











En las arquitecturas de datos modernas, la velocidad con la que se recupera la información determina a menudo la usabilidad de una aplicación. Aunque las actualizaciones de hardware y las estrategias de caché desempeñan un papel importante, la base del rendimiento reside en la propia estructura de los datos. Específicamente, el diseño de los Modelos de Relaciones de Entidades (ERMs) determina con qué eficiencia un motor de base de datos puede recorrer, unir y agrupar datos. Un esquema optimizado no solo organiza la información; guía al optimizador de consultas hacia caminos de ejecución más rápidos. 📉
Esta guía explora los mecanismos técnicos detrás del diseño de esquemas y su correlación directa con el rendimiento de las consultas. Examinaremos cómo los niveles de normalización, la cardinalidad de las relaciones y las estrategias de indexación interactúan dentro del plan de ejecución de consultas. Al comprender estas dinámicas, los desarrolladores y arquitectos de bases de datos pueden construir sistemas que escalen sin comprometer la integridad ni la velocidad.
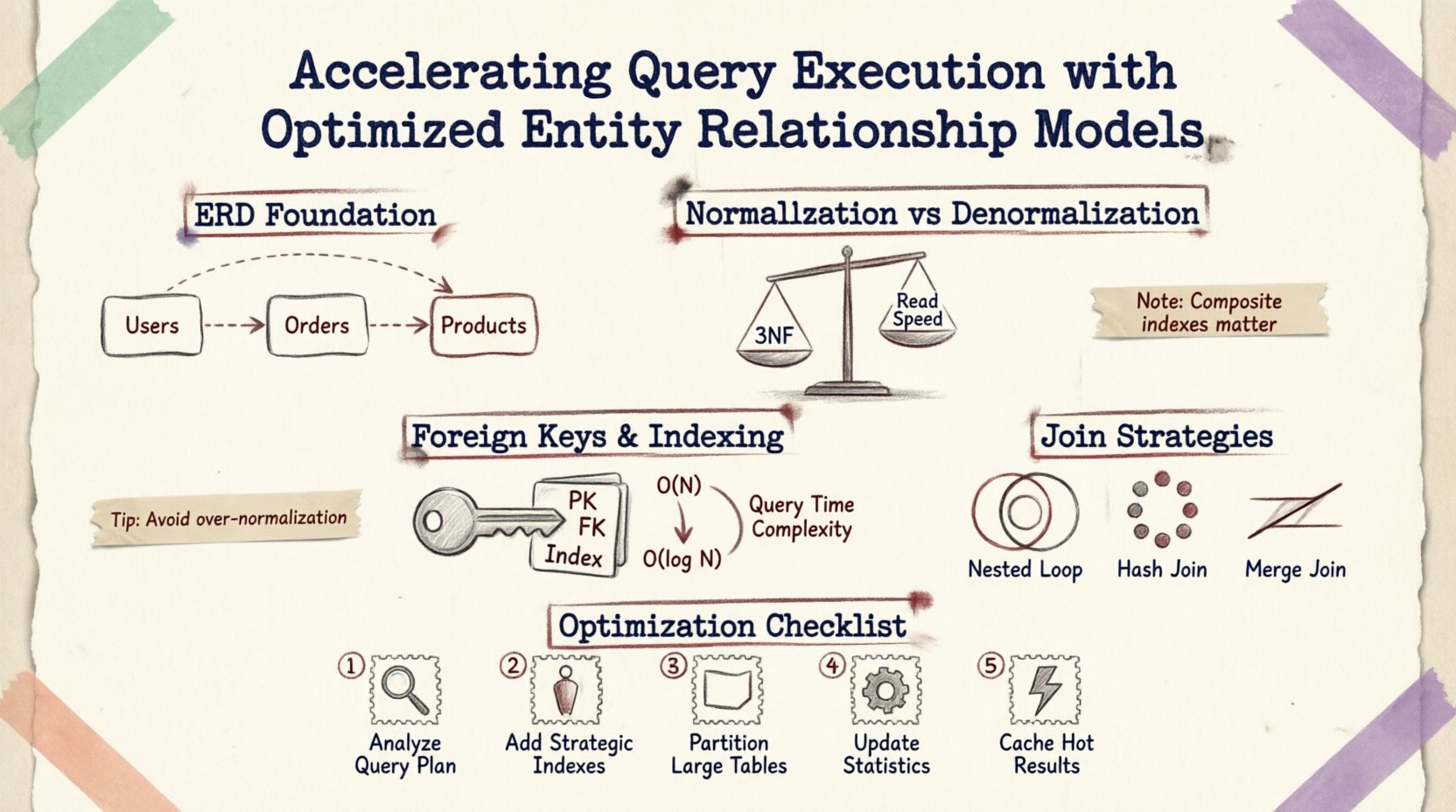
Entendiendo la base: ERDs y rendimiento 🗃️
Un Diagrama de Relaciones de Entidades es más que una ayuda visual para la documentación; es una plantilla para la lógica de almacenamiento físico y recuperación de datos. Cada línea trazada entre tablas representa una restricción de clave foránea, una operación de unión o una regla de integridad de datos. Cuando se envía una consulta, el motor de base de datos interpreta estas relaciones para construir un plan de ejecución.
Considere una consulta simple que solicita pedidos de usuarios y detalles de productos. El motor debe:
- Localizar la tabla
Usuariostabla. - Seguir la clave foránea hacia la tabla
Pedidostabla. - Unir la tabla
ElementosDePedidostabla. - Acceder a la tabla
Productostabla a través de otra relación.
Cada paso implica operaciones de E/S y ciclos de CPU. Si las relaciones están mal definidas, el motor puede recurrir a escaneos completos de tablas o uniones de bucles anidados que degradan el rendimiento exponencialmente. Optimizar el ERD reduce la distancia que los datos deben recorrer desde el disco hasta la memoria.
Normalización frente a denormalización: Encontrando el equilibrio ⚖️
La normalización es el proceso de organizar los datos para reducir la redundancia y mejorar la integridad. Aunque es esencial para la consistencia, una normalización excesiva puede fragmentar los datos en muchas tablas pequeñas, lo que requiere uniones complejas que ralentizan las operaciones intensivas de lectura.
El costo de la normalización profunda
Cuando un esquema se normaliza hasta la Tercera Forma Normal (3FN), los datos se almacenan en su estado más atómico. Esto minimiza el espacio de almacenamiento y las anomalías de actualización. Sin embargo, recuperar datos relacionados a menudo requiere recorrer múltiples claves foráneas.
- Sobrecarga de unión: Cada tabla adicional en una cadena de unión aumenta la complejidad del plan de consulta.
- Contención de bloqueos: Acceder a múltiples tablas aumenta la probabilidad de conflictos de bloqueo a nivel de fila.
- Uso de CPU: El motor de base de datos debe fusionar conjuntos de resultados de tablas distintas.
Cuándo denormalizar
La denormalización introduce redundancia para optimizar el rendimiento de lectura. Esto a menudo es necesario en procesamiento analítico o entornos de informes de alto tráfico.
- Cargas de trabajo con muchas lecturas: Si las escrituras son poco frecuentes en comparación con las lecturas, agregar una columna denormalizada ahorra operaciones de unión.
- Agregados precalculados: Almacenar totales (por ejemplo,
total_order_value) en la tabla de usuarios evita calcular sumas en cada solicitud. - Particionamiento horizontal: Mantener juntos los datos frecuentemente accedidos mejora la localidad de la caché.
Sin embargo, la denormalización requiere una gestión cuidadosa para evitar inconsistencias de datos. La lógica de la aplicación debe garantizar que los datos redundantes se actualicen cada vez que cambie la información de origen.
Claves foráneas y estrategia de indexación 🔑
Las restricciones de clave foránea garantizan la integridad referencial, pero conllevan un costo de rendimiento. La base de datos debe verificar que un valor en una tabla exista en otra antes de permitir una inserción o actualización. Optimizar cómo se indexan estas claves es fundamental.
Indexación de claves foráneas
Por defecto, las claves primarias se indexan automáticamente. Sin embargo, las claves foráneas a menudo requieren índices explícitos para acelerar las operaciones de unión. Sin un índice en una columna de clave foránea:
- La base de datos debe realizar un escaneo completo de la tabla secundaria para encontrar filas coincidentes.
- Las operaciones de unión se vuelven significativamente más lentas, especialmente cuando el tamaño de las tablas crece hasta millones de filas.
- Las comprobaciones de integridad referencial durante la eliminación se vuelven costosas.
Una clave foránea correctamente indexada permite que la base de datos utilice una búsqueda de índice en lugar de un escaneo, reduciendo la complejidad de O(N) a O(log N).
Índices compuestos para relaciones
Cuando múltiples columnas definen una relación, un índice compuesto puede ser más efectivo que índices individuales. Por ejemplo, si una consulta filtra por user_id y created_at dentro de una tabla de pedidos, un índice compuesto en ambas columnas garantiza que el motor pueda localizar los datos sin escanear registros no relacionados.
Estrategias de unión y planes de ejecución 🔍
La estructura del ERD influye en qué algoritmos de unión selecciona el optimizador de consultas. Comprender estas mecánicas ayuda a diseñar esquemas que favorezcan tipos de unión eficientes.
| Tipo de unión | Mejor utilizado cuando | Impacto en el rendimiento |
|---|---|---|
| Unión de bucle anidado | Conjuntos de resultados pequeños o predicados altamente selectivos | Rápido para datos pequeños; lento para escaneos grandes |
| Unión por hash | Tablas grandes sin índices | Intensivo en memoria; adecuado para datos no ordenados |
| Unión por fusión | Entradas ordenadas en las claves de unión | Muy rápido si los datos ya están ordenados |
Diseñar el ERD para apoyar entradas ordenadas o búsquedas indexadas puede incentivar al optimizador a elegir métodos de unión más rápidos. Por ejemplo, asegurarse de que las claves de unión se definan como parte de un índice agrupado puede facilitar las uniones por fusión.
Errores comunes en el diseño de esquemas 🚫
Incluso arquitectos experimentados cometen errores que afectan la velocidad de las consultas. Identificar estos patrones temprano evita reingenierías costosas más adelante.
- Claves foráneas encadenadas: Crear una cadena de relaciones donde la tabla A se vincula con B, B con C y C con D. Las consultas que unen las cuatro tablas se vuelven profundamente anidadas y lentas.
- Cadenas de longitud variable: Usando
VARCHARpara claves que siempre tienen longitud fija puede desperdiciar espacio y ralentizar las comparaciones de filas. - Muchos a muchos sin tablas de unión: Intentar almacenar múltiples IDs en una sola columna (por ejemplo, valores separados por comas) impide un índice adecuado y la normalización.
- Conversiones implícitas: Definir tipos de datos que no coinciden entre tablas padre e hija obliga al motor a convertir valores en tiempo de ejecución, impidiendo el uso de índices.
Pasos prácticos para la optimización 🛠️
Para mejorar la ejecución de consultas sin reescribir todo el sistema, siga estos pasos estructurados:
- Analizar patrones de consulta: Revise las operaciones de lectura más frecuentes. Identifique qué tablas se unen con mayor frecuencia.
- Revisar el uso de índices: Verifique la ausencia de índices en claves foráneas o columnas frecuentemente filtradas.
- Refinar la cardinalidad: Asegúrese de que las relaciones se modelen con precisión (uno a uno frente a uno a muchos). Una cardinalidad incorrecta puede provocar uniones innecesarias.
- Particionar tablas grandes: Si una tabla supera los millones de filas, considere la partición por fecha o región para limitar los datos escaneados por consulta.
- Monitoreo de bloqueos: Utilice herramientas de monitoreo para identificar consultas de larga duración que mantienen bloqueos, a menudo causados por recorridos ineficientes del esquema.
Consideraciones de almacenamiento y memoria 💾
La disposición física de los datos también tiene un papel importante. Los motores de bases de datos almacenan datos en páginas. Si las filas relacionadas se almacenan físicamente cerca unas de otras, se requieren menos lecturas de disco para cargar un conjunto de datos.
- Agrupamiento:Organizar los datos por una clave común puede mejorar las búsquedas por rango.
- Almacenamiento por columnas frente a almacenamiento por filas:Para consultas analíticas, el almacenamiento por columnas puede ofrecer una mejor compresión y una agregación más rápida que los modelos tradicionales basados en filas.
- Caché:Diseñe esquemas que permitan una caché eficaz de conjuntos de resultados completos en lugar de filas individuales.
Consideraciones finales sobre la evolución del esquema 🔄
El diseño de esquemas no es una tarea única. A medida que cambian los requisitos de la aplicación, el modelo de datos debe evolucionar. Auditar regularmente la estructura de la base de datos asegura que el rendimiento permanezca consistente. La documentación del modelo de relaciones de entidades debe mantenerse junto con el código fuente para rastrear cómo los cambios afectan al sistema.
Al centrarse en la integridad estructural y las relaciones lógicas dentro de los datos, crea una base que respalda la ejecución de consultas de alta velocidad. El objetivo no es construir un sistema estático, sino una arquitectura flexible que se adapte a la carga sin sacrificar la velocidad que los usuarios esperan. 📊
Optimizar el modelo de relaciones de entidades es una disciplina técnica que combina la teoría de bases de datos con la ingeniería práctica. Requiere paciencia, análisis y una comprensión clara de cómo el motor subyacente procesa las solicitudes. Con el enfoque adecuado, los problemas de rendimiento se vuelven manejables y la recuperación de datos se vuelve fluida.