











Los diagramas de entidades y relaciones (DER) sirven como plano directriz para la arquitectura de bases de datos. Definen cómo se estructura, almacena y recupera la información dentro de un sistema. Cuando estos diagramas presentan errores, las consecuencias van mucho más allá de la fase de desarrollo. Los errores en entornos de producción pueden provocar corrupción de datos, cuellos de botella de rendimiento y pérdidas financieras significativas. Comprender los errores comunes es esencial para mantener la integridad del sistema.
Muchos equipos se apresuran a través de la fase de modelado, priorizando la velocidad sobre la precisión. Esta prisa a menudo genera problemas en el esquema que resultan difíciles de resolver una vez que los datos comienzan a fluir. Un diseño sólido requiere una consideración cuidadosa de las relaciones, los tipos de datos y las restricciones. A continuación, exploramos los errores de diseño más frecuentes y sus implicaciones técnicas.
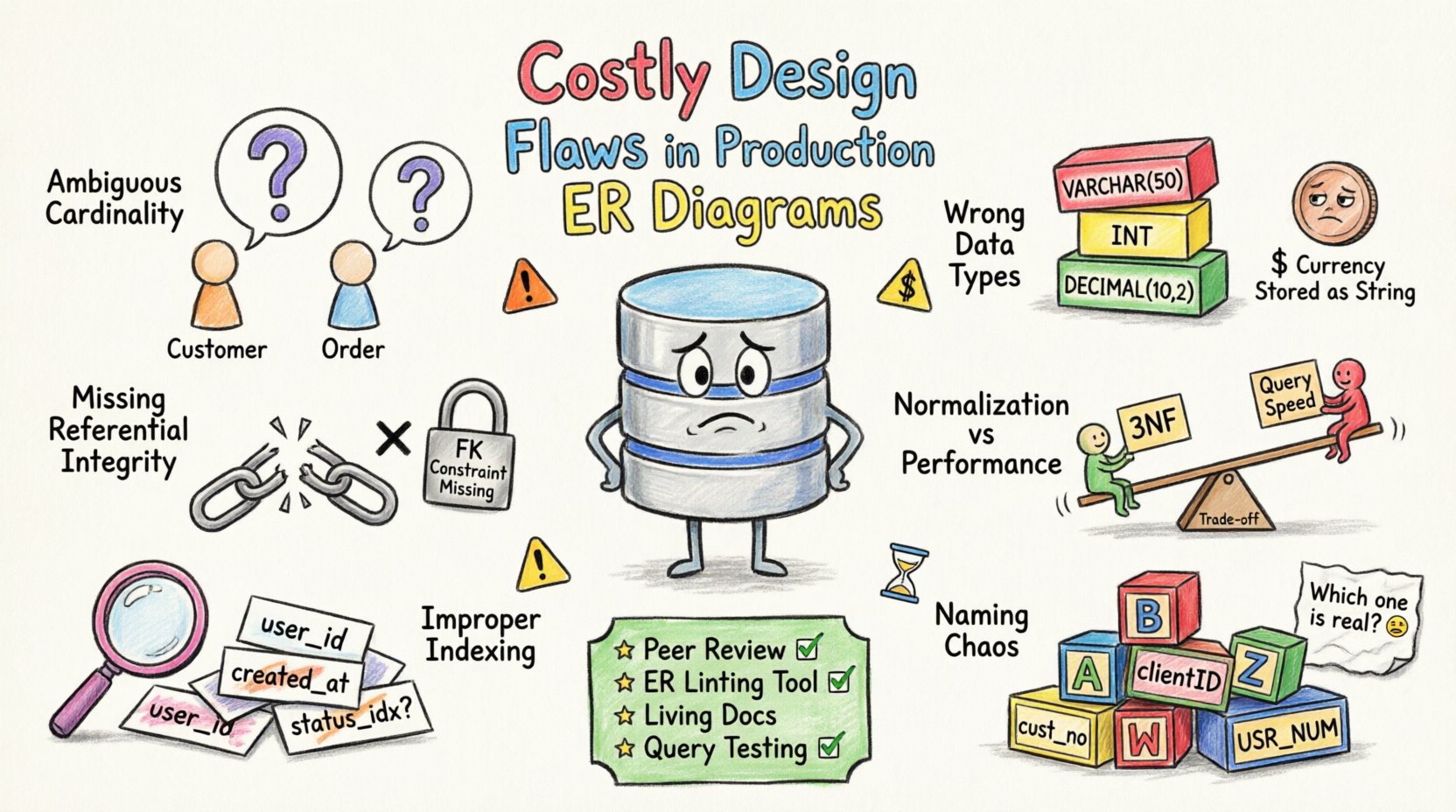
1. Cardinalidad y relaciones ambiguas 🔗
La cardinalidad define la relación numérica entre entidades. Una cardinalidad incorrecta provoca errores lógicos en la recuperación y almacenamiento de datos. Un error común es asumir una relación uno a uno cuando en realidad existe una relación uno a muchos.
- Omisión de relaciones muchos a muchos:No crear una tabla de unión para relaciones muchos a muchos obliga a duplicar datos o a realizar consultas de unión complejas.
- Claves foráneas no definidas:Sin claves foráneas explícitas, la base de datos no puede garantizar la integridad referencial, permitiendo registros huérfanos.
- Opcional frente a obligatorio:Clasificar erróneamente una relación obligatoria como opcional introduce valores nulos donde se espera datos.
Por ejemplo, considere un cliente y un pedido. Si el diagrama implica que un cliente puede existir sin un pedido, pero la lógica de la aplicación lo requiere, la base de datos almacenará perfiles incompletos. Esta discrepancia provoca fallos en la aplicación o informes inconsistentes.
2. Selección inconsistente de tipos de datos 📊
Los tipos de datos determinan cómo se almacena y procesa la información. Seleccionar el tipo incorrecto consume almacenamiento innecesario o limita el rango de valores. Los problemas de precisión surgen con frecuencia cuando se utilizan números de punto flotante para valores monetarios.
- Desbordamiento de enteros:Utilizar enteros pequeños para identificadores puede provocar errores de desbordamiento a medida que crece el conjunto de datos.
- Longitud de texto:Utilizar campos de caracteres de longitud fija desperdicia espacio para datos de longitud variable.
- Precisión de fechas:Almacenar fechas sin zonas horarias genera problemas de sincronización en sistemas distribuidos.
Elegir un campo de texto genérico para números de teléfono es otro error frecuente. Esto permite que caracteres inválidos ingresen al sistema, complicando la lógica de validación más adelante. Los campos numéricos deben usarse para cálculos, y los campos de texto solo para datos alfanuméricos.
3. Restricciones de integridad referencial faltantes 🔒
La integridad referencial garantiza que las relaciones entre tablas permanezcan consistentes. Sin estas restricciones, la base de datos depende del código de la aplicación para mantener la precisión de los datos, lo cual está sujeto a errores humanos.
- Sin reglas de cascada:Eliminar un registro padre sin reglas de cascada deja registros hijos colgando en la base de datos.
- Restricciones faltantes:Depender de la validación a nivel de aplicación en lugar de restricciones de base de datos es insuficiente.
- Eliminaciones suaves:El manejo inadecuado de registros eliminados genera desorden y ralentiza el rendimiento de las consultas.
Cuando faltan restricciones, la integridad de los datos depende enteramente de los desarrolladores de aplicaciones. Si un error permite una escritura directa en la base de datos, las inconsistencias se vuelven permanentes. Este es una causa principal de corrupción de datos en sistemas de producción de larga duración.
4. Normalización frente a compromisos de rendimiento ⚖️
La normalización reduce la redundancia, pero puede aumentar la complejidad de las consultas. La sobre-normalización conduce a un número excesivo de combinaciones (joins), mientras que la sub-normalización genera anomalías de actualización. Encontrar el equilibrio es fundamental para el rendimiento.
- Tercera Forma Normal (3FN):A menudo ideal para sistemas transaccionales, pero puede requerir desnormalización para cargas de trabajo con muchas lecturas.
- Desnormalización:Introducir redundancia con el fin de mejorar el rendimiento debe documentarse para evitar conflictos de actualización.
- Complejidad de las consultas:Los esquemas profundamente normalizados requieren combinaciones complejas que sobrecargan el motor de la base de datos.
Los equipos a menudo normalizan en exceso para garantizar la pureza de los datos, ignorando el costo de unir múltiples tablas. En entornos de alta carga, esto provoca tiempos de respuesta lentos. La desnormalización estratégica puede mejorar el rendimiento de lectura, siempre que las operaciones de escritura se gestionen correctamente.
5. Estrategia de indexación inadecuada 🏷️
Los índices aceleran la recuperación de datos, pero ralentizan las operaciones de escritura. Un ERD defectuoso suele no tener en cuenta cómo se consultarán los datos. Esto provoca escaneos completos de tablas y alta latencia.
- Índices faltantes para claves foráneas:Las combinaciones (joins) en columnas sin índice son computacionalmente costosas.
- Sobrereferenciación (over-indexing):Demasiados índices aumentan la latencia de escritura y los requisitos de almacenamiento.
- Orden de los índices compuestos:Un orden incorrecto de las columnas en los índices compuestos los hace ineficaces.
Un índice en una columna frecuentemente consultada es una práctica estándar. Sin embargo, ignorar los patrones de consulta durante la fase de diseño conduce a caminos de acceso ineficientes. Es necesario revisar periódicamente los planes de ejecución de consultas para ajustar las estrategias de indexación.
6. Caos en las convenciones de nomenclatura 🏷️
Las convenciones de nomenclatura consistentes son vitales para la mantenibilidad. Los nombres de tablas y columnas inconsistentes hacen que el esquema sea difícil de entender y modificar.
- Mayúsculas y minúsculas mezcladas:Usar camelCase en algunos lugares y snake_case en otros genera confusión.
- Abreviaturas ambiguas:Nombres cortos como «cust» o «ord» carecen de claridad para los nuevos miembros del equipo.
- Palabras reservadas:Usar palabras reservadas como nombres de tablas provoca errores de sintaxis en las consultas.
Una nomenclatura clara reduce la carga cognitiva para desarrolladores y administradores de bases de datos. También facilita la generación automática de documentación y reduce la probabilidad de errores tipográficos en las sentencias SQL.
Análisis de impacto de defectos comunes
| Defecto de diseño | Impacto técnico | Costo empresarial |
|---|---|---|
| Claves foráneas faltantes | Registros huérfanos, inconsistencia de datos | Pérdida de datos, violaciones de cumplimiento |
| Tipos de datos incorrectos | Waste de almacenamiento, errores de cálculo | Discrepancias financieras, errores en informes |
| Sobrenormalización | Rendimiento lento de consultas, alta latencia | Mala experiencia del usuario, pérdida de ingresos |
| Índices faltantes | Escaneos completos de tablas, contención de bloqueos en la base de datos | Tiempo de inactividad del sistema, mala escalabilidad |
| Mal nombre | Alto costo de mantenimiento, tasas de error | Tiempo de desarrollo aumentado, errores |
Estrategias de prevención 🛡️
Prevenir estas fallas requiere un enfoque disciplinado en el diseño de bases de datos. Los siguientes pasos ayudan a mitigar riesgos antes de la implementación.
- Revisiones entre pares: Realice revisiones obligatorias del esquema antes de que se fusionen cualquier cambio.
- Linting automatizado: Utilice herramientas para verificar convenciones de nombres y estándares estructurales.
- Documentación: Mantenga diagramas ERD actualizados que reflejen el esquema real.
- Pruebas: Ejecute pruebas de validación de esquema en el entorno de pruebas antes de la producción.
Adoptar un proceso de control de versiones para los esquemas de bases de datos garantiza que los cambios se rastreen y sean reversibles. Esto permite a los equipos identificar cuándo se introdujo una falla y deshacerla si es necesario. La colaboración entre desarrolladores y arquitectos es esencial para detectar problemas a tiempo.
Consideraciones de mantenimiento a largo plazo 🔄
Los esquemas de bases de datos evolucionan con el tiempo. Un diseño que funciona hoy puede no adaptarse a los requisitos futuros. Las auditorías regulares ayudan a identificar deuda técnica y patrones obsoletos.
- Desviación de esquema: Monitorear las diferencias entre el ERD y la base de datos en producción.
- Obsolescencia: Planificar la eliminación de tablas y columnas no utilizadas.
- Escalabilidad: Diseñar teniendo en cuenta la partición y el fraccionamiento para conjuntos de datos grandes.
Ignorar la mantenimiento lleva a un sistema frágil que resiste los cambios. La gestión proactiva asegura que la base de datos permanezca una fundación confiable para la aplicación. Invertir tiempo en el diseño inicial rinde dividendos a lo largo de todo el ciclo de vida del software.
Consideraciones finales sobre la integridad del esquema 📝
Los errores en la base de datos de producción a menudo son el resultado de detalles pasados por alto en la fase de diseño. Al abordar la cardinalidad, los tipos de datos, las restricciones y el índice, los equipos pueden construir sistemas más resilientes. El costo de corregir una falla en producción es significativamente mayor que prevenirla durante el modelado.
Enfóquese en la claridad, la consistencia y la validación. Un ERD bien estructurado es la columna vertebral de la confiabilidad de los datos. Priorice la calidad sobre la velocidad para garantizar la estabilidad a largo plazo. Este enfoque minimiza el riesgo y maximiza el valor de los datos almacenados dentro del sistema.