











Diseñar una arquitectura de datos sólida requiere más que dibujar cajas y líneas. Exige una comprensión profunda de cómo fluye, crece y se interrelaciona la información con el tiempo. Cuando un sistema escala, el modelo de relación de entidades (ERD) sirve como plano para la consistencia lógica, mientras que las estrategias de particionado abordan el rendimiento físico. Alinear estos dos aspectos es fundamental para mantener la velocidad de las consultas, la integridad de los datos y la eficiencia operativa. Esta guía explora cómo armonizar las técnicas de particionado con sus modelos de datos existentes sin introducir complejidad o riesgos innecesarios.
🧩 La base: el ERD como plano
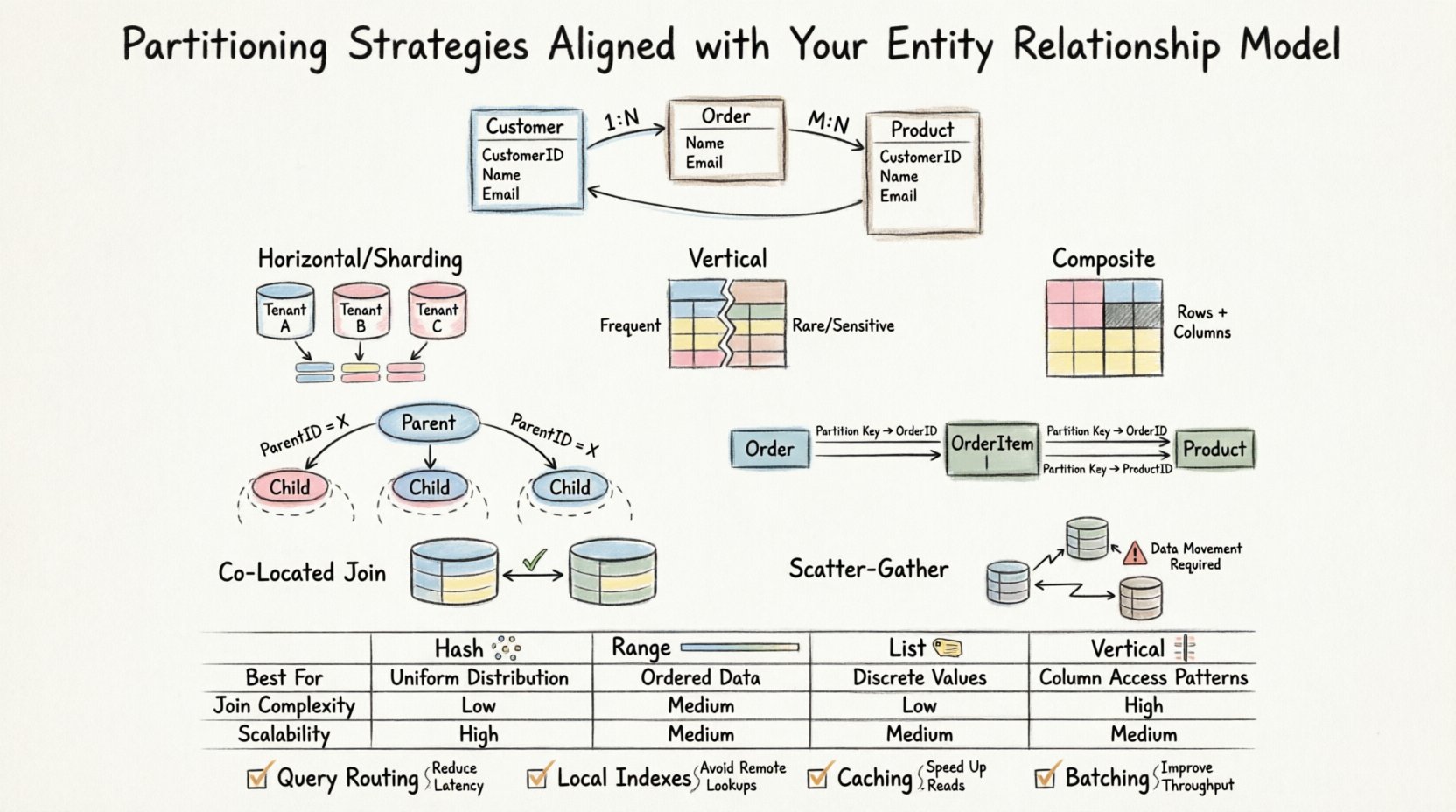
Antes de considerar cómo dividir los datos, uno debe comprender las relaciones que los unen. Un ERD define entidades, atributos y la cardinalidad entre ellos. Estas relaciones determinan cómo se recuperan y unen los datos. Cuando se introduce el particionado, en esencia se distribuyen estas relaciones lógicas a través de los límites físicos de almacenamiento.
Considere las siguientes implicaciones del particionado en su esquema:
- Claves primarias: Deben elegirse con cuidado para garantizar una distribución equilibrada entre las particiones.
- Claves foráneas:Unir tablas en particiones diferentes puede generar una sobrecarga significativa.
- Índices:Los índices globales pueden convertirse en cuellos de botella si no se diseñan teniendo en cuenta la clave de partición.
- Localización de datos:Los datos relacionados deberían residir idealmente en el mismo nodo para minimizar la latencia de red.
Ignorar estos factores puede llevar a una situación en la que el modelo lógico funciona perfectamente en el diseño, pero la implementación física tiene dificultades bajo carga. El objetivo es mantener los datos relacionados cerca entre sí, al tiempo que se permite un crecimiento independiente.
🔄 Tipos de particionado y ajuste al esquema
Los diferentes métodos de particionado se adaptan a diferentes patrones de acceso a datos. Elegir el método adecuado depende en gran medida de cómo su ERD define las relaciones y los patrones de consulta esperados. A continuación se presenta un análisis de las estrategias comunes y cómo interactúan con las estructuras relacionales.
Particionado horizontal (sharding)
El particionado horizontal divide las filas de una tabla en grupos diferentes. Suele usarse cuando las tablas se vuelven demasiado grandes para gestionarlas en una sola instancia. En el contexto de un ERD, esta estrategia funciona mejor cuando la clave de partición se correlaciona con el patrón de acceso natural.
- Caso de uso:Tablas transaccionales grandes con grupos de usuarios o inquilinos distintos.
- Impacto en el ERD:Las claves foráneas que apuntan a una tabla padre deben gestionarse con cuidado. Si la tabla padre también está particionada, las claves deben alinearse.
- Beneficio:Permite una escalabilidad masiva al agregar más nodos.
- Desafío:Las consultas complejas que abarcan múltiples particiones requieren lógica de agregación.
Particionado vertical
El particionado vertical divide las columnas de una tabla en grupos diferentes. Es útil cuando columnas específicas rara vez se acceden juntas o cuando se necesita aislar datos sensibles.
- Caso de uso:Tablas con filas anchas donde solo un subconjunto de columnas se consulta con frecuencia.
- Impacto en el ERD: La clave primaria debe existir en todas las particiones verticales para permitir la reconstrucción de la fila completa.
- Beneficio: Reduce la I/O cargando únicamente las columnas necesarias en la memoria.
- Desafío: Se requieren combinaciones para reconstruir la entidad completa, lo que aumenta la complejidad de la consulta.
Particionamiento compuesto
Este enfoque combina estrategias horizontales y verticales. Es frecuentemente necesario en sistemas de alto rendimiento donde tanto el volumen de filas como el ancho de columnas son restricciones significativas.
- Caso de uso:Almacenamiento de datos o registros de trading de alta frecuencia.
- Impacto en el ERD: Requiere una definición rígida del esquema antes de la implementación.
🔑 Alineación de claves con relaciones
El paso más crítico en este proceso es seleccionar la clave de partición. Esta clave determina qué fila va a qué unidad de almacenamiento física. En un contexto relacional, la clave de partición debería ajustarse idealmente a las relaciones de clave foránea.
Relaciones padre-hijo
Cuando se manejan relaciones uno-a-muchos, la tabla hija suele crecer mucho más rápido que la tabla padre. Si particionas la tabla hija por el ID del padre, todos los registros hijos relacionados residirán en el mismo nodo.
- Ventaja: Las consultas que recuperan el padre y todos los hijos no requieren comunicación entre nodos.
- Ventaja: Las eliminaciones se propagan de forma eficiente dentro de una sola partición.
- Advertencia: Si un padre tiene significativamente más hijos que otros, puede ocurrir un sesgo de datos.
Relaciones muchos-a-muchos
Las relaciones muchos-a-muchos suelen implicar una tabla de unión. Esta tabla puede convertirse en un cuello de botella de rendimiento si no se particiona correctamente.
- Estrategia: Particionar por una de las claves foráneas involucradas.
- Estrategia: Asegúrate de que las consultas siempre filtren por la clave de partición para evitar escaneos completos de tabla.
- Estrategia: Evita unir tablas de unión entre múltiples particiones a menos que sea absolutamente necesario.
⚖️ Manejo de operaciones de unión
Las uniones son la columna vertebral de las bases de datos relacionales, pero se vuelven costosas cuando los datos están divididos. Comprender cómo se comportan las uniones entre particiones es esencial para mantener el rendimiento.
Particiones co-localizadas
Si la tabla A y la tabla B están particionadas por la misma clave (por ejemplo, Tenant_ID), la unión entre ellas se realiza localmente. El motor de base de datos no necesita mover datos entre nodos.
- Requisito:Ambas tablas deben utilizar el mismo algoritmo y clave de partición.
- Requisito:El diagrama ERD debe respaldar esta alineación lógicamente.
Uniones de dispersión-recuperación
Cuando las tablas están particionadas de manera diferente, el sistema debe obtener datos de múltiples nodos, agrupar los resultados y luego devolver el conjunto final. Esto se conoce como una operación de dispersión-recuperación.
- Costo de rendimiento:Alto sobrecargo de red.
- Costo de rendimiento:Latencia aumentada.
- Recomendación:Minimice estas uniones en la fase de diseño del diagrama ERD.
🛡️ Mantenimiento de la integridad entre particiones
Las restricciones de integridad de datos son más difíciles de aplicar cuando los datos están distribuidos. El diagrama ERD define estas reglas de forma lógica, pero la implementación debe manejar la distribución física.
- Integridad referencial:Asegurar que exista un registro hijo antes de insertar un registro padre es complejo si se encuentran en nodos diferentes.
- Restricciones únicas:La unicidad global requiere coordinación entre todas las particiones.
- Disparadores:Los disparadores a nivel de aplicación a menudo reemplazan a los disparadores a nivel de base de datos en entornos distribuidos para evitar problemas de bloqueo.
- Transacciones:Las transacciones distribuidas pueden afectar el rendimiento. Mantenga las transacciones locales a una sola partición siempre que sea posible.
📊 Comparación de estrategias de partición
La siguiente tabla resume cómo interactúan diferentes estrategias con escenarios comunes del diagrama ERD.
| Estrategia | Mejor para el escenario del diagrama ERD | Complejidad de unión | Escalabilidad de escritura |
|---|---|---|---|
| Particionamiento por hash | Se necesita una distribución uniforme, sin rango específico | Alta (distribución aleatoria) | Alta |
| Particionamiento por rango | IDs basados en fecha o secuenciales | Baja (si está alineada) | Media |
| Particionamiento por lista | Categorías fijas (por ejemplo, Región, Estado) | Baja (si está alineada) | Alta |
| Particionamiento vertical | Filas anchas, columnas poco frecuentes | Media (requiere reconstrucción) | Alta |
🔄 Evolución y migración
La evolución del esquema es inevitable. Los requisitos del negocio cambian y se agregan nuevos atributos. Al modificar un diagrama ERD, se debe revisar la estrategia de particionamiento.
- Agregar columnas:El particionamiento vertical facilita agregar columnas, ya que pueden colocarse en una nueva partición.
- Cambiar claves:Volver a particionar los datos existentes es una operación pesada. Planifíquelo durante el diseño inicial.
- Archivado:El particionamiento permite archivar fácilmente rangos de datos antiguos sin afectar a las particiones activas.
- Monitoreo:Verifique periódicamente el tamaño de las particiones para asegurarse de que ninguna partición se convierta en un cuello de botella.
🚀 Consejos de optimización de rendimiento
Para garantizar que el sistema permanezca reactivo, se deben aplicar optimizaciones específicas junto con la estrategia de particionamiento.
- Enrutamiento de consultas:Asegúrese de que las aplicaciones envíen consultas al nodo de partición correcto según la clave de partición.
- Indexación:Los índices locales son más rápidos que los índices globales. Diseñe los índices para que coincidan con la clave de partición.
- Caché:Las tablas de búsqueda de acceso frecuente no deben particionarse si son lo suficientemente pequeñas como para caber en la memoria de todos los nodos.
- Agrupación:Agrupe inserciones y actualizaciones para reducir la sobrecarga de transacciones entre particiones.
🔍 Consideraciones finales
Construir un sistema que se escala requiere equilibrar la claridad lógica con las limitaciones físicas. El modelo entidad-relación proporciona las reglas para la consistencia de los datos, mientras que la partición proporciona el mecanismo para el crecimiento. Cuando ambas se alinean, el sistema mantiene un rendimiento óptimo incluso cuando el volumen de datos aumenta exponencialmente.
Enfóquese en las relaciones definidas en su modelo. Si los datos se agrupan naturalmente por un atributo específico, utilice ese atributo como clave de partición. Si las uniones son frecuentes, asegúrese de que las tablas relacionadas compartan la misma lógica de partición. Evite complicar innecesariamente el esquema con particiones que no cumplan un propósito de rendimiento claro.
Al adherirse a estos principios, crea una base que respalda la estabilidad a largo plazo. El objetivo no es solo almacenar datos, sino estructurarlos de manera que el sistema pueda adaptarse a las demandas futuras sin requerir una reconstrucción completa. Una planificación cuidadosa durante la fase de diseño ahorra una gran cantidad de esfuerzo de ingeniería durante las operaciones.