tabla de contadores independiente para estadísticas.
Aunque esto aumenta los requisitos de almacenamiento, reduce significativamente el costo de CPU de la inserción.
3. Estrategia de índices
Los índices aceleran las lecturas pero ralentizan las escrituras. Cada vez que se inserta una fila, la base de datos debe actualizar cada índice asociado. En entornos de alta escritura, el crecimiento excesivo de índices se convierte en un problema importante.
- Minimice la cantidad de índices: Solo indexe las columnas utilizadas para filtrar o unir.
- Índices parciales: Indexe solo un subconjunto de filas que se acceden con frecuencia.
- Evite el sobreíndice: Omita los índices en columnas que cambian con frecuencia.
Comparación de enfoques de diseño 📑
La tabla a continuación describe el impacto de diferentes elecciones estructurales en el rendimiento de escritura y la integridad de los datos.
| Estrategia | Rendimiento de escritura | Integridad de los datos | Costo de almacenamiento | Mejor caso de uso |
|---|---|---|---|---|
| Normalización completa | Bajo | Alto | Bajo | Informes complejos, bajo volumen de escritura |
| Denormalizado | Alto | Medio | Alto | Flujos en tiempo real, alto volumen de escritura |
| Esquema particionado | Alto | Alto | Medio | Datos de series temporales, grandes conjuntos de datos |
| Tablas anchas | Medio-Alto | Medio | Medio | Patrones NoSQL, datos dispersos |
Manejo de claves foráneas y restricciones 🔗
La integridad referencial es un pilar del diseño relacional, pero imponer restricciones en cada inserción puede bloquear una tubería de alta velocidad. El motor de base de datos debe verificar que la fila padre referenciada exista antes de aceptar la fila hija.
En escenarios donde la integridad de los datos es crítica pero la velocidad de escritura es prioritaria, considere los siguientes ajustes:
- Restricciones diferidas:Valide las relaciones al final de una transacción en lugar de de inmediato.
- Verificaciones a nivel de aplicación:Verifique las relaciones en el código de la aplicación antes de enviar los datos a la base de datos.
- Eliminaciones suaves:Marque los registros como inactivos en lugar de eliminarlos para preservar los enlaces referenciales sin la sobrecarga de eliminación.
Eliminar las restricciones por completo es arriesgado, pero mover la lógica de validación a veces puede mejorar el rendimiento. La decisión depende de cuán crítica es la consistencia inmediata para su flujo de trabajo específico.
Amplificación de escritura y motores de almacenamiento 💾
Comprender cómo el motor de almacenamiento maneja los datos es fundamental. Muchos motores utilizan un registro de escritura anticipada (WAL) para garantizar la durabilidad. Esto significa que cada escritura se registra antes de aplicarse a los archivos de datos reales.
Amplificación de escrituraocurre cuando una sola operación lógica de escritura resulta en múltiples escrituras físicas. Esto es común en motores de almacenamiento con compresión intensiva. Para gestionarlo:
- Inserciones por lotes:Agrupe múltiples filas en una sola transacción.
- Escrituras secuenciales:Diseñe esquemas para favorecer la generación secuencial de claves sobre inserciones aleatorias.
- Almacenamiento en búfer:Permita un búfer temporal en la capa de aplicación para colocar en cola las escrituras antes de vaciarlas.
Al alinear el diseño del ERD con las fortalezas del motor de almacenamiento, puede minimizar el esfuerzo físico necesario para persistir los datos.
Monitoreo e iteración 🔄
Un esquema diseñado para escrituras altas no es estático. A medida que los patrones de tráfico cambian, el diseño podría necesitar evolucionar. El monitoreo continuo de la latencia de escritura y la E/S del disco es esencial.
- Monitoree la latencia de escritura:Identifique picos que indican cuellos de botella.
- Monitoree las esperas de bloqueo:Detecte puntos de contención donde los procesos están bloqueados.
- Analice el uso de índices:Elimine los índices que nunca se utilizan para reducir la sobrecarga de escritura.
Las auditorías regulares del ERD aseguran que la estructura permanezca alineada con las demandas operativas actuales. Si una tabla específica lucha constantemente con el rendimiento de escritura, podría ser momento de revisar la estrategia de partición o el nivel de normalización.
Resumen de consideraciones clave 🛠️
Diseñar un ERD para escrituras de alto volumen requiere un cambio de mentalidad desde la pureza de datos pura hacia el rendimiento del sistema. Los siguientes puntos resumen las acciones esenciales:
- Audite la normalización:Asegúrese de que cada relación aporte valor en lugar de solo complejidad.
- Planee la partición:Estructura las claves para permitir una división horizontal fácil.
- Límite de índices:Mantenga la ruta de escritura lo más ágil posible.
- Acepte la redundancia:Utilice la denormalización para reducir las dependencias de unión durante la inserción.
- Valide de forma gradual:Mueva la verificación de restricciones fuera de la ruta crítica de escritura cuando sea seguro.
Al aplicar estos principios, crea un modelo de datos capaz de sostener el crecimiento sin sacrificar el rendimiento. El objetivo no es eliminar la complejidad, sino gestionarla de una manera que apoye la velocidad de su aplicación.